前面我们公布了《cytof数据资源介绍(文末有交流群)》,现在就开始正式手把手教学。
上一讲我们构造好了SingleCellExperiment对象,后续全部的分析都会以这个SingleCellExperiment对象为准,大家务必熟悉SingleCellExperiment对象的各种结构,教程见:cytofWorkflow之构建SingleCellExperiment对象(二)。有了这个SingleCellExperiment对象,而且经过了合理的质量控制,接下来就可以进行聚类分群拉!
第一次聚类分群需要指定自己需要多少个亚群
通常建议第一次分群,细一点要好,后面可以人工合并。所以我这里先指定20个亚群,代码如下:
pro='basic_cluster_k20'
set.seed(1234)
#
# We call ConsensusClusterPlus() with maximum number of clusters maxK = 20.
sce <- cluster(sce, features = "type",
xdim = 10, ydim = 10, maxK = 20, seed = 1234)
pdf(paste0(pro,'_cluster_plotExprHeatmap_row_clust_F.pdf'))
plotExprHeatmap(sce, features = "type",
by = "cluster_id", k = "meta20",
row_clust = F,
bars = TRUE, perc = TRUE)
dev.off()
pdf(paste0(pro,'_plotClusterExprs.pdf'))
plotClusterExprs(sce, k = "meta20", features = "type")
dev.off()
pdf(paste0(pro,'_cluster_plotMultiHeatmap.pdf'))
plotMultiHeatmap(sce,
hm1 = "type", k = "meta20",
row_anno = FALSE, bars = TRUE, perc = TRUE)
dev.off()
我们直接看最后一个图,这20个细胞亚群如下所示:
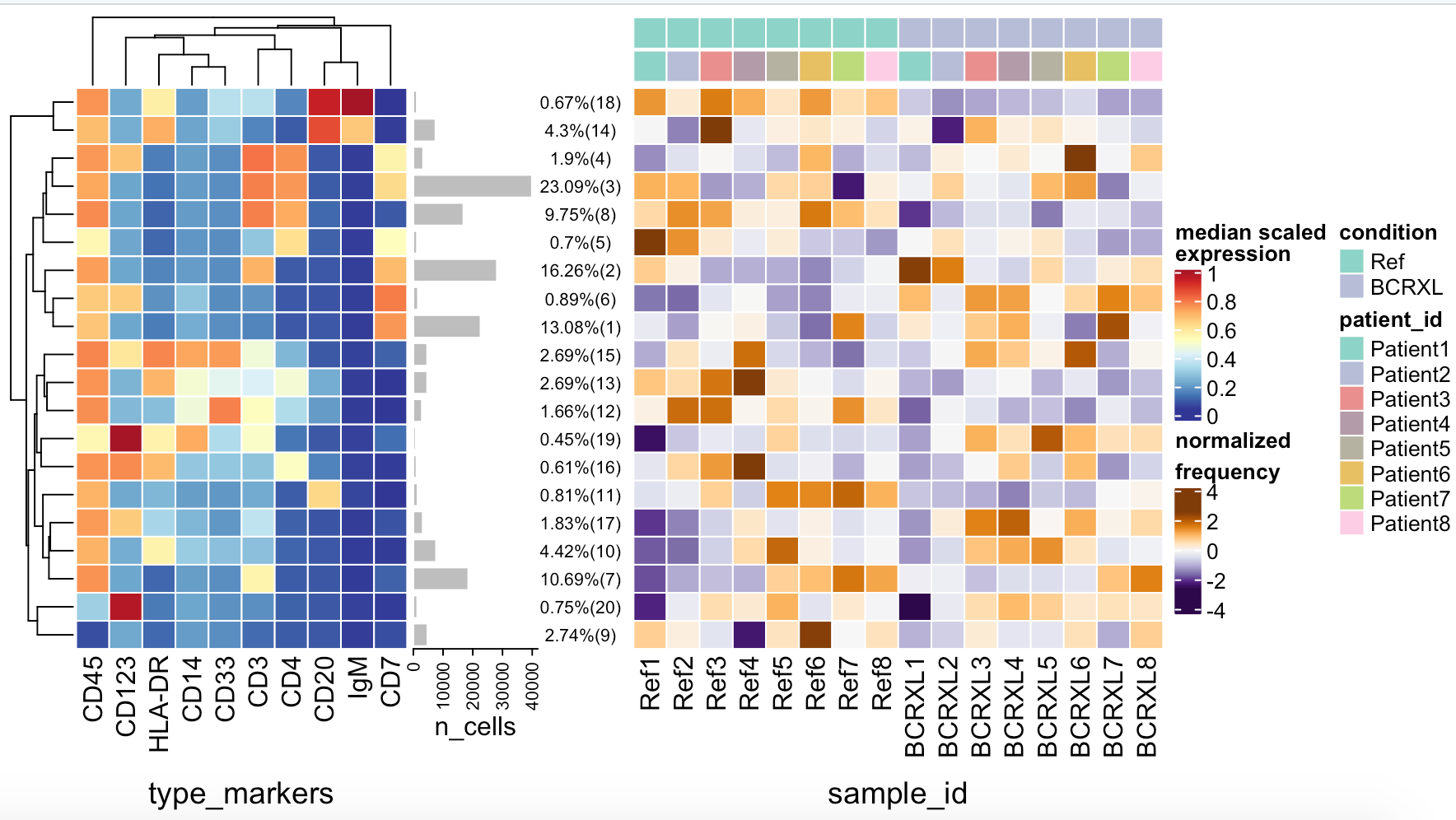
理论上不同的亚群肯定是有不一样的抗体信号,比如上图的第3和4亚群,都是高表达CD45,CD3,CD4以及CD7,毫无疑问都是CD4T细胞啦,但是它们也有细微差异,就是CD123啦。假如我们并不关心这么细的分群,就可以把它们都合并为CD4T细胞即可。
然后看看不同细胞亚群的空间分布情况
我们这里采用t-SNE/UMAP 两个方法来可视化,代码如下:
# 节约计算资源
# run t-SNE/UMAP on at most 500/1000 cells per sample
set.seed(1234)
sce <- runDR(sce, "TSNE", cells = 1e3, features = "type")
sce <- runDR(sce, "UMAP", cells = 1e3, features = "type")
# plotDR(sce, "UMAP", color_by = "CD4")
library(ggplot2)
p1 <- plotDR(sce, "TSNE", color_by = "meta20") +
theme(legend.position = "none")
p2 <- plotDR(sce, "UMAP", color_by = "meta20")
lgd <- get_legend(p2)
p2 <- p2 + theme(legend.position = "none")
plot_grid(p1, p2, lgd, nrow = 1, rel_widths = c(5, 5, 2))
ggsave2(filename = paste0(pro,'_umap_vs_tSNE.pdf'))
# facet by sample
plotDR(sce, "TSNE", color_by = "meta20", facet_by = "sample_id")
ggsave2(filename = paste0(pro,'_TSNE_by_samples.pdf'))
# facet by condition
plotDR(sce, "TSNE", color_by = "meta20", facet_by = "condition")
ggsave2(filename = paste0(pro,'_TSNE_by_condition.pdf'))
# facet by sample
plotDR(sce, "UMAP", color_by = "meta20", facet_by = "sample_id")
ggsave2(filename = paste0(pro,'_umap_by_samples.pdf'))
# facet by condition
plotDR(sce, "UMAP", color_by = "meta20", facet_by = "condition")
ggsave2(filename = paste0(pro,'_umap_by_condition.pdf'))
plotCodes(sce, k = "meta20")
pdf(paste0(pro,'_cluster_som100_plotMultiHeatmap.pdf'))
plotMultiHeatmap(sce,
hm1 = "type", k = "som100", m = "meta20",
row_anno = FALSE, col_anno = FALSE, bars = TRUE, perc = TRUE)
dev.off()
sce@metadata
plot_grid(labels = c("A", "B"),
plotDR(sce, "UMAP", color_by = "meta20"),
plotDR(sce, "UMAP", color_by = "meta8"))
plotAbundances(sce, k = "meta20", by = "sample_id")
ggsave2(filename = paste0(pro,'_plotAbundances_barplot.pdf'))
plotAbundances(sce, k = "meta20", by = "cluster_id", shape_by = "patient_id")
ggsave2(filename = paste0(pro,'_plotAbundances_boxplot.pdf'))
save(sce,file = 'K20_output_of_cytofWorkflow.Rdata')
首先看看采用t-SNE/UMAP 两个方法来可视化的区别
可以看到,t-SNE后所有的细胞更加饱满的分布在整个画布。但是UMAP呢,不同亚群的细胞距离被拉开了,更加突出了亚群与亚群之间的差异。
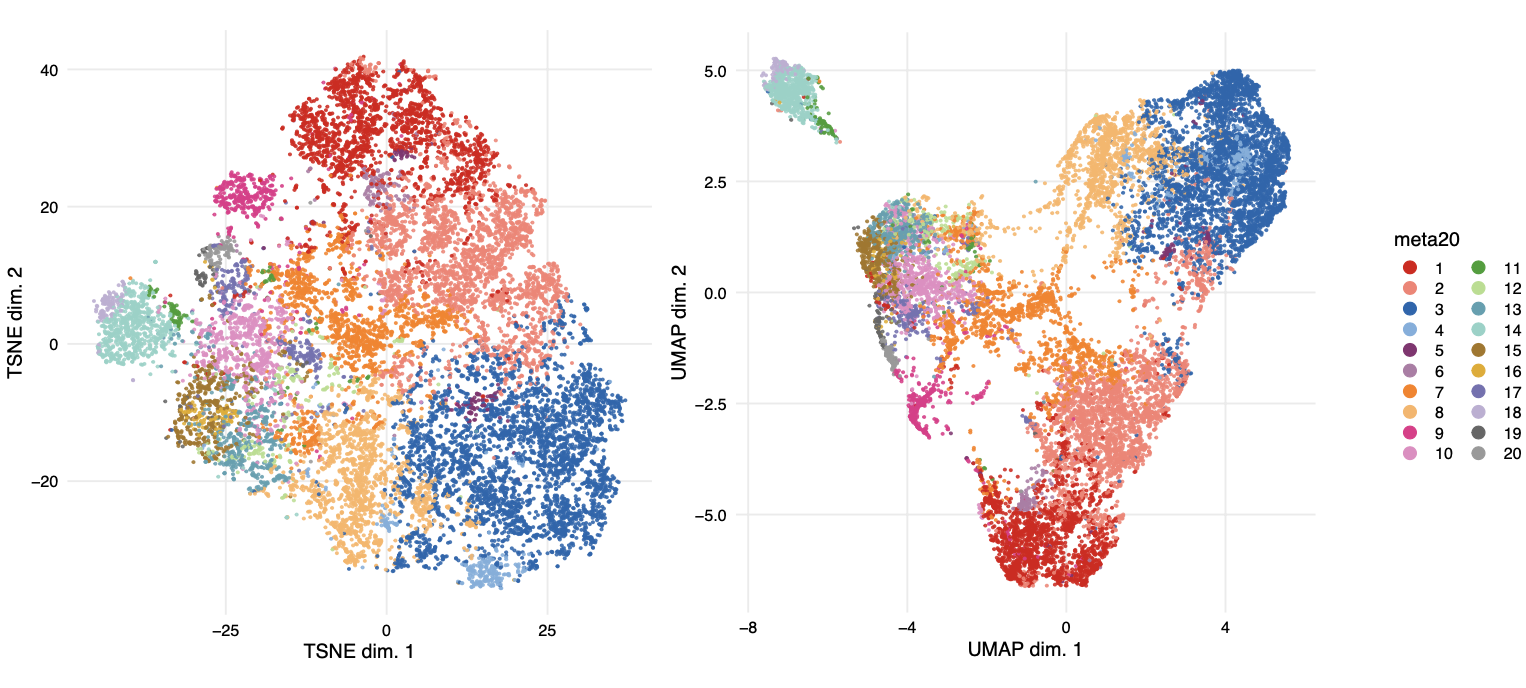
这个时候就完全是看个人爱好来进行展示了!
然后看看两个分组的细胞亚群差异
跟单细胞转录组类似的可视化方式:
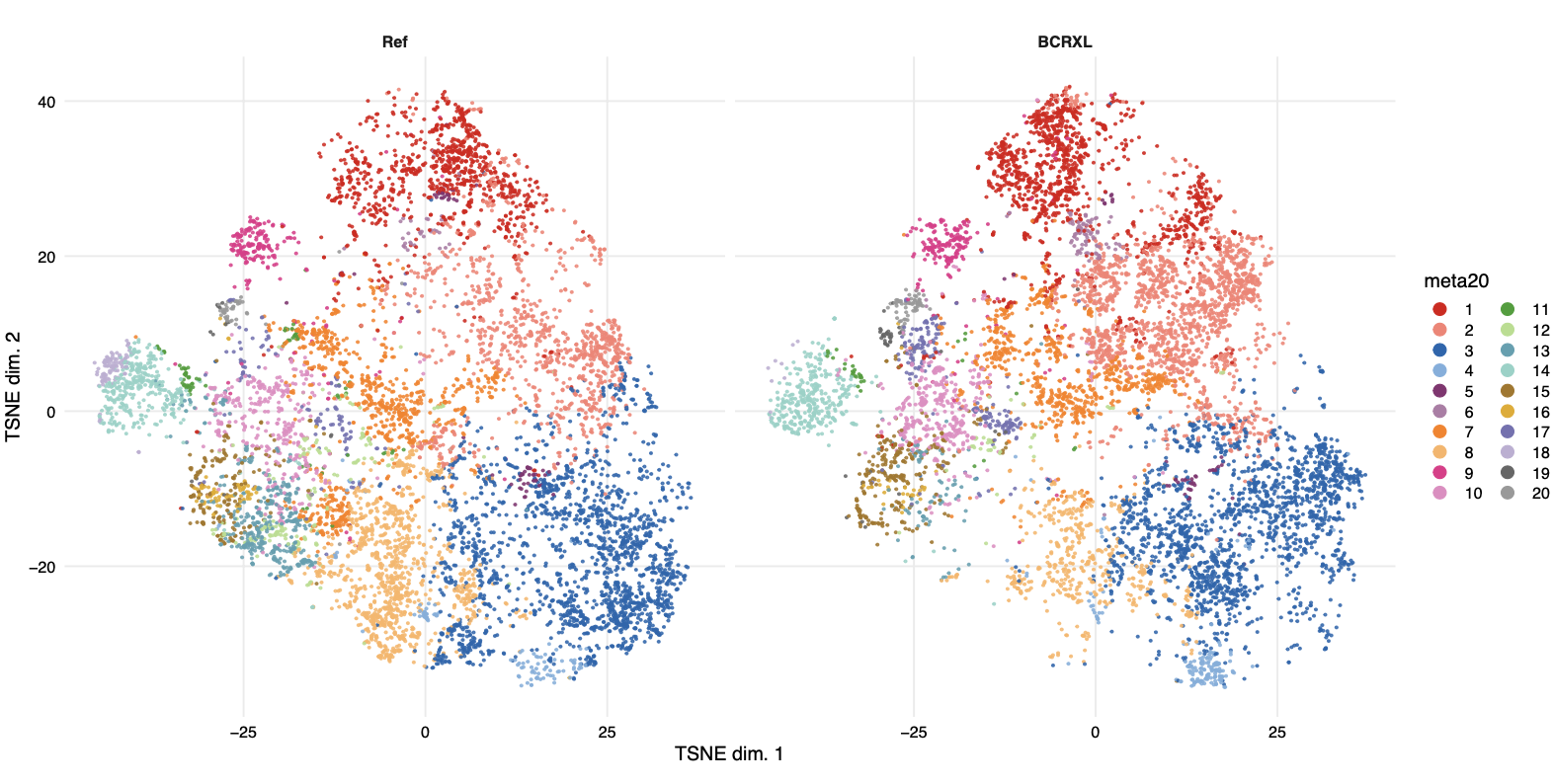
基本上很难看到细胞亚群比例差异,因为每个细胞亚群都有太多的细胞,也就是说,在图上面展现了太多的点。
直截了当的条形图看细胞亚群比例
每个病人的20个亚群细胞比例都展现出来,这个时候可以隐隐约约看到某一些细胞亚群在某一个组特异性的占比较高。
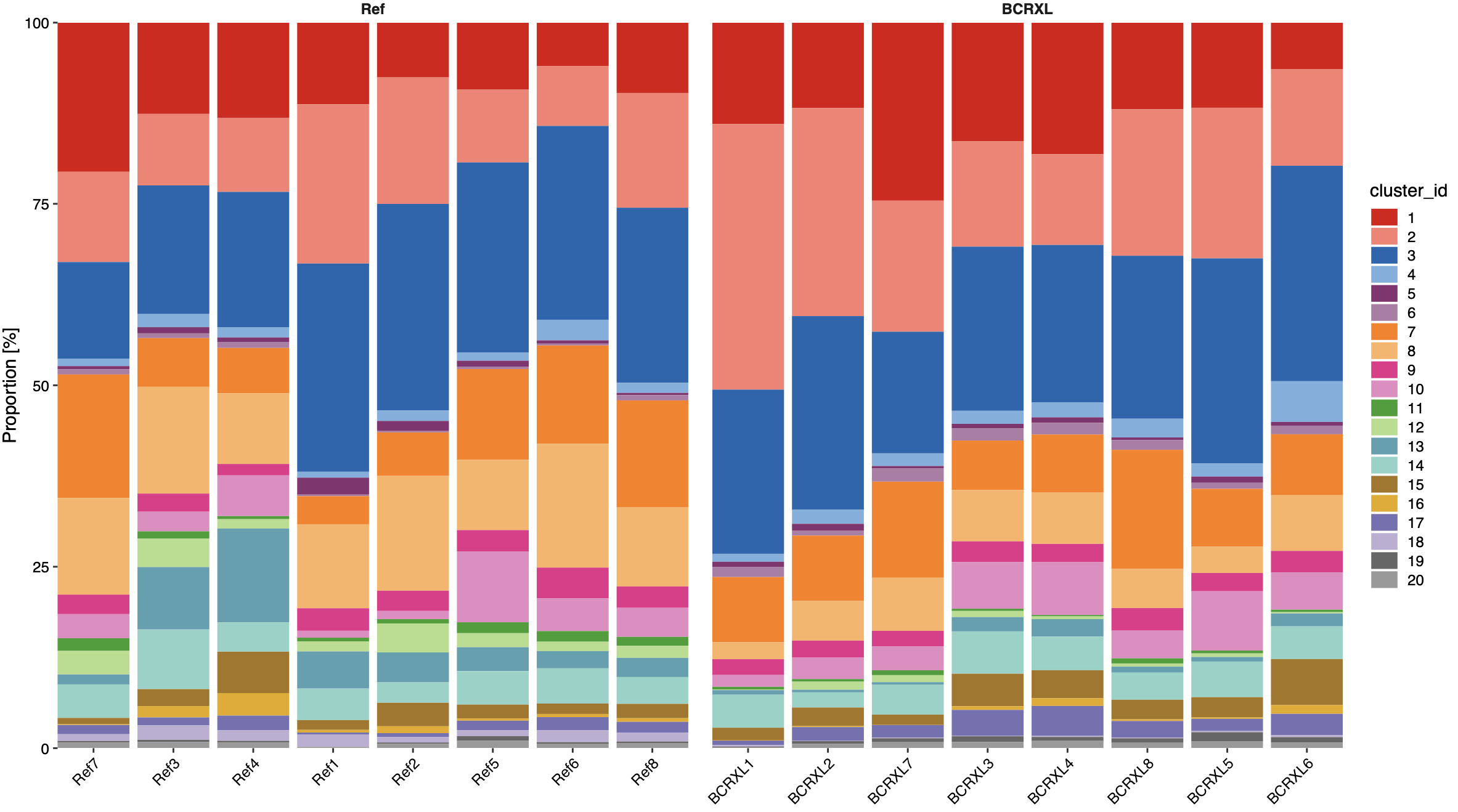
上面这个图在很多其它分析领域也出镜很多次了,比如看肿瘤的免疫微环境的各个免疫细胞比例等等。
直观的看细胞亚群比例的差异
这个时候进行分组检验,针对上面的条形图进行箱线图看差异。
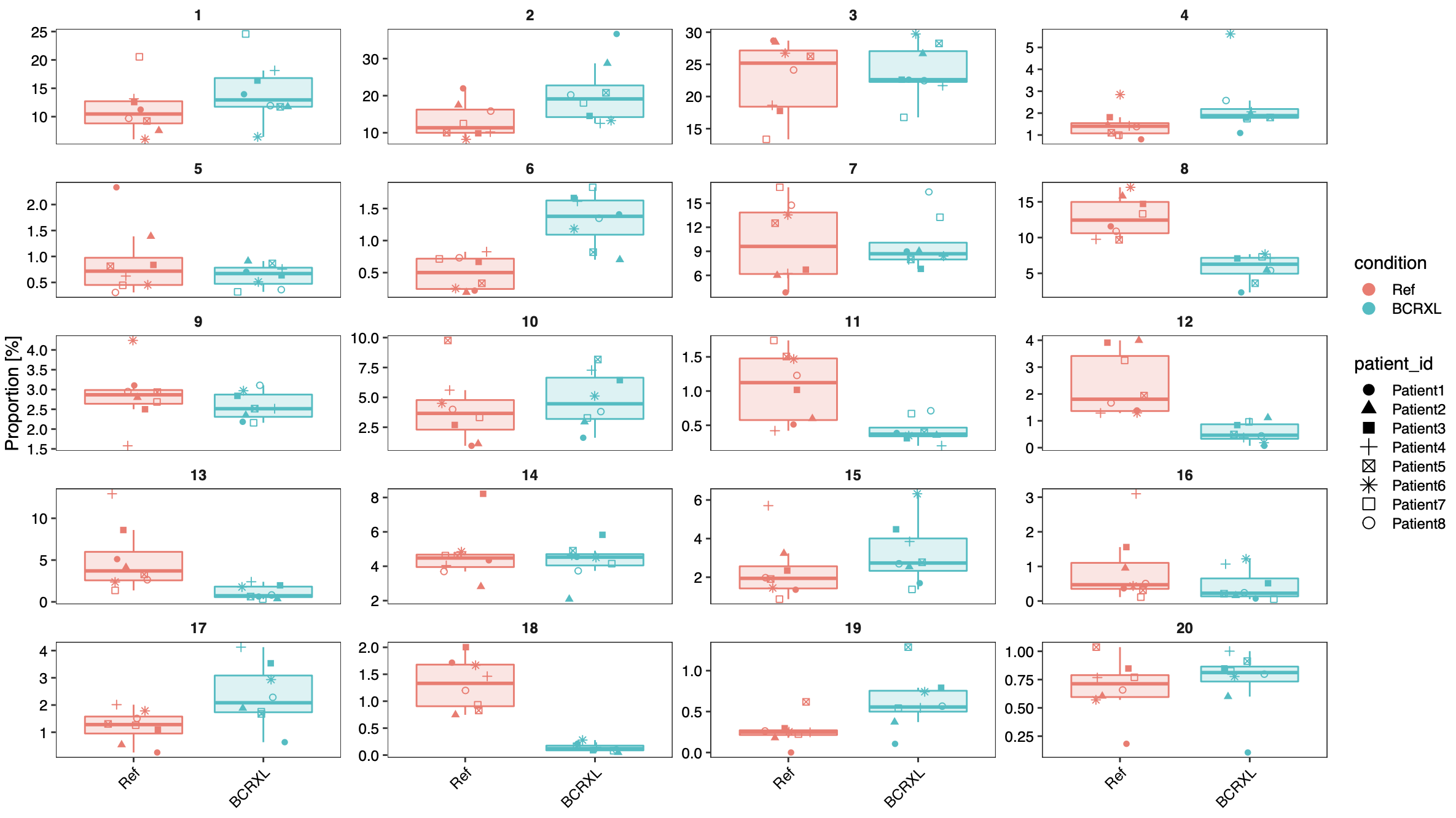
最后遗留下来的问题
可以看到,前面的代码我们在很随意的指定了20个细胞亚群,让程序走一个流程,先看看效果。这样的聚类分群是有监督的,并不是很好的反映出数据的特性!
后续分析,我们来一起把这20个细胞亚群根据生物学背景知识进行人工合并。