前面我们在单细胞天地分享了:4千万科研经费告诉你什么是生物学研究的热点 ,其实毫无悬念,必须滴单细胞的热点!不过,热点并不意味着有经费就是CNS文章,也有一些几百万砸下去,然后就普普通通发出去的。大家可以在文末留言推荐分享这样的例子。
最近有粉丝提到是否可以把多个样本混杂到一起建立一个10X单细胞转录组库进行测序后数据分析,的确是有这样的例子,比如我前些天在Twitter看到的发表在Nephrology Dialysis Transplantation 的文章, https://doi.org/10.1093/ndt/gfz227 题目是:A single-cell map for the transcriptomic signatures of peripheral blood mononuclear cells in end-stage renal disease 就是这样。
实验设计非常简单
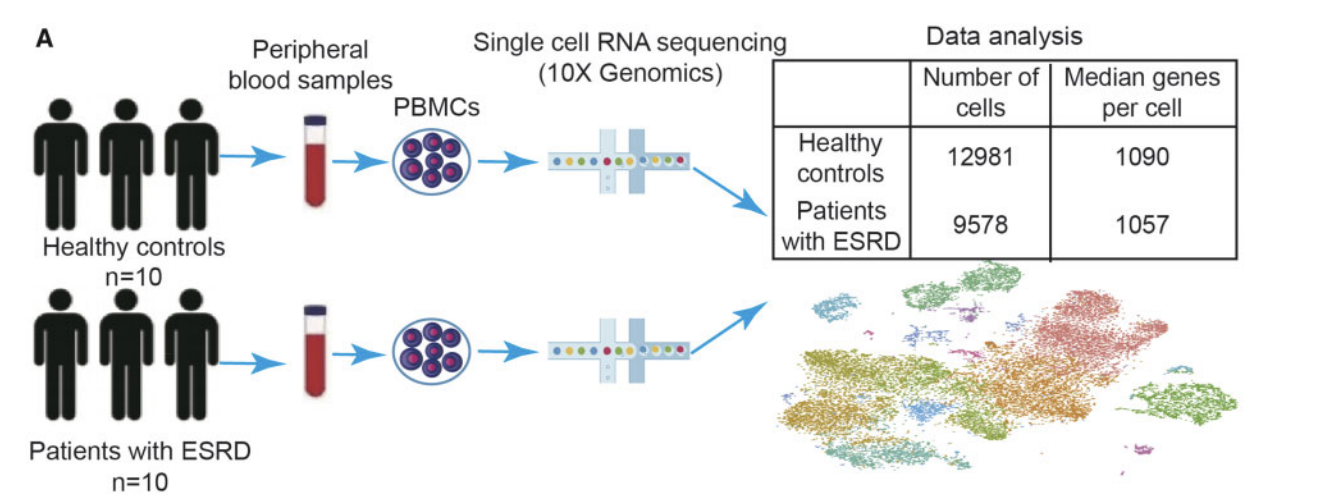
就是10个ESRD病人,10个正常人志愿者的血液,提取PBMC进行10X仪器的单细胞转录组数据而已。值得注意的是,其中研究团队就做了两个10X哦,也就是说他们把10个ESRD病人混合成为一个样品,10个正常人志愿者也混合成为一个样品。
下面的流程图写的很清楚具体细胞数量,平均检测到的基因数量是1000,每个样品检测到1万个左右的细胞数量,都符合10X仪器的技术水平。
而且,可以看到,分析其实仍然是我们一直讲解的R包及基础流程,分别是: scater,monocle,Seurat,scran,M3Drop 需要熟练掌握它们的对象,:一些单细胞转录组R包的对象 流程也大同小异:
- step1: 创建对象
- step2: 质量控制
- step3: 表达量的标准化和归一化
- step4: 去除干扰因素(多个样本整合)
- step5: 判断重要的基因
- step6: 多种降维算法
- step7: 可视化降维结果
- step8: 多种聚类算法
- step9: 聚类后找每个细胞亚群的标志基因
- step10: 继续分类
其中一个步骤是判断重要的基因,我分享过:比较5种scRNA鉴定HVGs方法 里面就提到了 。这样的分析跟CIBERSORT推断免疫组成有啥区别呢
我昨天就在生信技能树分享了这个观点;表达矩阵数据的免疫环境组成分析可以是标配 反正对bulk的转录组表达矩阵,是可以通过算法,比如CIBERSORT来推断免疫组成的。而本研究也就是对细胞分群后进行注释,然后看看不同亚群的免疫细胞的比例变化。
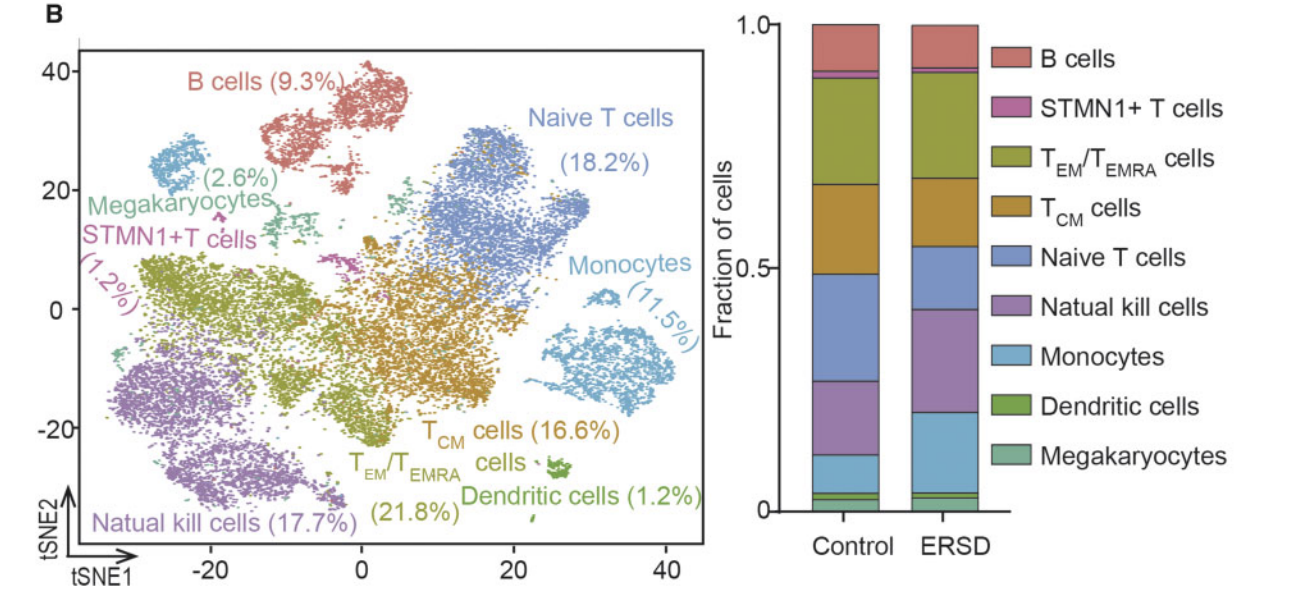
又或者,既然是纯粹地看免疫细胞的各种比例,其实跑一个流式细胞仪看看就好了,单细胞转录组有点高射炮打蚊子的感觉。不过,反正就2个10X样品,成本也很低,无所谓啦。然后研究者单独看某一群细胞继续细分
因为本研究设计非常简单,就一个变量,就是10 healthy volunteers and 10 patients with ESRD ,所以主要的分析都是围绕这个变量来进行。既然已经定位到了健康人和疾病组的差异细胞群,就可以继续把该群细胞细分,然后具体看某个亚群的表达差异。
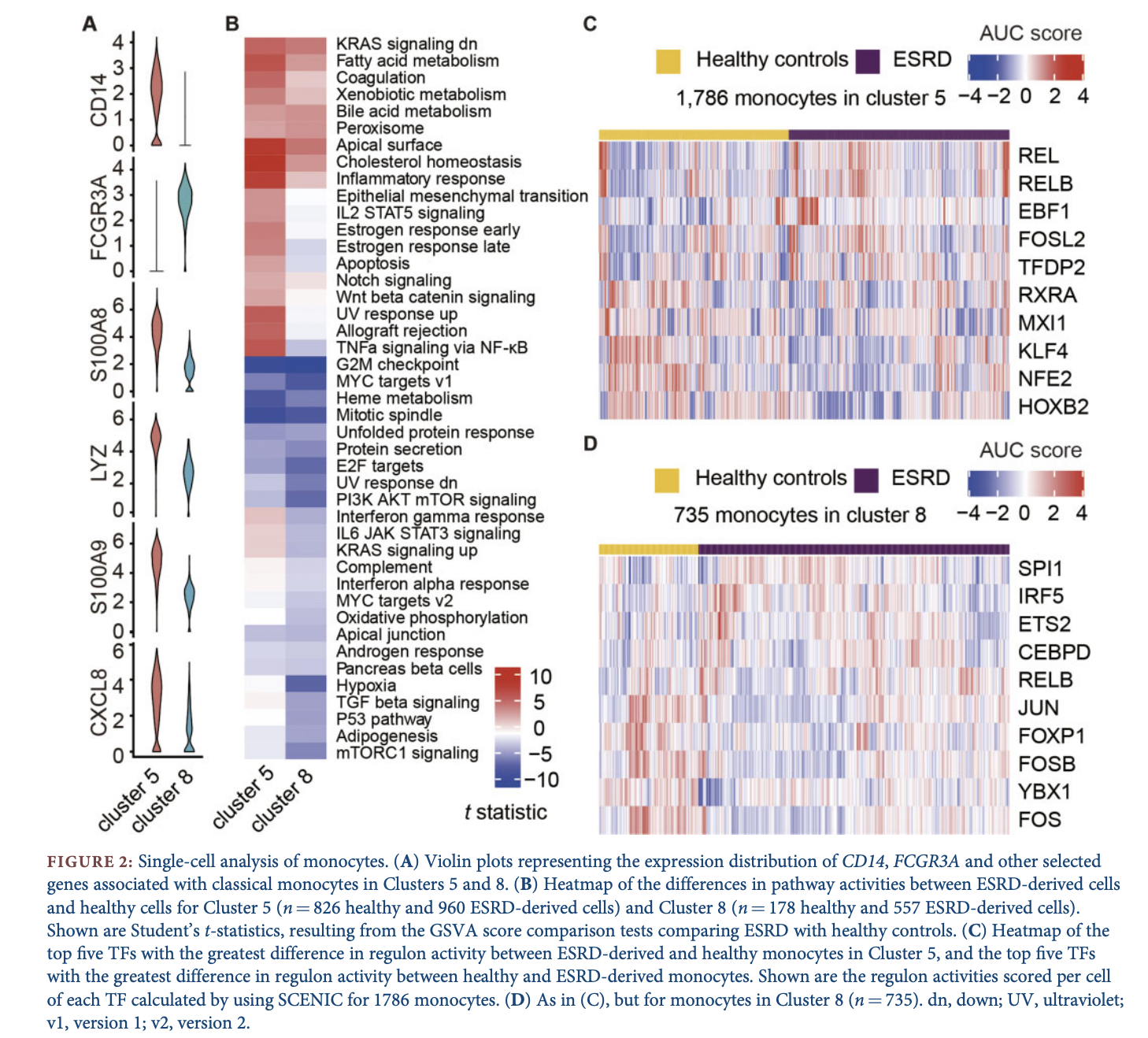
如果你测了单细胞实在是不知道如何深入分析
其实,也许,早点发出去是最好的策略吧。总比很多文章最后都无法发出去的要好!
这样,你的数据公布出来,说不定其他朋友看到了,一个简单的数据挖掘,如果你想致谢生信技能树
其实在:基因类型注释根据基因ID就好了 里面有官方致谢!