前面我们介绍了Oxford Nanopore Technologies(牛津纳米孔技术)公司的一些测序仪,也看到了它产出的测序数据,详见:全长转录组分析之牛津纳米孔测序介绍
现在一起来详细认识这样的数据吧!
Nanopore测序的下机数据的原始数据格式为包含所有原始测序电信号的二代fast5格式。通过MinKNOW2.2软件包中的Guppy软件进行base calling后会将fast5格式数据转换为fastq格式,用于后续质控分析。(通常测序服务商会给你fastq格式的数据结果)
上次我们提到对于ONT原始下机数据混样建库和非混样建库数据稍微有些区别。混样主要是需要凑够样本数达到一个上机lane的测序量,目前三代全长转录组一个样本基本产出2G就可以满足下游分析,因此,多属于混样建库测序。
对于一次下机的数据,文件如下:
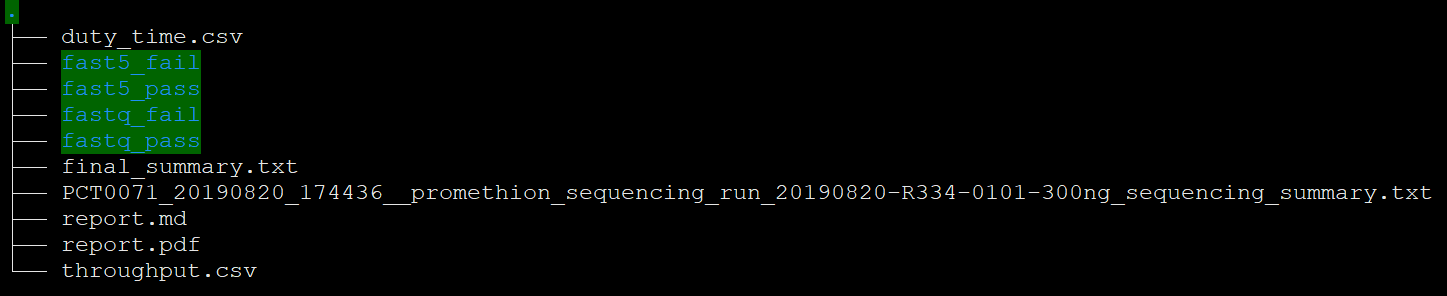
主要是看fast5和fastq文件:
- fast5:原始电信号文件,以.fast5为文件结尾。此文件既有测序得到的序列信息,还有甲基化修饰信息。经过basecall,MinKNOW2.2软件包中的Guppy软件可以将fast5文件转换得到fq文件,测序仪本身是带有这个basecall功能的。
- fastq:由fast5文件转换而来,以.fastq或.fq结尾,与二代格式一样,四行为一个单位,只不过序列要长很多,这是三代的一个优势。
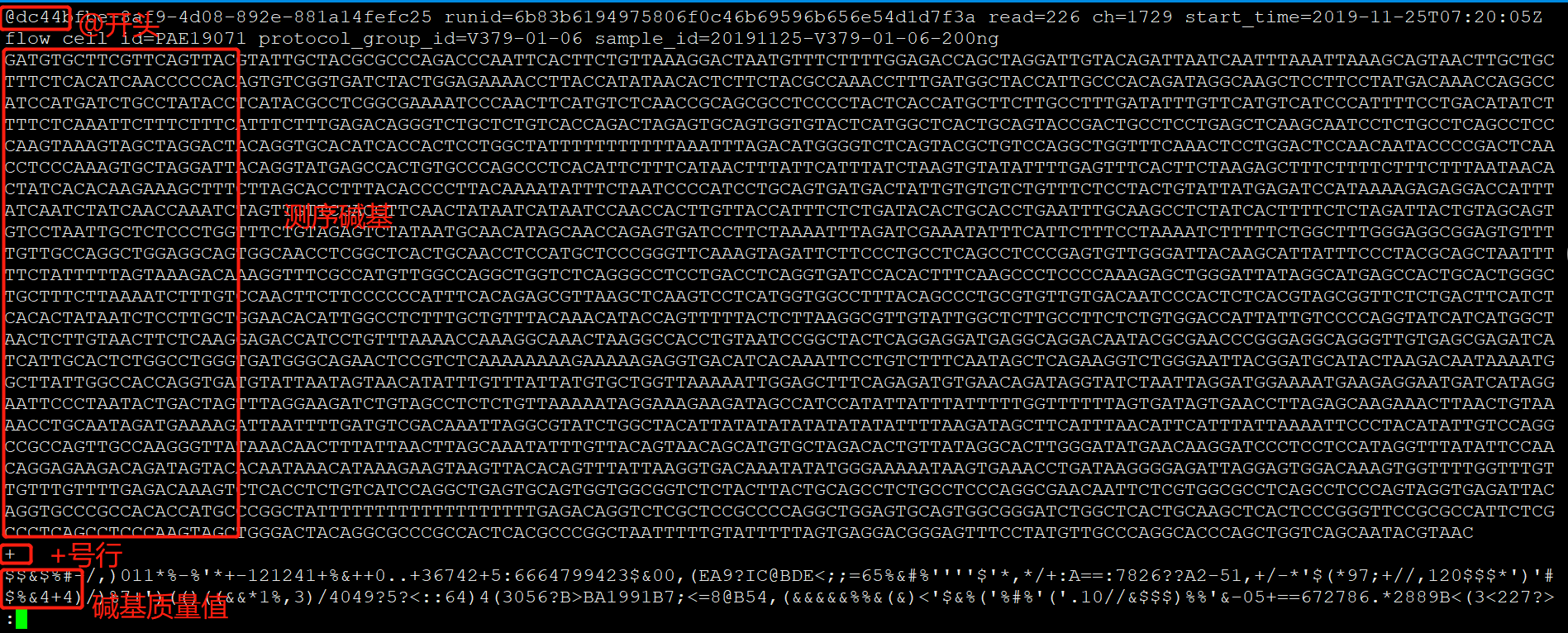
可以看到,测序的每个reads的碱基数量非常多!这里面的质量值,仍然是符合fastq格式的定义哦!
fail和pass文件夹是根据测序仪设置的一个指标比如Q值>7对数据进行的一个处理,fail代表指标没有达到这个标准,pass指通过了这个标准。 - final_summary.txt文件:
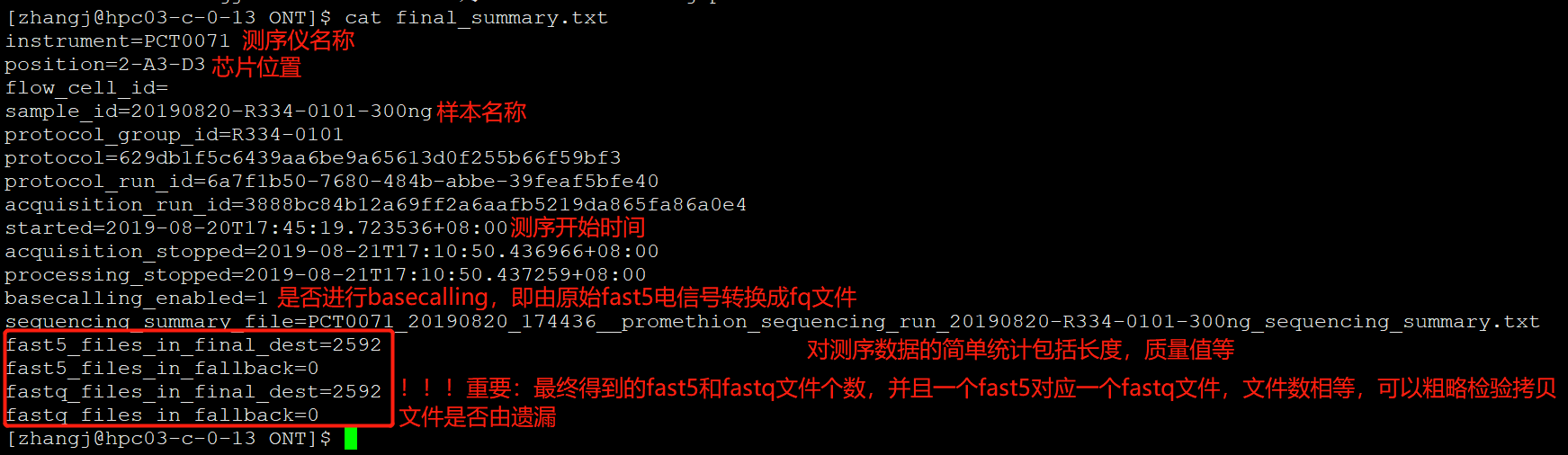
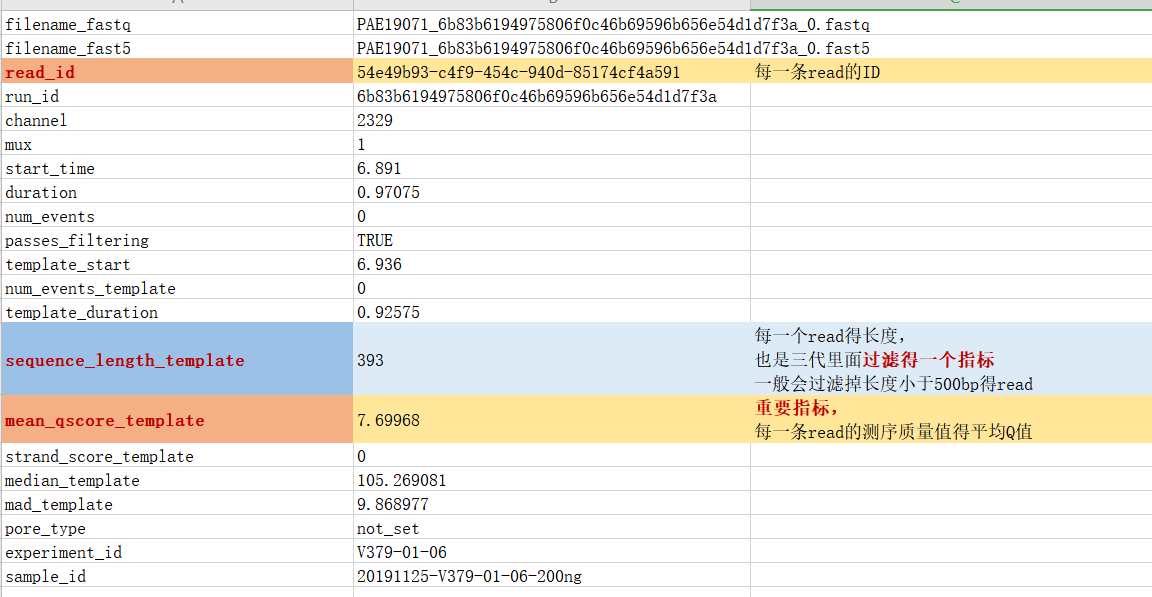
每个测序文件的汇总表,都需要仔细研读,好的数据作为开头,才有可能有好的分析结果。 - sequencing_summary.txt文件:主要存储了一些read长度,每个read的平均测序质量(MeanQscore)等信息,作为对数据进行长度,N50,MeanLength,MaxLenght等指标统计,后续过滤等用途。
此次专题主要学习和记录一些在分析ONT测序产品如ONT全长转录组,ONT甲基化以及ONT重测序中的所思所想所得。
个人所知有限,如有理解错误,还请批评指正。下期将介绍:
- 数据过滤标准
- 一般初步会对数据做哪些指标统计
- 如何评价这个数据质量
文末友情宣传
强烈建议你推荐给身边的博士后以及年轻生物学PI,多一点数据认知,让他们的科研上一个台阶:
- 全国巡讲全球听(买一得五)第3期(4月6日开始) ,你的生物信息学入门课。
- 数据挖掘线上班来袭(两天变三周,实力加量),医学生/医生首选技能提高课。
- 生信技能树的2019年终总结 ,你的生物信息学成长宝藏
- 2020学习主旋律,B站74小时免费教学视频为你领路