最近刷到了朋友圈的国家生物信息学中心的公开课,非常丰富,其中2023的基因组学授课可能会适合广大的生物信息学朋友们。主页是:
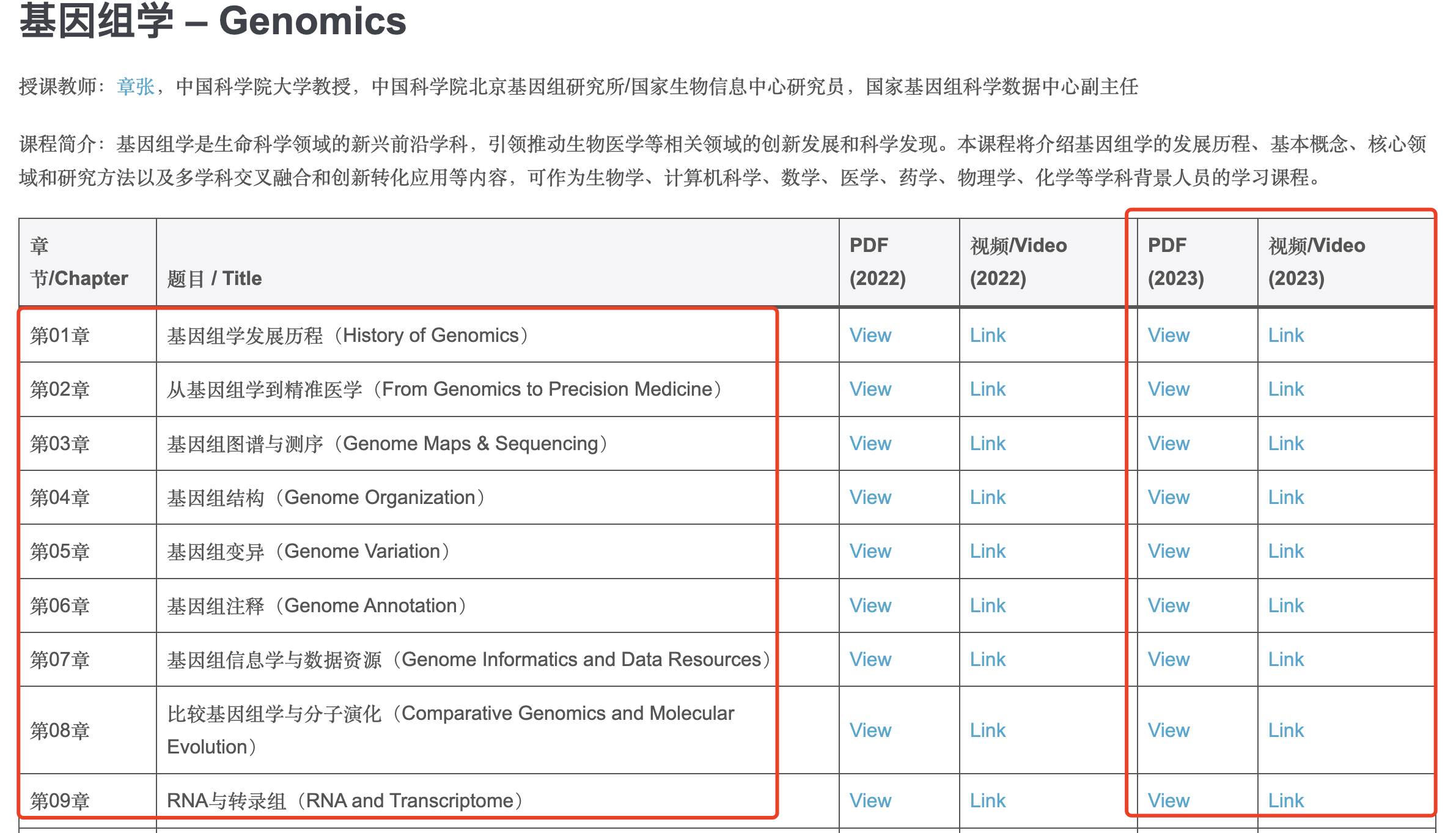
从主页可以看到他们的授课视频和PPT都是公开的,其中视频是在人民群众喜闻乐见的B站,如下所示的目录和时长;
- P1 课程介绍与安排 34:41
- P2 第1章基因组学发展史 1:21:11
- P3 第2章从基因组学到精准医学 1:23:47
- P4 第3章基因组图谱与测序 1:41:57
- P5 第4章基因组结构 1:42:45
- P6 第5章基因组变异 1:42:56
- P7 第6章基因组注释 1:43:07
- P8 第7章基因组信息学与数据资源 1:44:22
- P9 第8章比较基因组学与分子演化 1:42:48
- P10 第9章RNA与转录组 1:43:48
- P11 第11章基因型与表型关联分析 1:41:41
- P12 第12章泛基因组与宏基因组 1:41:00
- P13 第13章癌症基因组学与精准医学 1:36:40
- P14 第14章健康基因组学与人口健康 1:34:57
- P15 第15章药物基因组学与精准用药 1:15:54
- P16 第16章法医基因组学与公共安全 1:28:00
- P17 第17章作物基因组学与分子育种 1:29:12
- P18 课程总结 30:41
授课PPT可以爬虫获取
因为上面的主页是表格化的信息:
在R中,你可以使用rvest包来抓取和解析HTML内容,使用read_html()函数加载HTML页面,然后使用html_table()函数来提取表格数据。
library(rvest)
url <- "https://ngdc.cncb.ac.cn/education/courses/genomics/"
webpage <- read_html(url)
tables <- html_table(webpage)
desired_table <- tables[[1]] # 选择第一个表格
使用 html_nodes() 函数定位包含超链接的 HTML 元素。然后使用 html_attr() 函数提取 <a> 元素的 href 属性,这是超链接的 URL。
link_nodes <- html_nodes(webpage, "a")
link_urls <- html_attr(link_nodes, "href")
link_urls[grepl('2023',link_urls)]
可以看到是17个超链接,但是真正的授课PPT躲在每个超链接的背后:
[1] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-01-2023/"
[2] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-02-2023/"
[3] "https://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-03-2023/"
[4] "https://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-04-2023/"
[5] "https://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-05-2023/"
[6] "https://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-06-2023/"
[7] "https://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-07-2023/"
[8] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-08-2023/"
[9] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-09-2023/"
[10] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-10-2023/"
[11] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-11-2023/"
[12] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-12-2023/"
[13] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-13-2023/"
[14] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-14-2023/"
[15] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-15-2023/"
[16] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-16-2023/"
[17] "http://ngdc.cncb.ac.cn/education/courses/genomics/genomics-chapter-17-2023/"
我们简单的肉眼看看规律:
https://ngdc.cncb.ac.cn/education/wp-content/uploads/2023/06/%E5%9F%BA%E5%9B%A0%E7%BB%84%E5%AD%A6-%E7%AC%AC15%E7%AB%A0-%E8%8D%AF%E7%89%A9%E5%9F%BA%E5%9B%A0%E7%BB%84%E5%AD%A6-v7.pdf
居然是文件名字里面的有中文,怪不得:
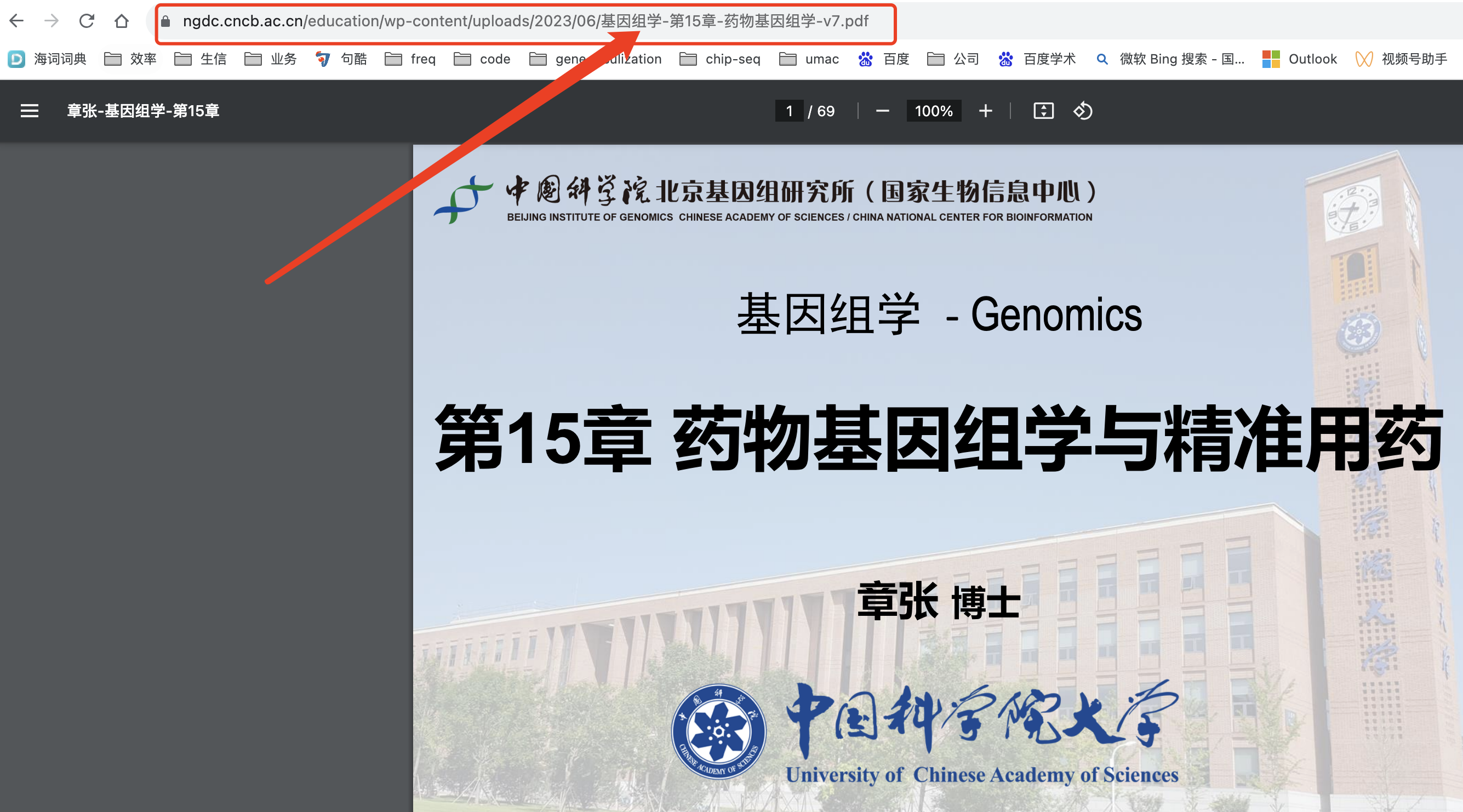
其实最方便的当然是手动点击17次,进入每个课件网页里面去下载,工作量也不大,但是,其实它有多个类似的课程,如果是每个都类似的干活确实是不符合我们的生物信息学工程师技能水平:
| 课程名称 / Course name | 授课人 / Teacher | 资料类别 / Format |
|---|---|---|
| 实用生物信息技术 / Applied Bioinformatics Course (ABC) | 罗静初 / Jingchu Luo | HTML/PDF/Video |
| 生物信息学 / Bioinformatics | 薛宇 / Yu Xue | |
| 基因组学 / Genomics | 章张 / Zhang Zhang | PDF/Video |
| 基因组学分析 / Genomics Data Analysis | 李程 / Cheng Li | |
| 全基因组关联分析 / GWAS | 贾佩林 / Peilin Jia |
学徒作业
完成上面的全部的课程的授课PPT的爬虫代码,自动下载其全部的课程pdf哦!我这里简单的抛砖引玉一下:
all_pdfs <- unlist(
lapply(uls, function(x){
#x=uls[1]
webpage <- read_html(x)
xs = html_attr(html_nodes(webpage, "a"), "href")
unique(xs[grepl('pdf',xs)])
})
)
lapply(seq_along(all_pdfs), function(i) {
download.file(all_pdfs[i], destfile = basename(all_pdfs[i]), mode = "wb")
})
值得注意是爬虫其实是多种多样的,我前面分享过:爬虫的10种思路,需要了解一下网页html源代码里面的dom结构。文档对象模型(Document Object Model,DOM)是 HTML 和 XML 文档的编程接口,它表示页面的结构,使开发者可以通过编程方式访问和修改文档的内容、结构和样式。HTML 源代码中的 DOM 结构是一个树状结构,表示了页面元素之间的层次关系。其中:
- Document (文档):整个 HTML 文档是文档对象模型的根节点。
- html Element (html 元素):表示 HTML 文档的
<html>元素。 - head Element (head 元素):表示文档头部的
<head>元素,包括页面的元信息、样式表和脚本等。 - title Element (title 元素):表示
<title>元素,包含页面的标题。 - body Element (body 元素):表示文档的主体部分,包括页面中的所有内容。
- h1、p、ul、li、a 元素:表示页面中的各种元素,如标题、段落、列表、链接等。
- div 元素:用于组织和结构化文档内容,例如,页面的不同部分。
- Attribute (属性):元素上的属性,例如,链接元素
<a>上的href属性。
这个结构形成了一个树状层次,很容易解析后针对性获取不同层次的元素里面的信息哦!
值得注意的是里面也有一些讲座录屏哦,比如:https://ngdc.cncb.ac.cn/education/trainings/wpp2021/
