经常会有人问这样的问题I have list of 10,000 Entrez IDs and i want to convert the multiple Entrez IDs into the respective gene names. Could someone suggest me the way to do this?等等类似的基因转换,能做的基因转换的方法非常多,以前不懂编程的时候,都是用各种网站,而最常用的就是ensembl的biomart了,它支持的ID非常多,高达几百种,好多ID我到现在都不知道是什么意思。
现在学会编程了,我比较喜欢的是R的一些包,是bioconductor系列,一般来说,其中有biomart,org.Hs.eg.db,annotate,等等。关于biomart我就不再讲了,我前面的博客至少有七八篇都提到了它。本次我们讲讲简单的, 我就以把gene entrez ID转换为gene symbol 为例子把。
当然,首先要安装这些包,并且加载。
if("org.Hs.eg.db" %in% rownames(installed.packages()) == FALSE) {source("http://bioconductor.org/biocLite.R");biocLite("org.Hs.eg.db")}
suppressMessages(library(org.Hs.eg.db)) 我比较喜欢这样加载包
library(annotate) #一般都是这样加载包
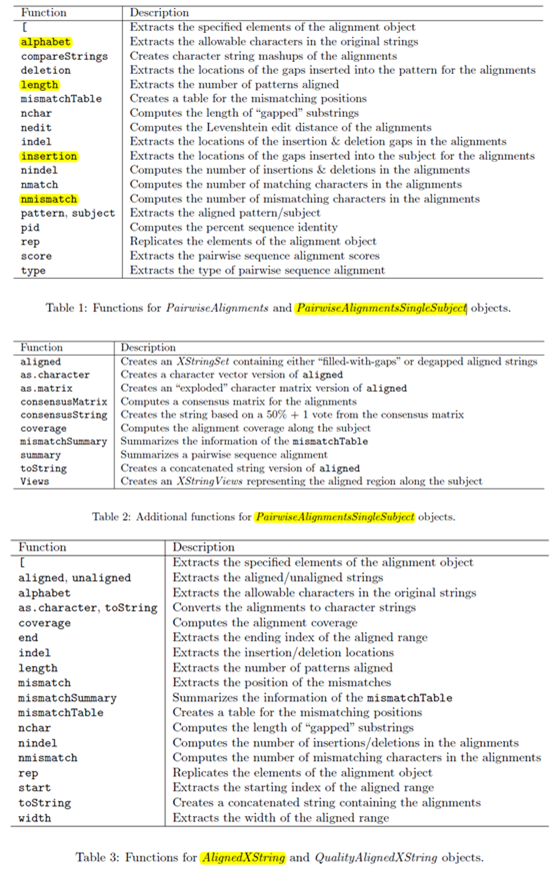
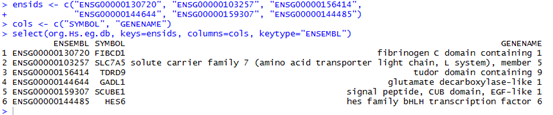
如果是用org.Hs.eg.db包,首先你只需要读取你的待转换ID文件,构造成一个向量,tmp,然后只需要symbols <- org.Hs.egSYMBOL[as.character(tmp)]就可以得到结果了,返回的symbols是一个对象,需要用toTable这个函数变成数据框。但是这样转换容易出一些问题,比如如果你的输入数据tmp,里面含有一些无法转换的gene entrez ID,就会报错。
而且它支持的ID转换很有限,具体看看它的说明书即可:https://www.bioconductor.org/packages/release/data/annotation/manuals/org.Hs.eg.db/man/org.Hs.eg.db.pdf
org.Hs.eg.db
org.Hs.eg_dbconn
org.Hs.egACCNUM
org.Hs.egALIAS2EG
org.Hs.egCHR
org.Hs.egCHRLENGTHS
org.Hs.egCHRLOC
org.Hs.egENSEMBL
org.Hs.egENSEMBLPROT
org.Hs.egENSEMBLTRANS
org.Hs.egENZYME
org.Hs.egGENENAME
org.Hs.egGO
org.Hs.egMAP
org.Hs.egMAPCOUNTS
org.Hs.egOMIM
org.Hs.egORGANISM
org.Hs.egPATH
org.Hs.egPMID
org.Hs.egREFSEQ
org.Hs.egSYMBOL
org.Hs.egUCSCKG
org.Hs.egUNIGENE
org.Hs.egUNIPROT
如果是用annotate包,首先你还是需要读取你的待转换ID文件,构造成一个向量,tmp,然后用getSYMBOL(as.character(tmp), data='org.Hs.eg')这样直接就返回的还是以向量,只是在原来向量的基础上面加上了names属性。说明书:http://www.bioconductor.org/packages/3.3/bioc/manuals/annotate/man/annotate.pdf
然后你可以把转换好的向量写出去,如下:
1 A1BG
2 A2M
3 A2MP1
9 NAT1
10 NAT2
12 SERPINA3
13 AADAC
14 AAMP
15 AANAT
16 AARS
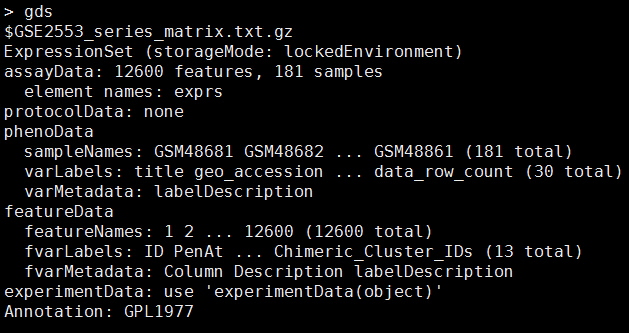
PS:如果是芯片数据,需要把探针的ID转换成gene,那么一般还需要加载特定芯片的数据包才行:
platformDB <- paste(eset.mas5@annotation, ".db", sep="") #这里需要确定你用的是什么芯片
cat("the annotation is ",platformDB,"\n")
if(platformDB %in% rownames(installed.packages()) == FALSE) {source("http://bioconductor.org/biocLite.R");tmp=try(biocLite(platformDB))}
library(platformDB, character.only=TRUE)
probeset <- featureNames(eset.mas5)
rowMeans <- rowMeans(exprSet)
library(annotate) # lookUp函数是属于annotate这个包的
EGID <- as.numeric(lookUp(probeset, platformDB, "ENTREZID"))