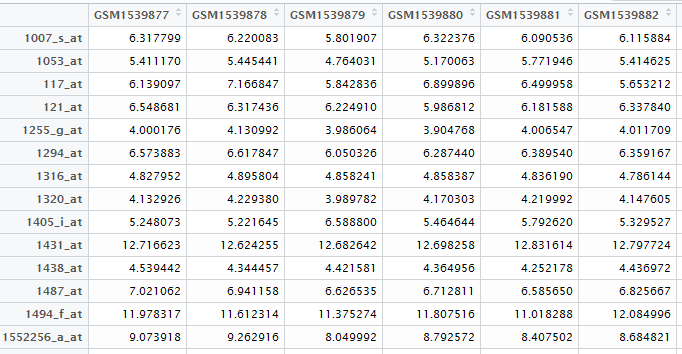
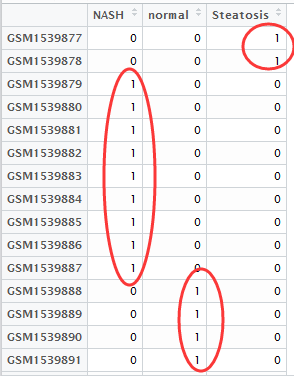
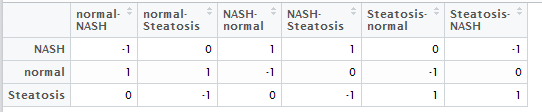
最流行的差异分析软件就是limma了,它现在更新了一个voom的算法,所以既可以对芯片数据,也可以对转录组高通量测序数据进行分析,其它所有的差异分析软件其实都是模仿这个的。
我以前讲到过做差异分析,需要三个数据:
前面两个肯定是必须的,有表达矩阵,样本必须进行分组,才能分析,但是我看到过好几种例子,有的有差异比较矩阵,有的没有。
后来我仔细研究了一下limma包的说明书,发现这其实是一个很简单的问题。
大家仔细观察下面的两个代码
首先是不需要差异比较矩阵的
library(CLL)
data(sCLLex)
library(limma)
design=model.matrix(~factor(sCLLex$Disease))
fit=lmFit(sCLLex,design)
fit=eBayes(fit)
options(digits = 4)
#topTable(fit,coef=2,adjust='BH')
> topTable(fit,coef=2,adjust='BH')
logFC AveExpr t P.Value adj.P.Val B
39400_at 1.0285 5.621 5.836 8.341e-06 0.03344 3.234
36131_at -0.9888 9.954 -5.772 9.668e-06 0.03344 3.117
33791_at -1.8302 6.951 -5.736 1.049e-05 0.03344 3.052
1303_at 1.3836 4.463 5.732 1.060e-05 0.03344 3.044
36122_at -0.7801 7.260 -5.141 4.206e-05 0.10619 1.935
36939_at -2.5472 6.915 -5.038 5.362e-05 0.11283 1.737
41398_at 0.5187 7.602 4.879 7.824e-05 0.11520 1.428
32599_at 0.8544 5.746 4.859 8.207e-05 0.11520 1.389
36129_at 0.9161 8.209 4.859 8.212e-05 0.11520 1.389
37636_at -1.6868 5.697 -4.804 9.355e-05 0.11811 1.282
然后是需要差异比较矩阵的
library(CLL)
data(sCLLex)
library(limma)
design=model.matrix(~0+factor(sCLLex$Disease))
colnames(design)=c('progres','stable')
fit=lmFit(sCLLex,design)
cont.matrix=makeContrasts('progres-stable',levels = design)
fit2=contrasts.fit(fit,cont.matrix)
fit2=eBayes(fit2)
options(digits = 4)
topTable(fit2,adjust='BH')
logFC AveExpr t P.Value adj.P.Val B
39400_at -1.0285 5.621 -5.836 8.341e-06 0.03344 3.234
36131_at 0.9888 9.954 5.772 9.668e-06 0.03344 3.117
33791_at 1.8302 6.951 5.736 1.049e-05 0.03344 3.052
1303_at -1.3836 4.463 -5.732 1.060e-05 0.03344 3.044
36122_at 0.7801 7.260 5.141 4.206e-05 0.10619 1.935
36939_at 2.5472 6.915 5.038 5.362e-05 0.11283 1.737
41398_at -0.5187 7.602 -4.879 7.824e-05 0.11520 1.428
32599_at -0.8544 5.746 -4.859 8.207e-05 0.11520 1.389
36129_at -0.9161 8.209 -4.859 8.212e-05 0.11520 1.389
37636_at 1.6868 5.697 4.804 9.355e-05 0.11811 1.282
大家运行一下这些代码就知道,两者结果是一模一样的。
而差异比较矩阵的需要与否,主要看分组矩阵如何制作的!
design=model.matrix(~factor(sCLLex$Disease))
design=model.matrix(~0+factor(sCLLex$Disease))
有本质的区别!!!
前面那种方法已经把需要比较的组做出到了一列,需要比较多次,就有多少列,第一列是截距不需要考虑,第二列开始往后用coef这个参数可以把差异分析结果一个个提取出来。
而后面那种方法,仅仅是分组而已,组之间需要如何比较,需要自己再制作差异比较矩阵,通过makeContrasts函数来控制如何比较!