最近看到了一个胰腺癌的单细胞文章,公开了其测序数据及表达量矩阵,很方便做图表复现。
我看了的质控降维聚类分群定位到了Acinar的单细胞亚群,它跟胰腺癌的癌细胞或者说上皮细胞共享了不少标记基因,让我对单细胞亚群和单细胞状态的定义又产生了怀疑。如下所示:
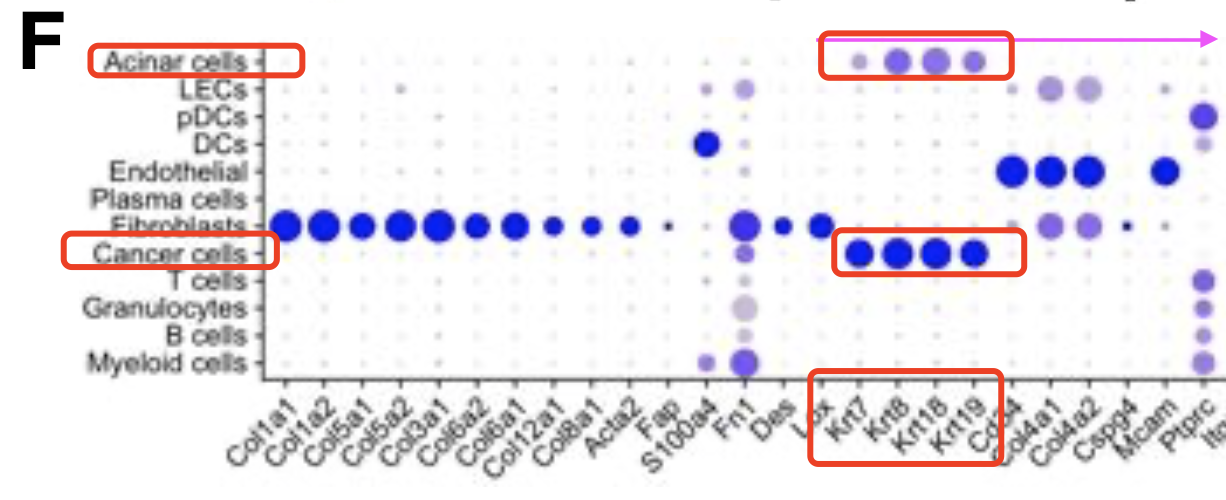
所以去查了查 Pancreatic Acinar Cells到底是什么东西,就看到了发表在Am J Pathol. 2017 Dec; 的文章《Human Pancreatic Acinar Cells 》,doi: 10.1016/j.ajpath.2017.08.017 ,这个文章很简单的饼图,并没有差异分析,就做了富集分析,我觉得这样的做法是值得批判的,研究者做了蛋白质组学数据,拿到了有功能的蛋白编码基因,然后对这个基因集进行生物学功能富集:

因为蛋白质组学发展的比较慢,所以并不是跟转录组那样的对全部的基因都可以检测到信号,所以仅仅是1000多个蛋白被检测是可以理解的。
关于蛋白质组学数据
文章描述如下:
Protein extracts from untreated, freshly isolated, human acini from four organ donors (Table 3 provides organ donor information) were analyzed by high-precision liquid chromatography–tandem mass spectrometry in an Orbitrap Elite analyzer; data were quantified using MaxQuant version 1.3.0.5. Of the total proteins identified, 70% were common to all samples and used for further analysis.
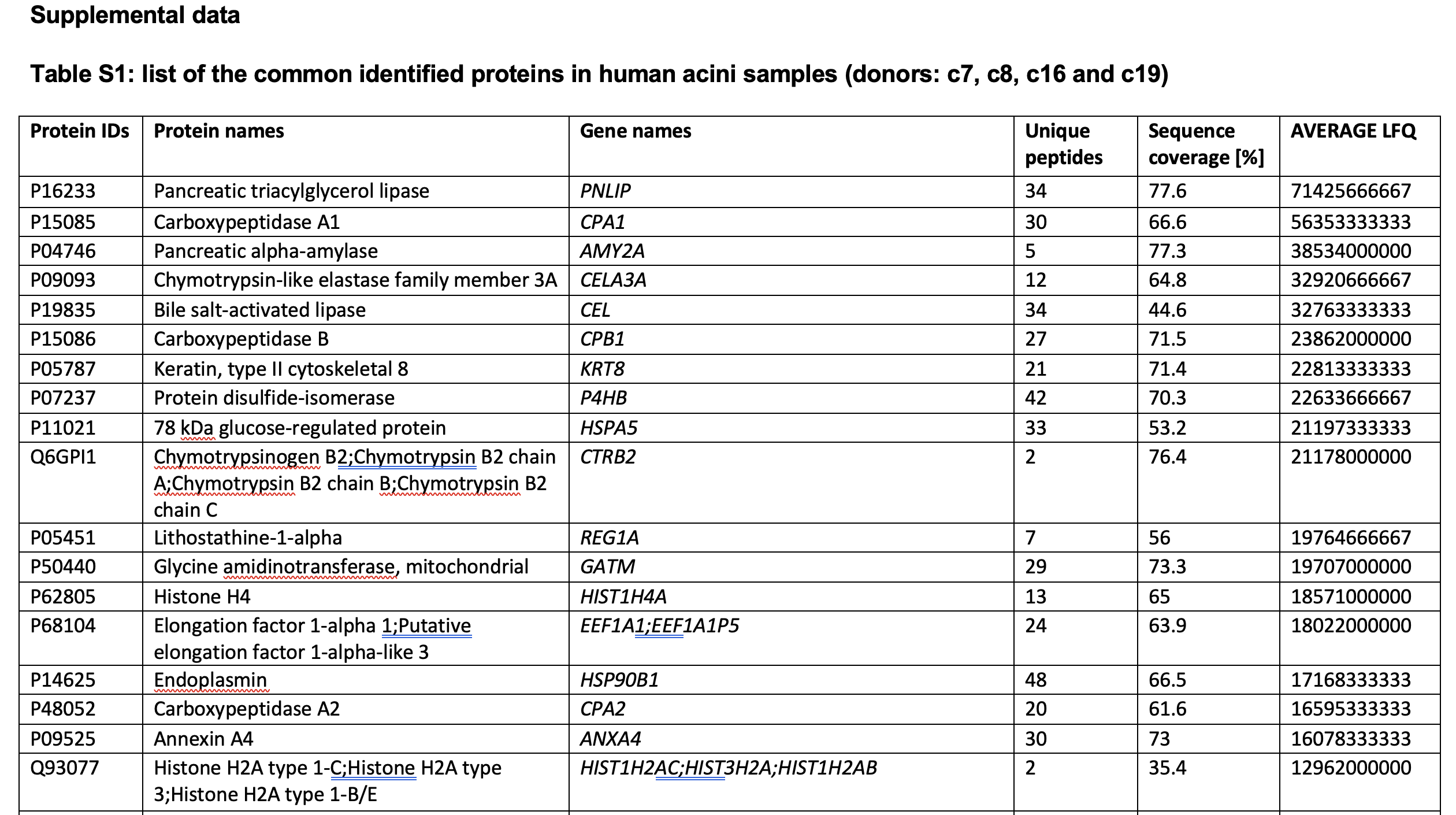
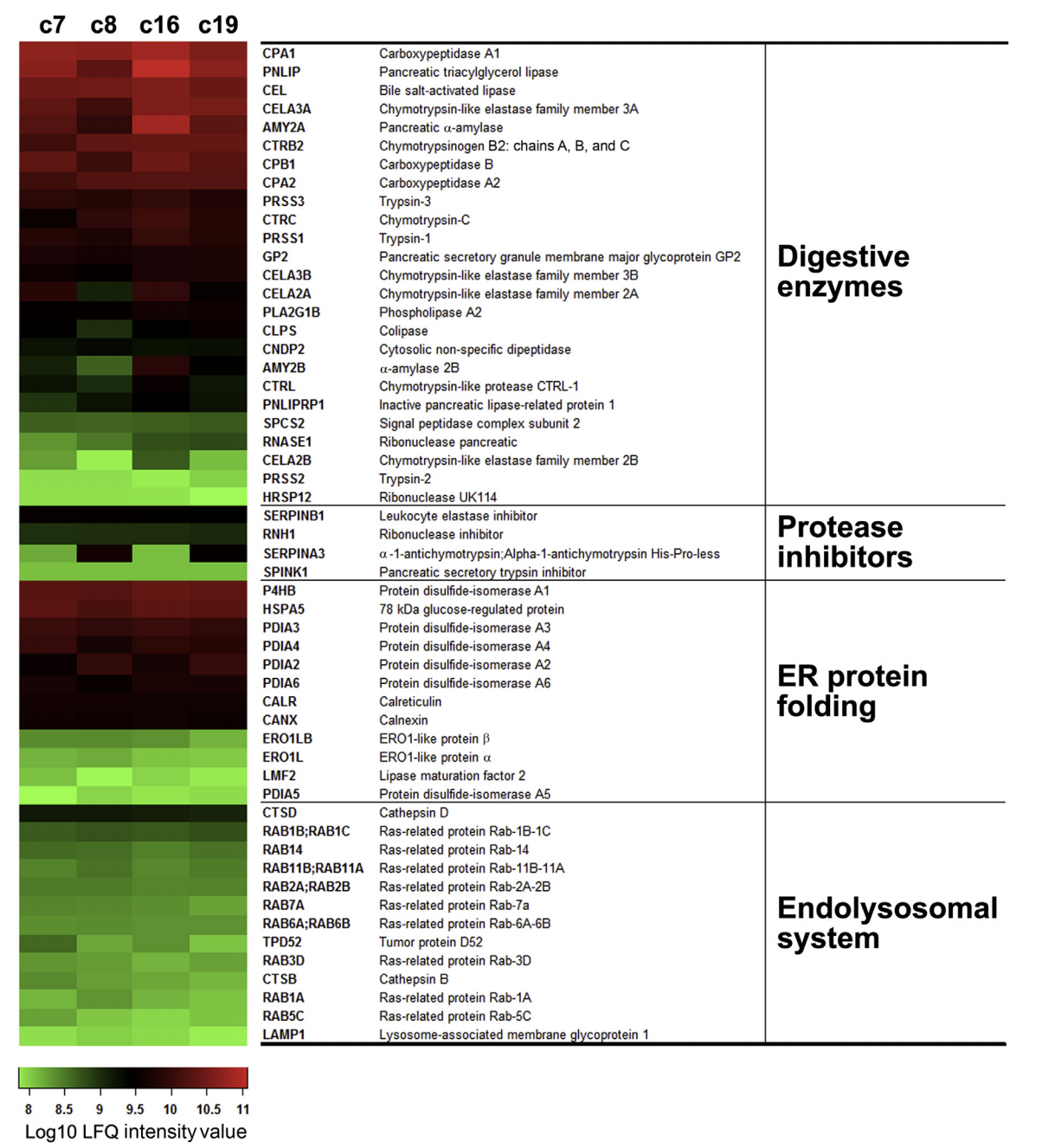
全部的数据在:Table S1: list of the common identified proteins in human acini samples (donors: c7, c8, c16 and c19)
如下所示,在4个不同样品里面的检测到的蛋白情况是:
主要是 MaxQuant 软件的使用啦,我们《生信技能树》早期也分享过蛋白质组学数据处理教程,目录如下:
- 蛋白质组学第1期-认识基础概念
- 蛋白质组学第2期-认识蛋白质组学原始数据
- 蛋白质组学第3期-蛋白质组学的三大元素
- 蛋白质组学第4期 文章搜库过程复现
- 蛋白质组学第5期搜库软件之 MaxQuant 再介绍
- 蛋白质组学第6期 搜库软件之 MaxQuant 结果数据介绍
- 蛋白质组学第7期 复现文章数据- 预处理之Perseus 的使用
- 蛋白质组学第8期 文章复现之数据处理
- 蛋白质组学第9期 文章数据分析之差异蛋白筛选和功能分析
不过呢,对这个文章来说,因为附件已经给了基于检测到 的蛋白质的表达量矩阵,而且呢4个样品并不是分组去找差异,所以我们系列教程都用不上,哈哈。
这就是让我纳闷的地方,他们居然并没有做差异分析,就直接对全部的检测到的蛋白质对应的基因进行生物学功能数据库富集分析。生物学功能数据库富集分析
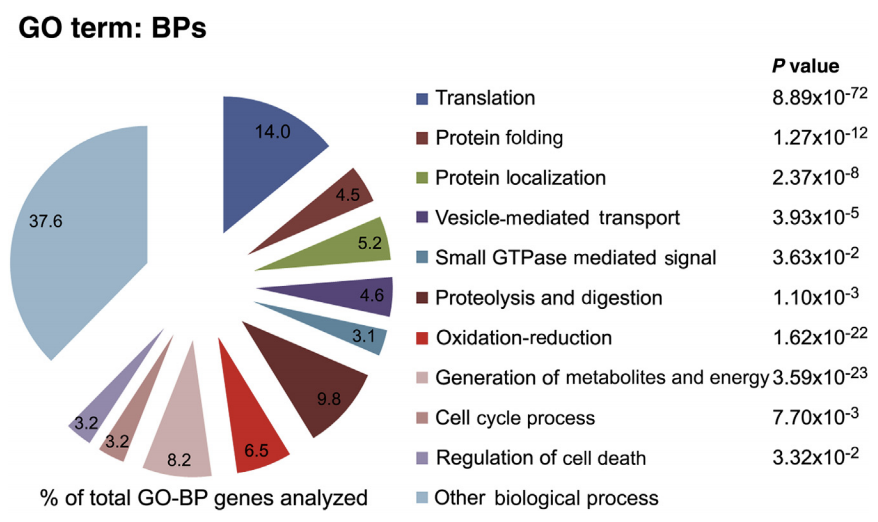
首先是GO数据库注释:
Among the 1509 confidently identified proteins, 1044 (approximately 69% of all identified proteins) were common across the four samples analyzed (Supplemental Table S1).
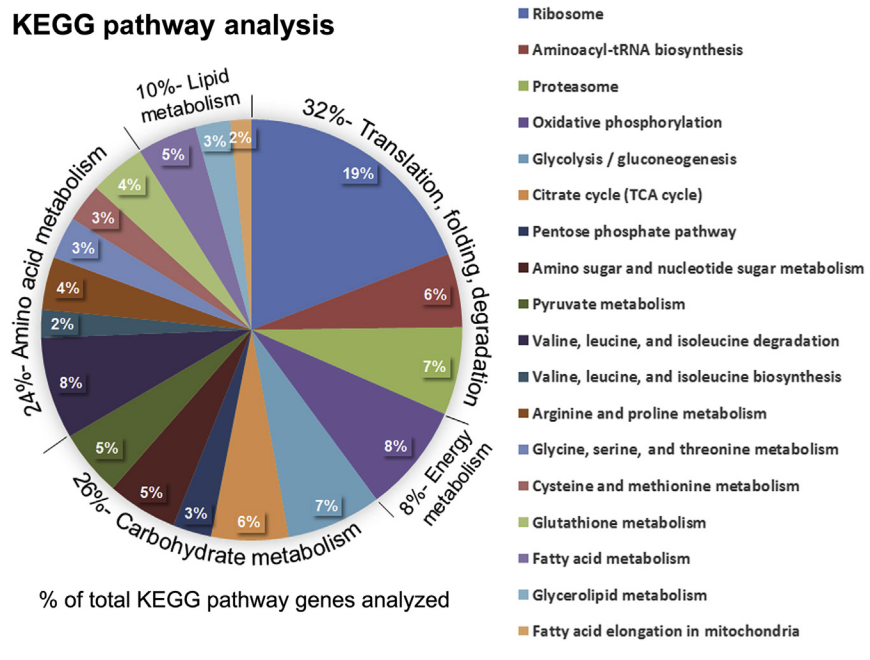
然后是KEGG数据库注释:
四个受试者数据独立分析,前面对全部的检测到的蛋白质对应的基因进行生物学功能数据库富集分析,有了结果。然后凭借着作者的“一厢情愿” 取出来几个基因集,进行热图可视化:
The heat map shows relative amounts of the indicated selected proteins determined by label-free quantification (LFQ). Selected proteins include all identified digestive enzymes, protease inhibitors, abundant protein biosynthetic components (endoplasmic reticulum chaperones and foldases), and proteins in the endolysosomal system.
这样的数据分析思路纯粹是搞笑哦,举个例子,如果是从全国人民里面挑选top1000个有钱人,发现集中于北上广深杭5个城市,那么我们的结论当然是中国有钱人主要是集中于北上广深杭这样的一线大都市啦。
但是,如果我们仅仅是拿北上广深杭这5个城市的本地宝这样的公众号或者APP的用户来进行地理位置发现, 发现这些用户居然都是北上广深杭城市的人,这样的结论不是毫无意义吗?
如果作者是在2万个基因里面,拿到了1000个重要的基因,然后进行生物学功能数据库富集分析,发现它富集到了哪个GO或者KEGG,这样的结论我们当然承认。但是现在作者本来就是仅仅是检测了1000个基因,根本就没有人类的其它2万个基因的如何事情,那它的富集结果跟生物学问题无关,仅仅是蛋白质这个检测技术的问题。