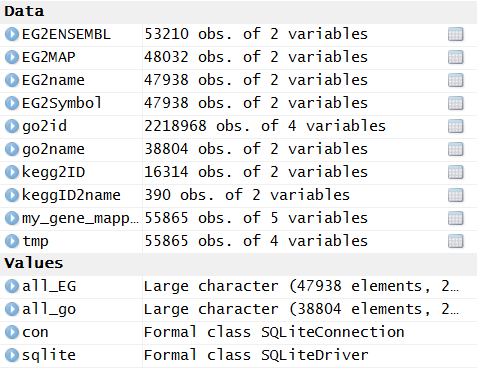
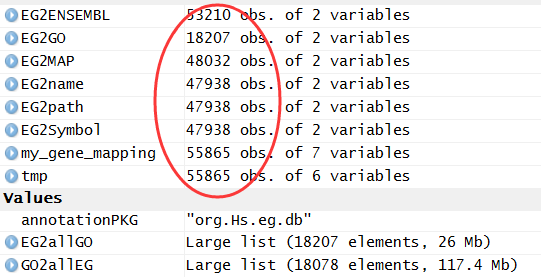
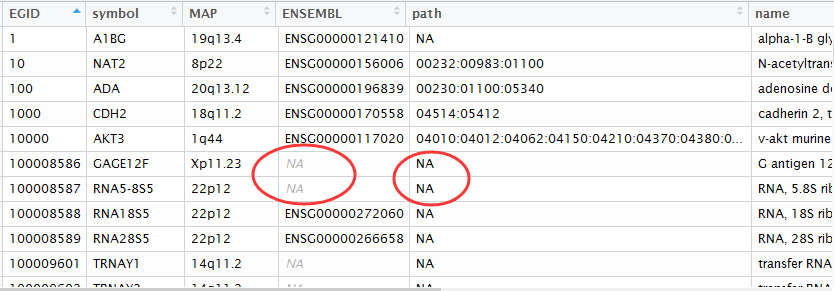
gpl organism bioc_package
1 GPL32 Mus musculus mgu74a
2 GPL33 Mus musculus mgu74b
3 GPL34 Mus musculus mgu74c
6 GPL74 Homo sapiens hcg110
7 GPL75 Mus musculus mu11ksuba
8 GPL76 Mus musculus mu11ksubb
9 GPL77 Mus musculus mu19ksuba
10 GPL78 Mus musculus mu19ksubb
11 GPL79 Mus musculus mu19ksubc
12 GPL80 Homo sapiens hu6800
13 GPL81 Mus musculus mgu74av2
14 GPL82 Mus musculus mgu74bv2
15 GPL83 Mus musculus mgu74cv2
16 GPL85 Rattus norvegicus rgu34a
17 GPL86 Rattus norvegicus rgu34b
18 GPL87 Rattus norvegicus rgu34c
19 GPL88 Rattus norvegicus rnu34
20 GPL89 Rattus norvegicus rtu34
22 GPL91 Homo sapiens hgu95av2
23 GPL92 Homo sapiens hgu95b
24 GPL93 Homo sapiens hgu95c
25 GPL94 Homo sapiens hgu95d
26 GPL95 Homo sapiens hgu95e
27 GPL96 Homo sapiens hgu133a
28 GPL97 Homo sapiens hgu133b
29 GPL98 Homo sapiens hu35ksuba
30 GPL99 Homo sapiens hu35ksubb
31 GPL100 Homo sapiens hu35ksubc
32 GPL101 Homo sapiens hu35ksubd
36 GPL201 Homo sapiens hgfocus
37 GPL339 Mus musculus moe430a
38 GPL340 Mus musculus mouse4302
39 GPL341 Rattus norvegicus rae230a
40 GPL342 Rattus norvegicus rae230b
41 GPL570 Homo sapiens hgu133plus2
42 GPL571 Homo sapiens hgu133a2
43 GPL886 Homo sapiens hgug4111a
44 GPL887 Homo sapiens hgug4110b
45 GPL1261 Mus musculus mouse430a2
49 GPL1352 Homo sapiens u133x3p
50 GPL1355 Rattus norvegicus rat2302
51 GPL1708 Homo sapiens hgug4112a
54 GPL2891 Homo sapiens h20kcod
55 GPL2898 Rattus norvegicus adme16cod
60 GPL3921 Homo sapiens hthgu133a
63 GPL4191 Homo sapiens h10kcod
64 GPL5689 Homo sapiens hgug4100a
65 GPL6097 Homo sapiens illuminaHumanv1
66 GPL6102 Homo sapiens illuminaHumanv2
67 GPL6244 Homo sapiens hugene10sttranscriptcluster
68 GPL6947 Homo sapiens illuminaHumanv3
69 GPL8300 Homo sapiens hgu95av2
70 GPL8490 Homo sapiens IlluminaHumanMethylation27k
71 GPL10558 Homo sapiens illuminaHumanv4
72 GPL11532 Homo sapiens hugene11sttranscriptcluster
73 GPL13497 Homo sapiens HsAgilentDesign026652
74 GPL13534 Homo sapiens IlluminaHumanMethylation450k
75 GPL13667 Homo sapiens hgu219
76 GPL15380 Homo sapiens GGHumanMethCancerPanelv1
77 GPL15396 Homo sapiens hthgu133b
78 GPL17897 Homo sapiens hthgu133a