如果我们想新开一个端口给别人访问,我们就需要设置防火墙,比如我想开3838端口给shiny程序使用,下面我重点讲解这个实例,其余开放端口,关闭端口大家继续学习就好。
如果你使用的是ssh远程,而又不能直接操作本机,那么建议你慎重,慎重,再慎重!(一旦你把22端口给搞死了,你就无法登陆你的服务器了!!!)
因为买过一个超算云服务器,所以前面我讲过Ubuntu服务器管理系列知识,正好最近要搞了个阿里云,用来做shiny服务器,发现服务器管理居然进化了好多,以前的知识都过时了,再记录一笔吧,真的是学习如逆水行舟,不进则退呀!
我的阿里云服务器版本是CentOS 6.5.,属于(RedHat 7, Ubuntu 15.04+, SLES 12+) 系列,是目前最新版本的服务器管理,所以大家重点是记住这个systemctl 即可:
我前面写到了生信分析人员如何入门linux和perl,后面还会写R和python的总结,但是在这中间我想插入一个脚本实战指南。其实在我前两篇日志里面也重点提到了学习编程语言最重要的就是实战了,也点出了几个关键词。在实际生物信息学数据处理中应用perl和linux,可以借鉴EMBOSS软件套件,fastx-toolkit等基础软件,实现并且模仿该软件的功能。尤其是SMS2/exonerate/里面的一些常见功能,还有DNA2.0 Bioinformatics Toolbox的一些工具。如果你这些名词不懂,请赶快谷歌!!! 它们做了什么,输入文件是什么,输出文件是什么,你都可以用脚本实现!
[[ ]] double brackets
(())Double parentheses
{{}}double curly brackets
我们必须要记住的是下面
[] 相当于test,作逻辑判断
$( ) 与` ` (反引号) 都是用来做命令替换用
${ } 吧... 它其实就是用来作变量替换用的啦
(())就是用来计算的,相当于expr函数。
http://tldp.org/LDP/abs/html/index.html
我们首先看看一对的括号
首先[]是用来逻辑判断的,必须有空格
if [ -f binom.py ]
then
echo 'binom.py exists'
fi
或者
nub=$((i%4))
#echo $nub
if [ $nub == 0 ];then
echo "we need to sleep 4 hours"
sleep 14000
fi
这个[]操作符等价于test函数
if test $1 -gt 0
then
echo "$1 number is positive"
fi
但是都必须有空格!!!
参考:http://www.freeos.com/guides/lsst/ch03sec02.html
关于shell的test操作符还有很多http://tldp.org/LDP/abs/html/fto.html
( ) 将command group 置于 sub-shell 去执行,也称 nested sub-shell。
{ } 则是在同一个 shell 内完成,也称为non-named command group。
补充一个: {} 还可以做变量扩展 {5..9} 或者 {abcd}e, 自己运行一下就知道效果啦
这两个差异很小,而且一般用不着,就不讲了。
那么这一对的括号加上了$符号后又变成了上面鬼东西呢?
当然,只有:$( ) 与${ }才是合法的。
在 bash shell 中,$( ) 与` ` (反引号) 都是用来做命令替换用(command substitution)的。
在操作上,用$( ) 或` ` 都无所谓,用$( )的优点是:
1, ` ` 很容易与' ' ( 单引号)搞混乱,尤其对初学者来说
2, 在多层次的复合替换中,` ` 须要额外的跳脱( \` )处理,而$( ) 则比较直观
再让我们看${ } 吧... 它其实就是用来作变量替换用的啦。
一般情况下,$var 与${var} 并没有啥不一样。
但是用${ } 会比较精确的界定变量名称的范围,比方说:
[code][/code]
$ A=B
$ echo $AB
还可以用来截取变量,这个就很多花样啦
# 是去掉左边(在鉴盘上# 在$ 之左边)
% 是去掉右边(在鉴盘上% 在$ 之右边)
单一符号是最小匹配﹔两个符号是最大匹配
然后我们看看两对的括号:
nub=$((i%4)) 等价于$nub=`expr $i % 1` ;
((i++)) 等价于$i=`expr $i + 1` ;
所以(())就是用来计算的,而且里面的变量不需要$来标记啦
(在 $(( )) 中的变量名称,可于其前面加$ 符号来替换,也可以不用)
在(())前面加上$只是为了把计算结果给保存而已。
而两个中括号和两个大括号都是不合法的!
刚才在知乎什么看到了一篇分享pacbio的数据特征,顺便看到了Minnesota大学的关于生物信息的教程的ppt合集,所以就想打包下载。
https://www.msi.umn.edu/tutorial-materials
这个网页里面有64篇pdf格式的ppt,还有几个压缩包,本来是准备写爬虫来爬去的,但是后来想了想有点麻烦,而且还不一定会看,反正也是玩玩
就用linux的命令行简单实现了这个爬虫功能。
curl https://www.msi.umn.edu/tutorial-materials >tmp.txt
perl -alne '{/(https.*?pdf)/;print $1 if $1}' tmp.txt >pdf.address
perl -alne '{/(https.*?txt)/;print $1 if $1}' tmp.txt
perl -alne '{/(https.*?zip)/;print $1 if $1}' tmp.txt >zip.address
wget -i pdf.address
wget -i pdf.zip
这样就可以啦!
教程ppt列表如下,大家有兴趣的可以自行下载浏览。
2009-04-22-mrm-presentation_0.pdf Matlab_viz_image_UMR.pdf
Analyzing ChIP at the command line.pdf MaxQuant_Introduction_112409.pdf
Analyzing ChIP using Galaxy.pdf Maxquant-step-by-step_rs091124.pdf
Badalamenti_PacBio_tutorial_12-10-2014.pdf MSI Applications Catalog Oct 21 MB slides.pdf
basics_chip_seq.pdf MSIIntro2013Jun18.pdf
Best_Practices_GATK_Variant_Detection_v1_0.pdf MSIIntroBMEN5311.pdf
blast2go.pdf MSI_Workshop_for_Introduction_to_Structure_based_Drug_Design.pdf
ClinProTools_0.pdf MTLB_GPUs.pdf
CUDA_Programming.pdf OpenMP.tutorial_1.pdf
cuda_tutorial_performance.pdf Open_Source_Proteomics_1.pdf
FLUENT_2009April21_final.pdf OptimizingWithGA.pdf
FLUENT_tutorial_2008aug14fin.pdf Orbi_Data_Analysis_092811.pdf
galaxy_101_V4_ljm_0.pdf Partek Training Handout_miRNA and mRNA Data Analysis.pdf
GPU_tools.pdf PerformanceTuning_itasca_11_27_12_0.pdf
gpututorial-msi.pdf PETSc_Tutorial.pdf
Hands_On_Tutorial_Using_ProTIP.pdf Phi_Intro.pdf
Introduction to MSI Systems.pdf Protein_Grouping_FDR_Analysis_and_Database_Pratik_March2012_Draft.pdf
Introduction_to_PEAKS_0.pdf Proteomics_MSI_072309_Print.pdf
Introduction_to_SBDD.pdf pymol_v5.pdf
IntroMPI2011july19c.pdf QC_illumina_galaxy_V1_ljm.pdf
IntroMPI2012_July25-part1.pdf Quality Control of Illumina Data at the Command Line.pdf
IntroMSI2014.pdf remotevisualization.pdf
IntroNWChem.pdf RISS_Hsapiens_variant_Detection_v3.0-small.pdf
IntroOpenMP_2011jun28b.pdf RNA_seq_Lecture2_2014_v2.pdf
Intro_to_GAMESS.pdf RNA-Seq mod1v6.pdf
IntroToGaussian09.pdf R_Spring2012_ver2.pdf
introtomolpro.pdf SchrodingerTutorial2011.pdf
Intro_to_MSI_Physicists.pdf Sybyl.pdf
intro-to-perl.pdf Tutorial-Hsap-v15.pdf
Matlab_11_29_UMR.pdf Tutorial-Stuber-v12-1.pdf
Matlab_PCT.pdf unix2013.6.18.pdf
MATLAB_Tuning.pdf WRKSP_2_19.pdf
Total wall clock time: 40m 22s
Downloaded: 64 files, 249M in 40m 2s (106 KB/s)
我都已经下载好了,打包压缩到群里面啦!
因为要讲搜索,所以我选择了一个长一点的字符串来演示多种情况的搜索
perl rotation_one_by_one.pl atgtgtcgtagctcgtnncgt
程序运行的结果如下
$ATGTGTCGTAGCTCGTNNCGT 21
AGCTCGTNNCGT$ATGTGTCGT 9
ATGTGTCGTAGCTCGTNNCGT$ 0
CGT$ATGTGTCGTAGCTCGTNN 18
CGTAGCTCGTNNCGT$ATGTGT 6
CGTNNCGT$ATGTGTCGTAGCT 13
CTCGTNNCGT$ATGTGTCGTAG 11
GCTCGTNNCGT$ATGTGTCGTA 10
GT$ATGTGTCGTAGCTCGTNNC 19
GTAGCTCGTNNCGT$ATGTGTC 7
GTCGTAGCTCGTNNCGT$ATGT 4
GTGTCGTAGCTCGTNNCGT$AT 2
GTNNCGT$ATGTGTCGTAGCTC 14
NCGT$ATGTGTCGTAGCTCGTN 17
NNCGT$ATGTGTCGTAGCTCGT 16
T$ATGTGTCGTAGCTCGTNNCG 20
TAGCTCGTNNCGT$ATGTGTCG 8
TCGTAGCTCGTNNCGT$ATGTG 5
TCGTNNCGT$ATGTGTCGTAGC 12
TGTCGTAGCTCGTNNCGT$ATG 3
TGTGTCGTAGCTCGTNNCGT$A 1
TNNCGT$ATGTGTCGTAGCTCG 15
它的BWT及索引是
T 21
T 9
$ 0
N 18
T 6
T 13
G 11
A 10
C 19
C 7
T 4
T 2
C 14
N 17
T 16
G 20
G 8
G 5
C 12
G 3
A 1
G 15
然后得到它的tally文件如下
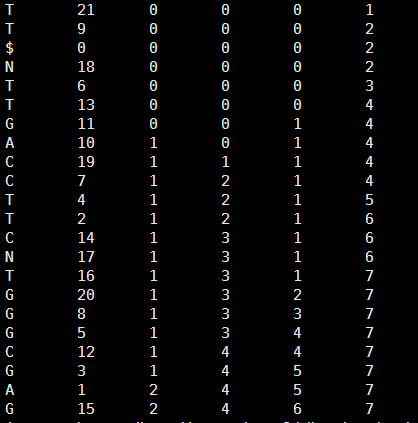
接下来用我们的perl程序在里面找字符串
第一次我测试 GTGTCG 这个字符串,程序可以很清楚的看到它的查找过程。
perl search_char.pl GTGTCG tm.tally
your last char is G
start is 7 ; and end is 13
now it is number 5 and the char is C
start is 3 ; and end is 6
now it is number 4 and the char is T
start is 17 ; and end is 19
now it is number 3 and the char is G
start is 10 ; and end is 11
now it is number 2 and the char is T
start is 19 ; and end is 20
now it is number 1 and the char is G
start is 11 ; and end is 12
It is just one perfect match !
The index is 2
第二次我测试一个多重匹配的字符串GT,在原字符串出现了五次的
perl search_char.pl GT tm.tally
your last char is T
start is 15 ; and end is 22
now it is number 1 and the char is G
start is 8 ; and end is 13
we find more than one perfect match!!!
8 13
One of the index is 11
One of the index is 10
One of the index is 19
One of the index is 7
One of the index is 4
One of the index is 2
One of the index is 14
惨了,这个是很严重的bug,不知道为什么,对于多个匹配总是会多出那么一点点的结果。
去转换矩阵里面查看,可知,前面两个结果11和10是错误的。
CTCGTNNCGT$ATGTGTCGTAG 11
GCTCGTNNCGT$ATGTGTCGTA 10
GT$ATGTGTCGTAGCTCGTNNC 19
GTAGCTCGTNNCGT$ATGTGTC 7
GTCGTAGCTCGTNNCGT$ATGT 4
GTGTCGTAGCTCGTNNCGT$AT 2
GTNNCGT$ATGTGTCGTAGCTC 14
最后我们测试未知字符串的查找。
perl search_char.pl ACATGTGT tm.tally
your last char is T
start is 15 ; and end is 22
now it is number 7 and the char is G
start is 8 ; and end is 13
now it is number 6 and the char is T
start is 19 ; and end is 21
now it is number 5 and the char is G
start is 11 ; and end is 12
now it is number 4 and the char is T
start is 20 ; and end is 21
now it is number 3 and the char is A
start is 2 ; and end is 3
now it is number 2 and the char is C
start is 3 ; and end is 3
we can just find the last 6 char ,and it is ATGTGT
原始字符串是ATGTGTCGTAGCTCGTNNCGT,所以查找的挺对的!!!
[perl]
$a=$ARGV[0];
$a=uc $a;
open FH,"<$ARGV[1]";
while(<FH>){
chomp;
@F=split;
$hash_count_atcg{$F[0]}++;
$hash{$.}=$_;
# the first line is $ and the last char and the last index !
}
$all_a=$hash_count_atcg{'A'};
$all_c=$hash_count_atcg{'C'};
$all_g=$hash_count_atcg{'G'};
$all_n=$hash_count_atcg{'N'};
$all_t=$hash_count_atcg{'T'};
#print "$all_a\t$all_c\t$all_g\t$all_t\n";
$len_a=length $a;
$end_a=$len_a-1;
#print "your query is $a\n";
#print "and the length of your query is $len_a \n";
$after=substr($a,$end_a,1);
#we fill search your query from the last char !
if ($after eq 'A') {
$start=2;
$end=$all_a+1;
}
elsif ($after eq 'C') {
$start=$all_a+1;
$end=$all_a+$all_c+1;
}
elsif ($after eq 'G') {
$start=$all_a+$all_c+1;
$end=$all_a+$all_c+$all_g+1;
}
elsif ($after eq 'T'){
$start=$all_a+$all_c+$all_g+$all_n+1;
$end=$all_a+$all_c+$all_g+$all_t+$all_n+1;
}
else {die "error !!! we just need A T C G !!!\n"}
print "your last char is $after\n ";
print "start is $start ; and end is $end \n";
foreach (reverse (1..$end_a)){
$after=substr($a,$_,1);
$before=substr($a,$_-1,1);
($start,$end)=&find_level($after,$before,$start,$end);
print "now it is number $_ and the char is $before \n ";
print "start is $start ; and end is $end \n";
if ($_ > 1 && $start == $end) {
$find_char=substr($a,$_);
$find_len=length $find_char;
print "we can just find the last $find_len char ,and it is $find_char \n";
#return "miss";
last;
}
if ($_ == 1) {
if (($end-$start)==1) {
print "It is just one perfect match ! \n";
my @F_start=split/\s+/,$hash{$end};
print "The index is $F_start[1]\n";
#return $F_start[1];
last;
}
else {
print "we find more than one perfect match!!!\n";
print "$start\t$end\n";
foreach (($start-1)..$end) {
my @F_start=split/\s+/,$hash{$_};
print "One of the index is $F_start[1]\n";
}
#return "multiple";
last;
}
}
}
sub find_level{
my($after,$before,$start,$end)=@_;
my @F_start=split/\s+/,$hash{$start};
my @F_end=split/\s+/,$hash{$end};
if ($before eq 'A') {
return ($F_start[2]+1,$F_end[2]+1);
}
elsif ($before eq 'C') {
return ($all_a+$F_start[3]+1,$all_a+$F_end[3]+1);
}
elsif ($before eq 'G') {
return ($all_a+$all_c+1+$F_start[4],$all_a+$all_c+1+$F_end[4]);
}
elsif ($before eq 'T') {
return ($all_a+$all_c+$all_g+$all_n+1+$F_start[5],$all_a+$all_c+$all_g+1+$all_n+$F_end[5]);
}
else {die "error !!! we just need A T C G !!!\n"}
}
[/perl]
原始字符串是atgtgtcgtagctcgtnncgt
前面讲到了如何用笨方法进行字符串搜索,也讲了如何构建bwt索引,和把bwt索引还原成字符串!
原始字符串是ATGCGTANNGTC
排序过程是下面的
$ATGCGTANNGTC 12
ANNGTC$ATGCGT 6
ATGCGTANNGTC$ 0
C$ATGCGTANNGT 11
CGTANNGTC$ATG 3
GCGTANNGTC$AT 2
GTANNGTC$ATGC 4
GTC$ATGCGTANN 9
NGTC$ATGCGTAN 8
NNGTC$ATGCGTA 7
TANNGTC$ATGCG 5
TC$ATGCGTANNG 10
TGCGTANNGTC$A 1
现在讲讲如何根据bwt索引构建tally,并且用tally搜索方法来搜索字符串!
首先是bwt索引转换为tally
C 12
T 6
$ 0
T 11
G 3
T 2
C 4
N 9
N 8
A 7
G 5
G 10
A 1
这个其实非常简单的,tally就是增加四列计数的列即可
[perl]
$hash_count{'A'}=0;
$hash_count{'C'}=0;
$hash_count{'G'}=0;
$hash_count{'T'}=0;
open FH ,"<$ARGV[0]";
while(<FH>){
chomp;
@F=split;
$last=$F[0]; # 读取上面的tally文件,分列,判断第一列,并计数
$hash_count{$last}++;
print "$_\t$hash_count{'A'}\t$hash_count{'C'}\t$hash_count{'G'}\t$hash_count{'T'}\n";
}
[/perl]
输出的tally如下
C 12 0 1 0 0
T 6 0 1 0 1
$ 0 0 1 0 1
T 11 0 1 0 2
G 3 0 1 1 2
T 2 0 1 1 3
C 4 0 2 1 3
N 9 0 2 1 3
N 8 0 2 1 3
A 7 1 2 1 3
G 5 1 2 2 3
G 10 1 2 3 3
A 1 2 2 3 3
接下来就是针对这个tally的查询函数了
由于之前就简单的看了看bowtie作者的ppt,没有完全吃透就开始敲代码了,写了十几个程序最后我自己都搞不清楚进展到哪一步了,所以我现在整理一下,从新开始!!!
首先,bowtie的作用就是在一个大字符串里面搜索一个小字符串!那么本身就有一个非常笨的复杂方法来搜索,比如,大字符串长度为100万,小字符串为10,那么就依次取出大字符串的10个字符来跟小字符串比较即可,这样的算法是非常不经济的,我简单用perl代码实现一下。
[perl]
#首先读取大字符串的fasta文件
open FH ,"<$ARGV[0]";
$i=0;
while (<FH>) {
next if /^>/;
chomp;
$a.=(uc);
}
#print "$a\n";
#然后接受我们的小的查询字符串
$query=uc $ARGV[1];
$len=length $a;
$len_query=length $query;
$a=$a.'$'.$a;
#然后依次循环取大字符串来精确比较!
foreach (0..$len-1){
if (substr($a,$_,$len_query) eq $query){
print "$_\n";
#last;
}
}
[/perl]
这样在时间复杂度非常恐怖,尤其是对人的30亿碱基。
正是因为这样的查询效率非常低,所以我们才需要用bwt算法来构建索引,然后根据tally来进行查询
其中构建索引有三种方式,我首先讲最效率最低的那种索引构造算法,就是依次取字符串进行旋转,然后排序即可。
[perl]
$a=uc $ARGV[0];
$len=length $a;
$a=$a.'$'.$a;
foreach (0..$len){
$hash{substr($a,$_,$len+1)}=$_;
}
#print "$_\t$hash{$_}\n" foreach sort keys %hash;
print substr($_,-1),"\t$hash{$_}\n" foreach sort keys %hash;
[/perl]
这个算法从时间复杂度来讲是非常经济的,对小字符串都是瞬间搞定!!!
perl rotation_one_by_one.pl atgcgtanngtc 这个字符串的BWT矩阵索引如下!
C 12
T 6
$ 0
T 11
G 3
T 2
C 4
N 9
N 8
A 7
G 5
G 10
A 1
但同样的,它也有一个无法避免的弊端,就是内存消耗太恐怖。对于30亿的人类碱基来说,这样旋转会生成30亿乘以30亿的大矩阵,一般的服务器根本hold不住的。
最后我讲一下,这个BWT矩阵索引如何还原成原字符串,这个没有算法的差别,因为就是很简单的原理。
[perl]
#first read the tally !!!
#首先读取上面输出的BWT矩阵索引文件。
open FH,"<$ARGV[0]";
$hash_count{'A'}=0;
$hash_count{'C'}=0;
$hash_count{'G'}=0;
$hash_count{'T'}=0;
while(<FH>){
chomp;
@F=split;
$hash_count{$F[0]}++;
$hash{$.}="$F[0]\t$F[1]\t$hash_count{$F[0]}";
#print "$hash{$.}\n";
}
$all_a=$hash_count{'A'};
$all_c=$hash_count{'C'};
$all_g=$hash_count{'G'};
$all_t=$hash_count{'T'};
$all_n=$hash_count{'N'};
#start from the first char !
$raw='';
&restore(1);
sub restore{
my($num)=@_;
my @F=split/\t/,$hash{$num};
$raw.=$F[0];
my $before=$F[0];
if ($before eq 'A') {
$new=$F[2]+1;
}
elsif ($before eq 'C') {
$new=1+$all_a+$F[2];
}
elsif ($before eq 'G') {
$new=1+$all_a+$all_c+$F[2];
}
elsif ($before eq 'N') {
$new =1+$all_a+$all_c+$all_g+$F[2];
}
elsif ($before eq 'T') {
$new=1+$all_a+$all_c+$all_g+$all_n+$F[2];
}
elsif ($before eq '$') {
chop $raw;
$raw = reverse $raw;
print "$raw\n";
exit;
}
else {die "error !!! we just need A T C N G !!!\n"}
#print "$F[0]\t$new\n";
&restore($new);
}
[/perl]
竹子-博客(.NET/Java/Linux/架构/管理/敏捷)
思索、感悟、践行!走向高效,快乐,平衡!
已下目录是本人用爬虫爬取的!
每天一个linux命令(61):wget命令
每天一个linux命令(60):scp命令
每天一个linux命令(59):rcp命令
每天一个linux命令(58):telnet命令
每天一个linux命令(57):ss命令
每天一个linux命令(56):netstat命令
每天一个linux命令(55):traceroute命令
每天一个linux命令(54):ping命令
每天一个linux命令(53):route命令
每天一个linux命令(52):ifconfig命令
每天一个linux命令(51):lsof命令
每天一个linux命令(50):crontab命令
每天一个linux命令(49):at命令
每天一个linux命令(48):watch命令
每天一个linux命令(47):iostat命令
每天一个linux命令(46):vmstat命令
每天一个linux命令(45):free 命令
每天一个linux命令(44):top命令
每天一个linux命令(43):killall命令
每天一个linux命令(42):kill命令
每天一个linux命令(41):ps命令
每天一个linux命令(40):wc命令
每天一个linux命令(39):grep 命令
每天一个linux命令(38):cal 命令
每天一个linux命令(37):date命令
每天一个linux命令(36):diff 命令
每天一个linux命令(35):ln 命令
每天一个linux命令(34):du 命令
每天一个linux命令(33):df 命令
每天一个linux命令(32):gzip命令
每天一个linux命令(31): /etc/group文件详解
每天一个linux命令(30): chown命令
每天一个linux命令(29):chgrp命令
每天一个linux命令(28):tar命令
每天一个linux命令(27):linux chmod命令
每天一个linux命令(26):用SecureCRT来上传和下载文件
每天一个linux命令(25):linux文件属性详解
每天一个linux命令(24):Linux文件类型与扩展名
每天一个linux命令(23):Linux 目录结构
每天一个linux命令(22):find 命令的参数详解
每天一个linux命令(21):find命令之xargs
每天一个linux命令(20):find命令之exec
每天一个linux命令(19):find 命令概览
每天一个linux命令(18):locate 命令
每天一个linux命令(17):whereis 命令
每天一个linux命令(16):which命令
每天一个linux命令(15):tail 命令
每天一个linux命令(14):head 命令
每天一个linux命令(13):less 命令
每天一个linux命令(12):more命令
每天一个linux命令(11):nl命令
每天一个linux命令(10):cat 命令
每天一个linux命令(9):touch 命令
每天一个linux命令(8):cp 命令
每天一个linux命令(7):mv命令
每天一个linux命令(6):rmdir 命令
每天一个linux命令(5):rm 命令
每天一个linux命令(4):mkdir命令
每天一个linux命令(3):pwd命令
每天一个linux命令(2):cd命令
每天一个linux命令(1):ls命令
老实说,模块其实是一个很讨厌的东西,但是它也实实在在的节省了我们很多时间,也符合我的理念:避免重复造轮子!此教程可能过期了,请直接看最新版(perl模块安装大全)
如果有root权限,用root权限
进入cpan然后install ExtUtils::Installed模块
这样就可以执行instmodsh这个脚本了,可以查看当前环境下所有的模块 Continue reading
发现自己搞服务器遇到的困难还是蛮多的,所以记录了一下,给菜鸟们指个路。
ubuntu对生信菜鸟来说是最好用的linux服务器,没有之一,因为它有apt-get。
很多人可能并没有自己的服务器,那么就只能通过虚拟机来试试ubuntu啦
我想起来我以前玩虚拟机的时候遇到过一些困难,记录了一些,分享给大家, Continue reading
发现自己搞服务器遇到的困难还是蛮多的,所以记录了一下,给菜鸟们指个路。
ubuntu对生信菜鸟来说是最好用的linux服务器,没有之一,因为它有apt-get。
很多时候大家的服务器可能并不是想联网,只是想玩一下,或者只是因为生信的某些软件要求数据库,所以大家可能会单独安装mysql,或者想学习perl的CGI模块,需要apache。
非常简单只需要几条命令就可以完成。
1. sudo apt-get install mysql-server
2. sudo apt-get install mysql-client
3. sudo apt-get install libmysqlclient-dev
安装过程中会提示设置密码什么的,注意设置了不要忘了,安装完成之后可以使用如下命令来检查是否安装成功:
sudo netstat -tap | grep mysql
通过上述命令检查之后,如果看到有mysql 的socket处于 listen 状态则表示安装成功。
登陆mysql数据库可以通过如下命令:
mysql -u root -p
-u 表示选择登陆的用户名, -p 表示登陆的用户密码,上面命令输入之后会提示输入密码,此时输入密码就可以登录到mysql。
在Ubuntu上安装Apache,有两种方式:1 使用开发包的打包服务,例如使用apt-get命令;2 从源码构建Apache。本文章将详细描述这两种不同的安装方式。
方法一:使用开发包的打包服务——apt-get
安装apache,在命令行终端中输入一下命令:
$ sudo apt-get install apache2
安装完成后,重启apache服务,在命令行终端中输入一下命令:
$ sudo /etc/init.d/apache2 restart
可能会出现的问题1: NameVirtualHost *:80 has no VirtualHosts,
出现上述问题的原因:定义了多个NameVirtualHost,故将/etc/apache2/ports.conf中的NameVirtualHost *:80注释掉即可。
可能会出现的问题2: Could not reliably determine the server's fully qualified domain name, using 127.0.1.1 for ServerName
原因:
根据提示,无法可靠的确定服务器的有效域名,使用127.0.1.1作为服务器域名。应此,在下面的测试中,应该使用127.0.1.1,而不是127.0.0.1!
解决:
$ vim /etc/apache2/httpd.conf,在文件中添加:
ServerName localhost:80,再次重启apache2,就可以使用127.0.0.1来访问web服务器啦!
测试:
在浏览器里输入http://localhost或者是http://127.0.0.1,如果看到了It works!,那就说明Apache就成功的安装了,Apache的默认安装,会在/var下建立一个名为www的目录,这个就是Web目录了,所有要能 过浏览器访问的Web文件都要放到这个目录里。
发现自己搞服务器遇到的困难还是蛮多的,所以记录了一下,给菜鸟们指个路。
ubuntu对生信菜鸟来说是最好用的linux服务器,没有之一,因为它有apt-get。
主流的网络服务器配置就是linux+apache+mysql+php咯,简称LAMP
在ubuntu系统里面安装这个是非常easy的
sudo apt-get install apache2 mysql-server mysql-client php5 php5-gd php5-mysql Continue reading
此教程可能过期了,请直接看最新版(perl模块安装大全)
发现自己搞服务器遇到的困难还是蛮多的,所以记录了一下,给菜鸟们指个路。
ubuntu对生信菜鸟来说是最好用的linux服务器,没有之一,因为它有apt-get。
前面我简单写了一个perl的cpan安装模块,但是前些天突然发现有些perl模块在cpan里面找不到,所以又总结了一下不同的perl模块安装方法。 Continue reading
发现自己搞服务器遇到的困难还是蛮多的,所以记录了一下,给菜鸟们指个路。
ubuntu对生信菜鸟来说是最好用的linux服务器,没有之一,因为它有apt-get。
在我的第一讲里面,对JAVA的安装,其实就需要添加环境变量,大家可以回头看看!
添加PATH环境变量,第1种方法:
[root@lx_web_s1 ~]# export PATH=/usr/local/webserver/mysql/bin:$PATH
再次查看:
[root@lx_web_s1 ~]# echo $PATH
/usr/local/webserver/mysql/bin:/usr/local/webserver/mysql/bin/:/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
说明添加PATH成功。
上述方法的PATH 在终端关闭 后就会消失。所以还是建议通过编辑/etc/profile来改PATH,也可以修改家目录下的.bashrc(即:~/.bashrc)。
第2种方法:需要管理员权限。
# vim /etc/profile
在最后,添加:
export PATH="/usr/local/webserver/mysql/bin:$PATH"
保存,退出,然后运行:
#source /etc/profile,不报错则成功。
发现自己搞服务器遇到的困难还是蛮多的,所以记录了一下,给菜鸟们指个路。
ubuntu对生信菜鸟来说是最好用的linux服务器,没有之一,因为它有apt-get。
同样,这个ssh也非常简单
sudo apt-get install openssh-server
SSH分客户端openssh-client和openssh-server
如果你只是想登陆别的机器的SSH只需要安装openssh-client(ubuntu有默认安装,如果没有则sudo
apt-get install openssh-client),如果要使本机开放SSH服务就需要安装openssh-server
sudo apt-get install openssh-server
然后确认sshserver是否启动了:
ps -e |grep ssh
如果看到sshd那说明ssh-server已经启动了。
如果没有则可以这样启动:sudo /etc/init.d/ssh start 或者 service ssh start
ssh-server配置文件位于/etc/ssh/sshd_config,在这里可以定义SSH的服务端口,默认端口是22,你可以自己定义成其他端口号,如222。
然后重启SSH服务:
sudo
/etc/init.d/ssh stop
sudo /etc/init.d/ssh start
然后使用以下方式登陆SSH:
ssh username@192.168.1.112 username为192.168.1.112 机器上的用户,需要输入密码。
我给七八个虚拟机都配置成功了,但是呢,偏偏别人的一个我始终不能解决,感觉linux里面的学问还是蛮多的
发现自己搞服务器遇到的困难还是蛮多的,所以记录了一下,给菜鸟们指个路。
ubuntu对生信菜鸟来说是最好用的linux服务器,没有之一,因为它有apt-get。
这个主要是针对有界面的服务器来说的,不是我们通常意义的ssh登陆,一般ssh登陆的可以把中文复制张贴进去即可。
Ubuntu上的输入法主要有小小输入平台(支持拼音/二笔/五笔等),Fcitx,Ibus,Scim等。其中Scim和Ibus是输入法框架。
在Ubuntu的中文系统中自带了中文输入法,通过Ctrl+Space可切换中英文输入法。这里我们主要说下Ubuntu英文系统中,中文输入法的安装。
安装输入法的第一步,是安装语言包。我们选择System Settings-->Language Support-->Install/Remove Languages,这里面可以选择简体中文
输入密码后,系统会安装简体中文语言包。
第二步,安装完毕后切换到终端,安装IBus框架,在终端输入以下命令:
sudo apt-get install ibus ibus-clutter ibus-gtk ibus-gtk3 ibus-qt4
启动IBus框架,在终端输入:
im-switch -s ibus
安装完IBus框架后注销系统,保证更改立即生效。
第三步:安装拼音引擎
有下面几种常用选择:
IBus拼音:sudo apt-get install ibus-pinyin
IBUS五笔:sudo apt-get install ibus-table-wubi
谷歌拼音输入法:sudo apt-get install ibus-googlepinyin
Sun拼音输入法:sudo apt-get install ibus-sunpinyin
第四步:设置IBus框架
终端输入ibus-setup 此时,IBus Preference设置被打开。我们在Input Method选项卡中,选择自己喜欢的输入方式,并配置自己喜欢的快捷键即可。
第五步:通常情况下,IBus图标(一个小键盘)会出现在桌面右上角的任务栏中。有时候这个图标会自行消失,可使用以下命令,找回消失的IBus图标:
ibus-daemon –drx
发现自己搞服务器遇到的困难还是蛮多的,所以记录了一下,给菜鸟们指个路。
ubuntu对生信菜鸟来说是最好用的linux服务器,没有之一,因为它有apt-get。
理论上perl是不需要更新,但是我就不巧碰到了这个情况,所以也记录一下
linux下升级系统默认安装的perl版本,不建议先rm
先下载tar.gz ...然後手动安装..default 安装到/usr/local/目录下..
然後修改/usr/bin/perl的symbolic link到/usr/local/bin/perl
下载方式不用说了吧,各显神通,笔者习惯用wget.
所以wget[url]http://www.cpan.org/src/perl-5.10.0.tar.gz[/url] .现在最新是5.20
下载完以后解压安装
#tar zxvf perl-5.10.0.tar.gz
#cd perl-5.10.0
#./Configure -des -Dprefix=/usr/local/perl
参数-Dprefix指定安装目录为/usr/local/perl
#make
#make test
#make install
如果这个过程没有错误的话,那么恭喜你安装完成了.是不是很简单?
接下来替换系统原有的perl,有最新的了咱就用嘛.
#mv /usr/bin/perl/ usr/bin/perl.bak
#ln -s /usr/local/perl/bin/perl/ usr/bin/perl
#perl –v
然后就可以了用它来安装一些其它你需要的perl模块了
#perl -MCPAN-e shell
第一次执行的话,会提示安装cpan并要求连接网络下载最新的模块列表.然后就可以安装东西了
cpan[1]> install DBI
)