可以怎么说, 但凡是使用单细胞技术的科研课题,都是“幼儿园”水平,实验设计肯定是几十年前的甚至几百年前的,区别是N多年前大家是使用癌症和正常对照看其它技术指标,而现在大家看的单细胞指标,基本上都不会有科学含金量。大家拼的就是经费,燃烧吧广大劳动人民的血汗钱。
所以,现在很容易看到动辄几百个样品的单细胞课题,比如2021年初的来自中国39家研究所和医院的研究人员携手合作,深入分析了新冠病毒(SARS-CoV-2)感染后的免疫反应。他们对来自196例新冠肺炎(COVID-19)患者及对照的284个样本(总共146万个细胞)进行了单细胞RNA测序,发表于Cell主刊,题目为“COVID-19 immune features revealed by a large-scale singlecell transcriptome atlas**”。又或者是2023年9月的题为“An invasive zone in human liver cancer identified by Stereo-seq promotes hepatocyte–tumor cell crosstalk, local immunosuppression and tumor progression”的研究论文,利用Stereo-seq和scRNA-seq两种技术,其中仅仅是Stereo-seq就有共计98张切片,如果市场价5万,这个就是500万经费啦,当然了,真实收费可能是一两万就足够了,即使是这样的内部价也是一两百万科研经费哦。
在这样的“真枪实弹”拼样品数量的年代,能看到南京这个团队的:《Single cell transcriptomic analyses implicate an immunosuppressive tumor microenvironment in pancreatic cancer liver metastasis》文章算是一股清流,总共就4个病人,8个单细胞样品,不到6万的细胞数量,还能发NC,算是很了不起啦。
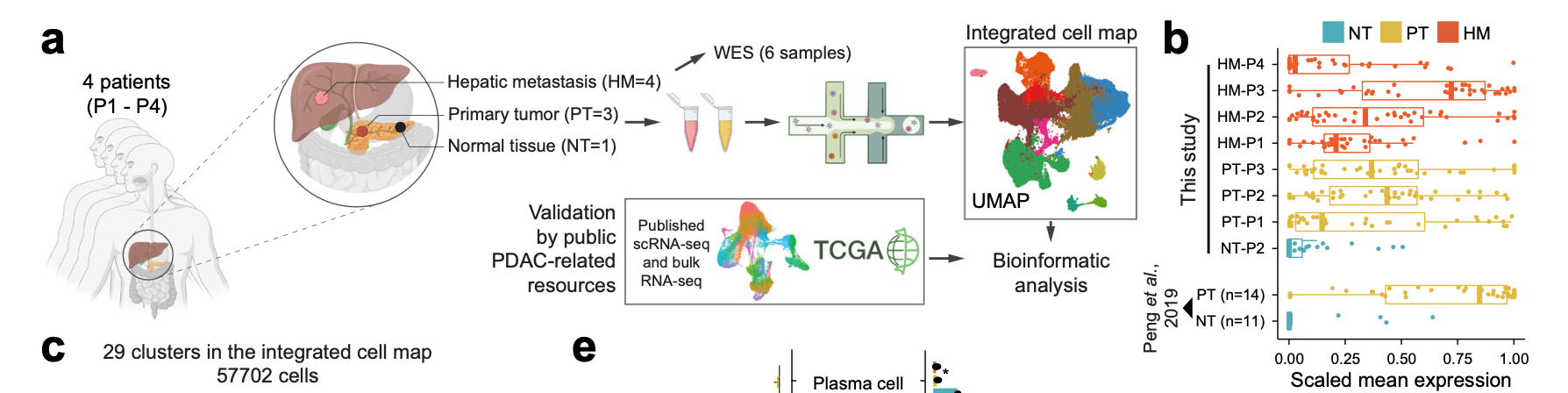
胰腺导管腺癌(Pancreatic ductal adenocarcinoma,PDAC)预后极差,大多数PDAC 患者的转移组织无法通过手术切除获得,这些研究只通过内镜超声引导下细针穿刺抽吸术 (endoscopic ultrasound-guided fineneedle aspiration,EUS- FNA) 收集有限的转移组织活检,所以样品数量很难上去。
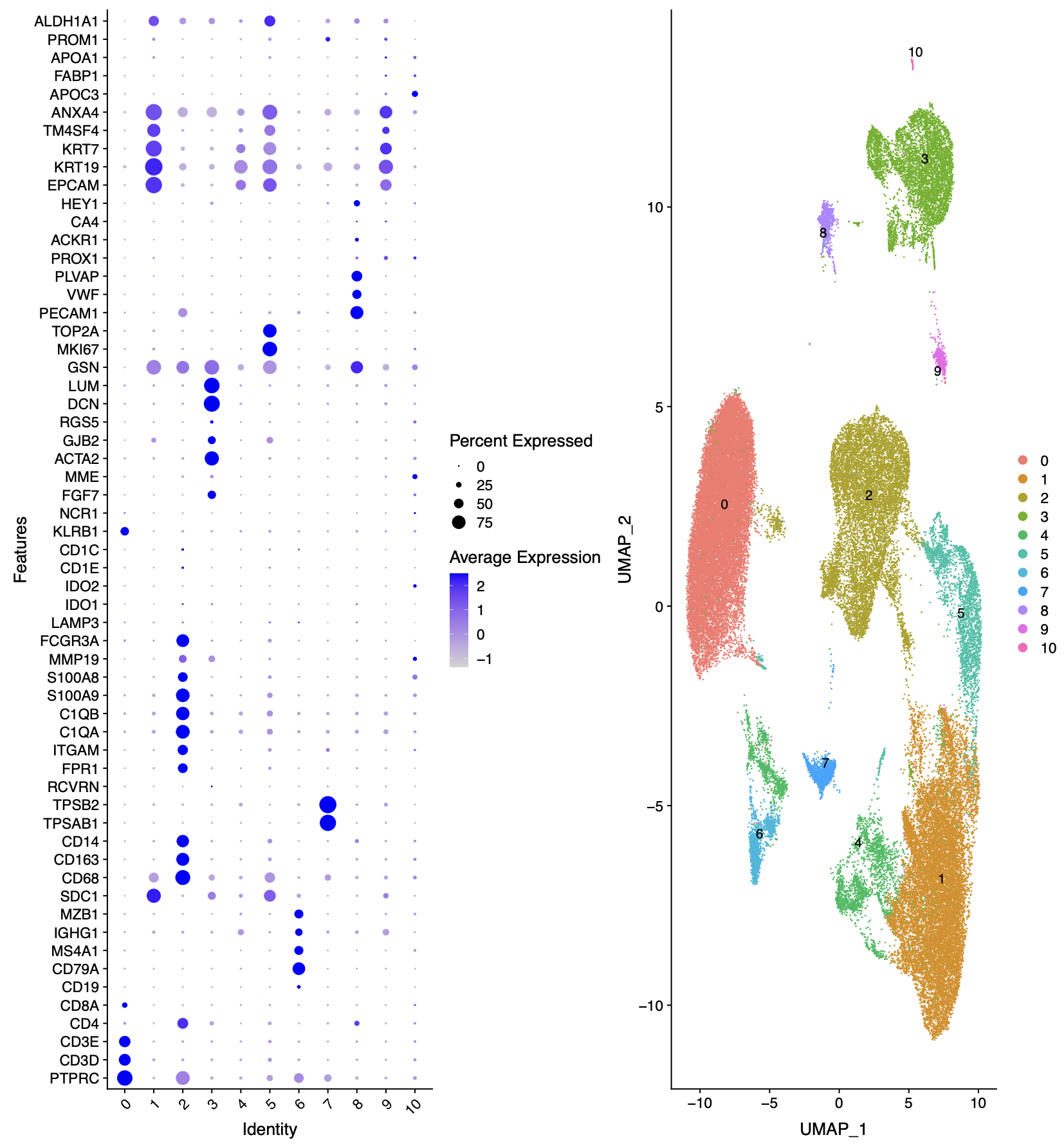
虽然说它的降维聚类分群确实有点丑,文章的数据集是公开的,很容易下载后读取,然后自己降维聚类分群:
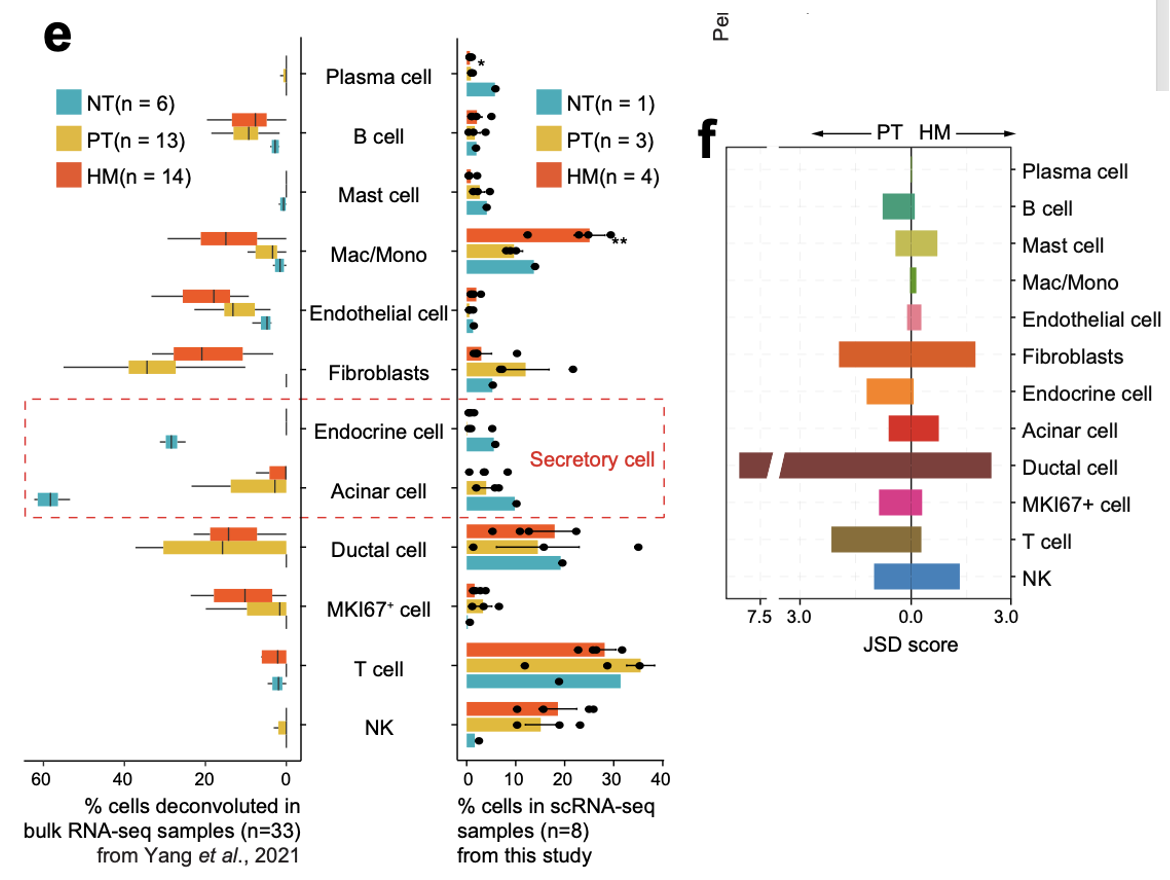
因为作者自己的样品数量实在是少得可怜,虽然说有三个分组:
- primary pancreatic tumors (PT)
- their respective paired hepatic metastases (HM),
- normal pancreatic tissue (NT)
所以很机智地纳入公共数据集: - Peng et al.’s dataset (including 11 NT and 14 PT samples)
- Yang et al.’ dataset (including 6 NT, 13 PT and 14 HM samples)
这样的话,不同分组单细胞比例才勉强可以对比一下寻找那些可能会有差异的单细胞亚群:
其它分析中规中矩
前面的不到6万个细胞走流程后,使用作者自己的参数可以拿到29个群后归类成:
- ductal cells
- T cells
- natural killer (NK) cells
- B cells
- mast cells
- plasma cells
- endothelial cells
- fibroblasts
- myeloid cells
- acinar cells
- endocrine cells
- MKI67+ cycling ductal cells
然后就是把每个单细胞亚群都细分即可,我们也讲解过。通常我们拿到了肿瘤相关的单细胞转录组的表达量矩阵后的第一层次降维聚类分群通常是: - immune (CD45+,PTPRC),
- epithelial/cancer (EpCAM+,EPCAM),
- stromal (CD10+,MME,fibro or CD31+,PECAM1,endo)
参考我前面介绍过 CNS图表复现08—肿瘤单细胞数据第一次分群通用规则,这3大单细胞亚群构成了肿瘤免疫微环境的复杂。绝大部分文章都是抓住免疫细胞亚群进行细分,包括淋巴系(T,B,NK细胞)和髓系(单核,树突,巨噬,粒细胞)的两大类作为第二次细分亚群。但是也有不少文章是抓住stromal 里面的 fibro 和endo进行细分,并且编造生物学故事的。
前面我们已经介绍了心肝脾肺肾等多个器官的上皮细胞的细分亚群, 以及免疫细胞里面的髓系和B细胞细分亚群: - B细胞细分亚群
- 髓系免疫细胞细分亚群
其中恶性的肿瘤上皮细胞细分可以作为单独的故事
The ductal cells were further divided into 6 subclusters through re-clusteringanalysis,including RPS3+,TFF1+, CEACAM6+, CEACAM5+, MALAT1+, and MKI67+ ductal cells, 如下所示:
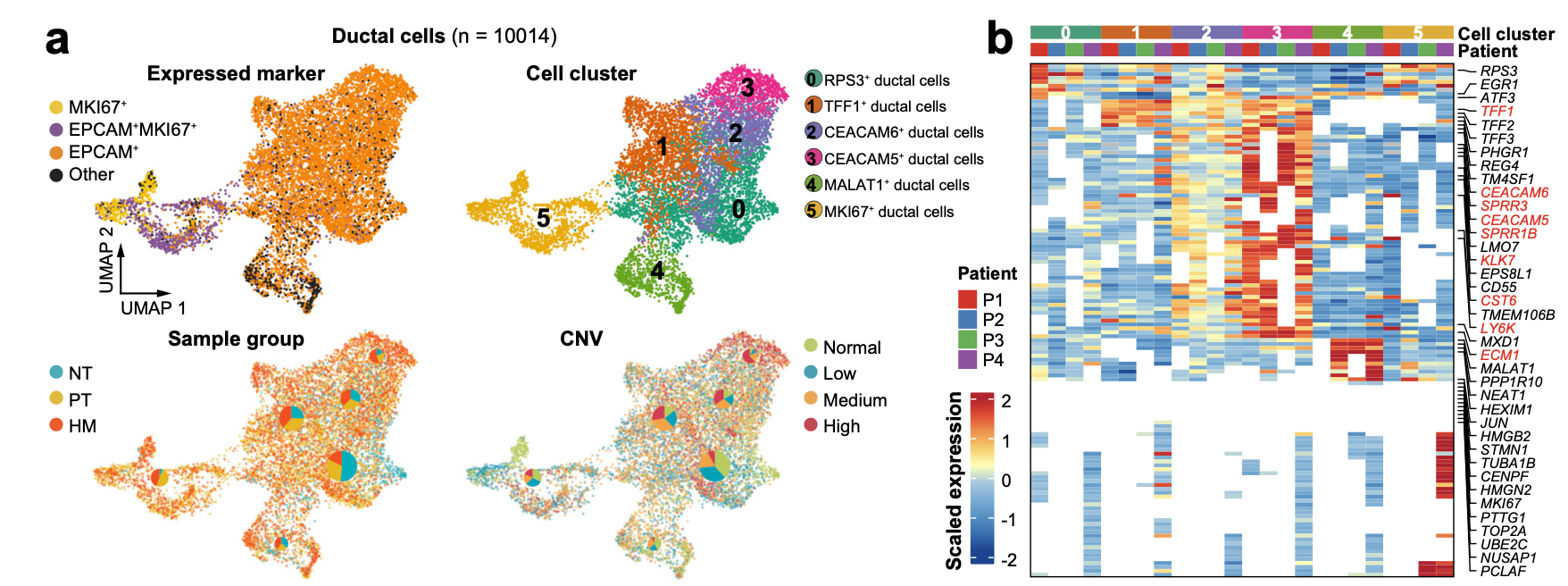
有一个新鲜出炉的单细胞数据挖掘文章是基于这个信息,文章是;《Single-cell RNA sequencing analysis revealed malignant ductal cell heterogeneity and prognosis signatures in pancreatic cancer》,其中 里面的 malignant cells were re-clustered into 4 distinct sub-clusters - S100A6 + cells (cluster 0 has 3310 cells),
- FXYD2+ cells (cluster 1 has 2194 cells)
- cluster 2 (141 cells)
- cluster 3 (68 cells),
其实任意癌症,都可以做类似的数据挖掘了,思路都是一模一样的: - 取交集拿到基因列表(单细胞特异性基因,差异分析基因,生存分析基因,wgcna基因)
- LASSO等机器学习建模
- 验证集看模型好坏
- 模型预测的风险分组后看其它组学(突变差异,甲基化差异,药物差异,免疫浸润差异)