本质上是使用发表在 Nat Methods. 2015 May;的CIBERSORT算法,对TCGA数据库的RNA-seq数据,计算并构建了一个数据库网页工具: The Cancer Immunome Atlas (https://tcia.at/) Continue reading
一
18
本质上是使用发表在 Nat Methods. 2015 May;的CIBERSORT算法,对TCGA数据库的RNA-seq数据,计算并构建了一个数据库网页工具: The Cancer Immunome Atlas (https://tcia.at/) Continue reading
RNA-seq数据毫无疑问是目前NGS领域被使用最频繁的了,但是大部分科研人员对它的理解,还停留在表达量层面,尤其是基于基因的表达量,无非就是分组,然后走差异分析这样的统计学检验,绘制火山图和差异基因热图,上下调的通路。
先不说大家对RNA-seq数据的标准分析是否一定是对的,这样的简陋的分析其实是对数据的暴殄天物! Continue reading
发表在Int J Clin Exp Pathol 2018;文章:Up-regulation of the IRX2 gene predicts poor prognosis in nasopharyngeal carcinoma
仅仅是医院收集了病人的随访时间,检测其中一个感兴趣基因的表达量,这样的汇总数据统计就可以发文章。 Continue reading
差异分析相信大家应该是都没有问题了,就是跟着我在生信技能树的教程走,当然也会有一些小细节需要注意,在 你确定你的差异基因找对了吗? 我很好的示范了部分细节。 Continue reading
最开始分享过芯片探针注释到基因名的3种方法:
- 1金标准当然是去基因芯片的厂商的官网直接去下载
- 2一种是直接用bioconductor的包
- 3一种是从NCBI里面下载文件来解析
见原文 Continue reading
GEO数据挖掘技巧,基本上该分享的都在B站和GitHub了,目录如下: Continue reading
发表在 Nat Methods. 2015 May;的文章,至今(2019-10-14)引用已经近1000啦,提出了一个非负矩阵分解的算法CIBERSORT根据LM22来计算不同类型细胞的比例。 Continue reading
RNA-seq标准分析,我们已经讲解的太多了,表达矩阵到差异分析等下游生物学注释都没有啥新颖之处,融合基因和可变剪切算是出彩的地方,如果加上GATK找变异流程就更棒了,反正都使用了star软件进行序列比对拿到bam文件了。 Continue reading
就是STAR-fusion啦,它可以直接基于STAR比对好的bam文件来做分析,而大多数其它融合基因查找工具,需要从fastq文件开始,不太方便。之前我在生信技能树公众号介绍过它,那个时候发表该工具的文章是:STAR-Fusion: Fast and Accurate Fusion Transcript Detection from RNA-Seq 在biorxiv预印本: Continue reading
最近一直在推送转录本差异相关的教程,见:每月一生信流程之rnaseqDTU(差异转录本) 扩充了大家对RNA-seq数据的理解,而且也指出来了,严格意义上的转录本定量其实是不容易的,对于二代测序来说:转录本定量本来就不是一件容易的事情 看留言,大家都深有同感! Continue reading
gtf文件大家都了解,基因或者外显子的坐标相对独立,但是转录本很不一样,同一个基因的不同转录本共用外显子,这样的话它们的坐标其实很多都是overlap的,这样,我们的二代测序的100bp或者150bp的reads就无法判定它到底属于哪一个转录本!(这个时候全长转录组测序(iso-seq)可能是更好的选择) Continue reading
最近走我整理和搭建好的:最新版针对RNA-seq数据的GATK找变异流程, 如果样本样品是正常运行,会输出: Continue reading
这是一个我也不知道该招聘什么样的人才的招聘通知!
生信技能树的粉丝都知道,**2019是我们的巡讲和宣讲元年**,是我们用实际行动来身体力行的推进生物信息学的发展,这一年我们从繁华的北上广深杭,一路狂奔到了祖国西南部的成都、重庆及西部的西安,从华北地区的天津、呼和浩特,再到华中地区的武汉、长沙、郑州,都有我们的身影! Continue reading
最近在移植一些科学界已经发表的网页小工具到我们生信技能树的服务器,发现很多工具都是依赖于rJava这个R包,在Ubuntu安装其实还是有一定的难度,所以分享一下! Continue reading
首先构建10x对象,这里就不赘述了,我在单细胞天地的2个教程:
因为计算某些基因含量这个需求实在是太常见了,所以特意设置了一个函数:PercentageFeatureSet
sce <- CreateSeuratObject(Read10X('../scRNA/filtered_feature_bc_matrix/'), "sce")
head(sce@meta.data)
GetAssayData(sce,'counts')
sce[["percent.mt"]] <- PercentageFeatureSet(sce, pattern = "^MT-")
VlnPlot(sce, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"), ncol = 3)
这样就可以可视化我们计算好的线粒体基因含量,下图可以看出需要最起码的过滤。
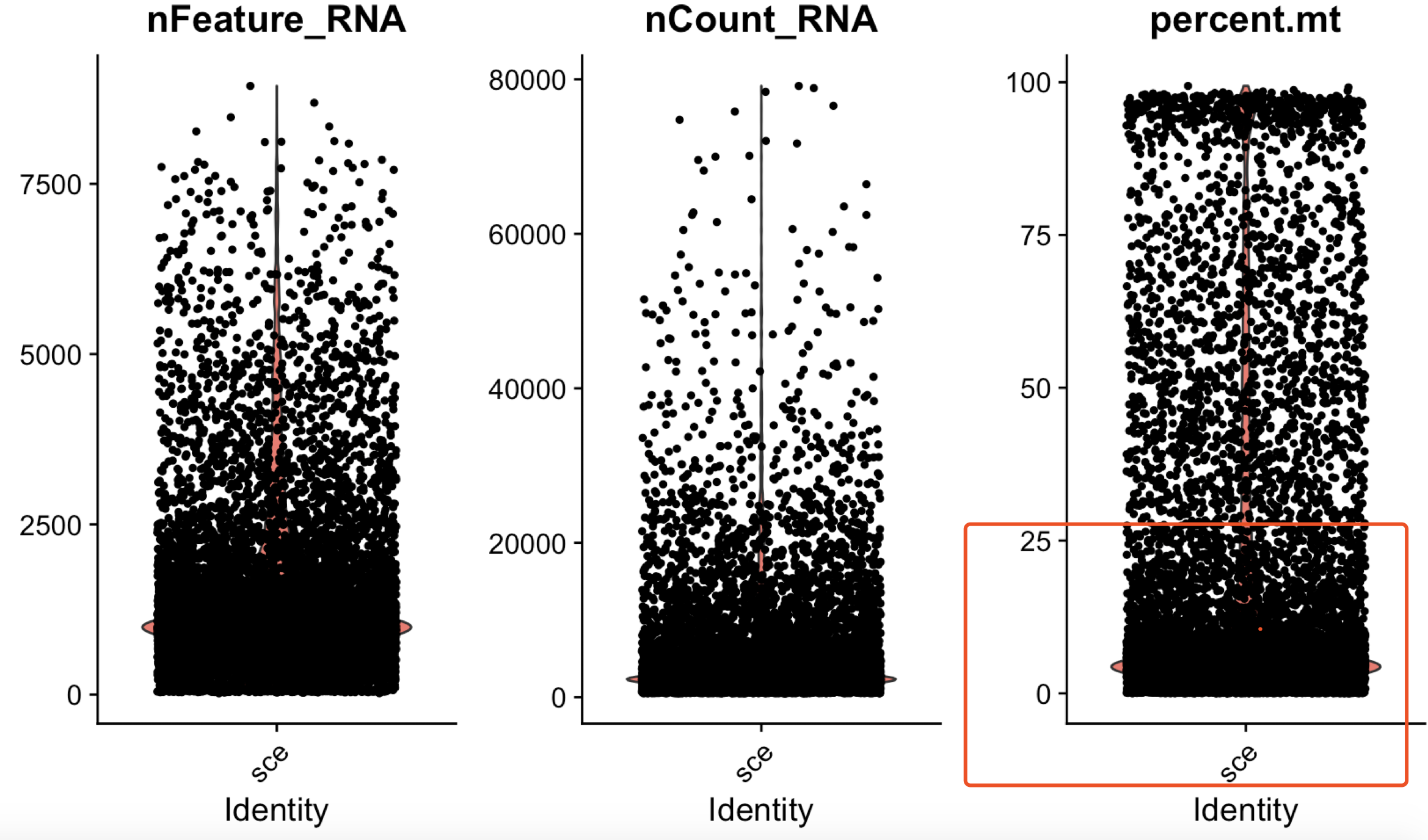
一般来说,这个过滤起码得是线粒体基因含量占比25%以下的细胞才保留,当然也得考虑到生物学课题啦。
上面的方法是修改 sce[[“percent.mt”]] ,下面我们演示 AddMetaData 函数,同样是可以增加线粒体基因含量信息到我们的seurat对象。
mt.genes <- rownames(sce)[grep("^MT-",rownames(sce))]
C<-GetAssayData(object = sce, slot = "counts")
percent.mito <- Matrix::colSums(C[mt.genes,])/Matrix::colSums(C)*100
sce <- AddMetaData(sce, percent.mito, col.name = "percent.mito")
sce[["percent.mito"]]
rb.genes <- rownames(sce)[grep("^RP[SL]",rownames(sce))]
percent.ribo <- Matrix::colSums(C[rb.genes,])/Matrix::colSums(C)*100
sce <- AddMetaData(sce, percent.ribo, col.name = "percent.ribo")
如下所示,可以看到部分细胞的核糖体基因含量也过高,至于过滤的指标,大家需要看文章啦!
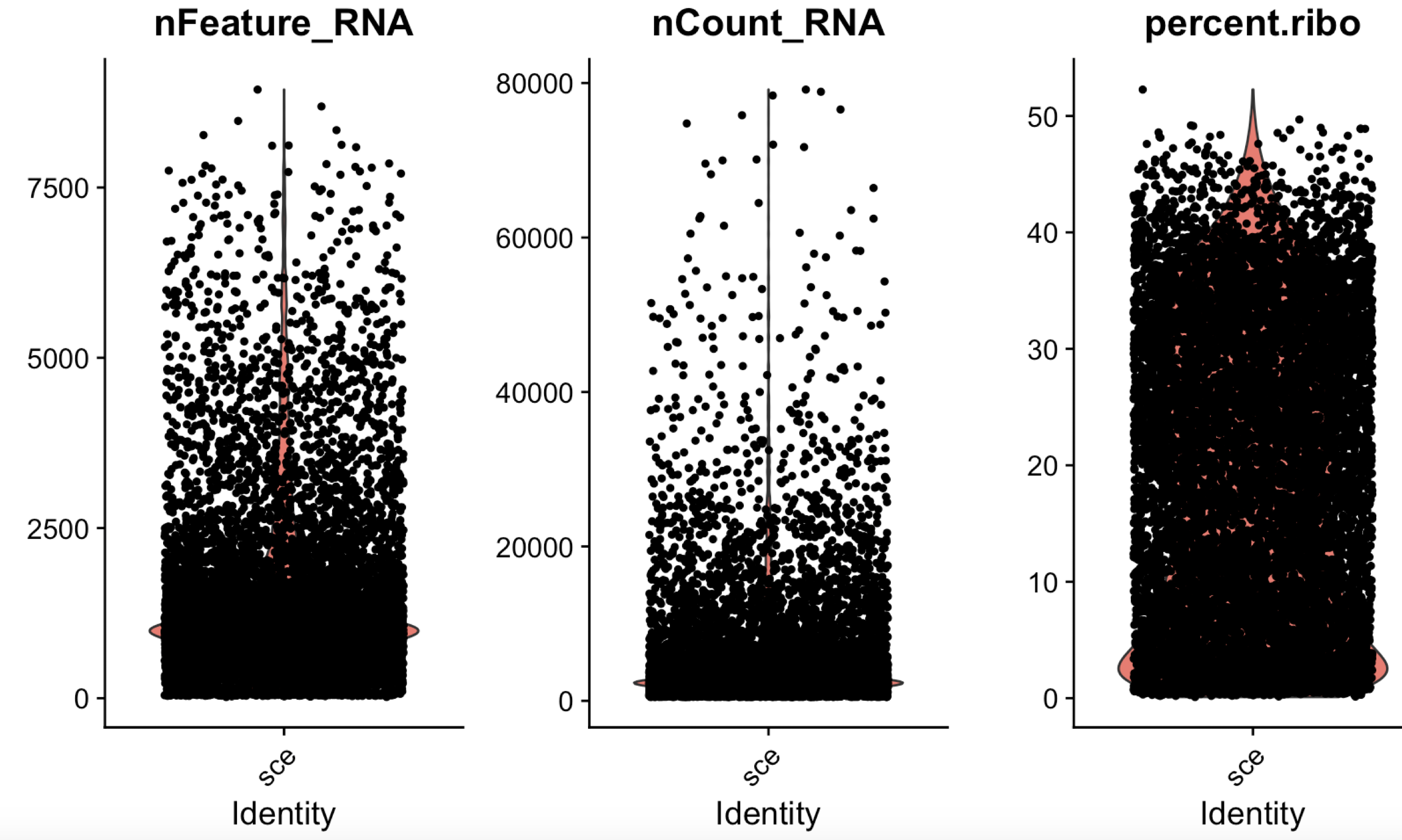
也可以是免疫球蛋白相关基因含量等等,取决于大家的生物学课题啦。
我在《生信分析人员如何系统入门Linux(2019更新版)》把Linux的学习过程分成6个阶段 ,提到过每个阶段都需要至少一天以上的学习: Continue reading
朋友圈医务工作者不少,经常看到各个疾病方向的义诊通知,各大城市均有,很佩服大家,而且我表示实名羡慕。虽然我不是学医的,但是也可以从另外一个层面帮助一下大家,我也来一个义诊,那就是我们生信技能树最擅长生物信息学方面的“义诊”啦! Continue reading