关于表达芯片的公共数据库挖掘我这边以及差不多把改写的推文在2年前就写完了,但表达芯片毕竟只占芯片市场的半壁江山,还有大量的非表达芯片,比如大名鼎鼎的甲基化芯片。关于甲基化,我们公众号教程非常少,主要是因为我本人在短暂的6年生物信息学工作经验中并没有实际负责过这样的项目,而我们公众号90%教程都是我写的,极少的投稿里面,只有 [850K甲基化芯片数据的分析](http://mp.weixin.qq.com/s?__biz=MzAxMDkxODM1Ng==&mid=2247485301&idx=1&sn=bd9b9f08d0fcbf69fa6096815abe0b08&scene=21#wechat_redirect) 让我印象深刻,所以我的学徒也是跟着这个教程在学习甲基化芯片数据处理。
但是学徒反馈说这个教程没有提到芯片的探针如何注释到基因,所以就安排他做了这个补充,下面让我们看学徒的表演!
甲基化芯片背景
甲基化芯片原理:https://www.jianshu.com/p/c4f758e0399d
芯片主要分为EPIC和450k两种,EIPC也就是850k,两种探针的都是以cg开头的数字编号,所谓注释也就是提取这些探针的所对应的信息,例如,探针序列的CpG位置信息,对应的基因信息,染色体上的位置信息,等等。很多包在安装的时候都会自动下载这些注释信息,并包装在一起,如果我们想要自己注释这些探针,就要考虑如何获取独立的注释信息。而所需要注释数据的,大部分都来自于两个数据库,GEO和TCGA。
下面介绍三种提取注释信息的方法
# 方法一:从UCSC Xena下载
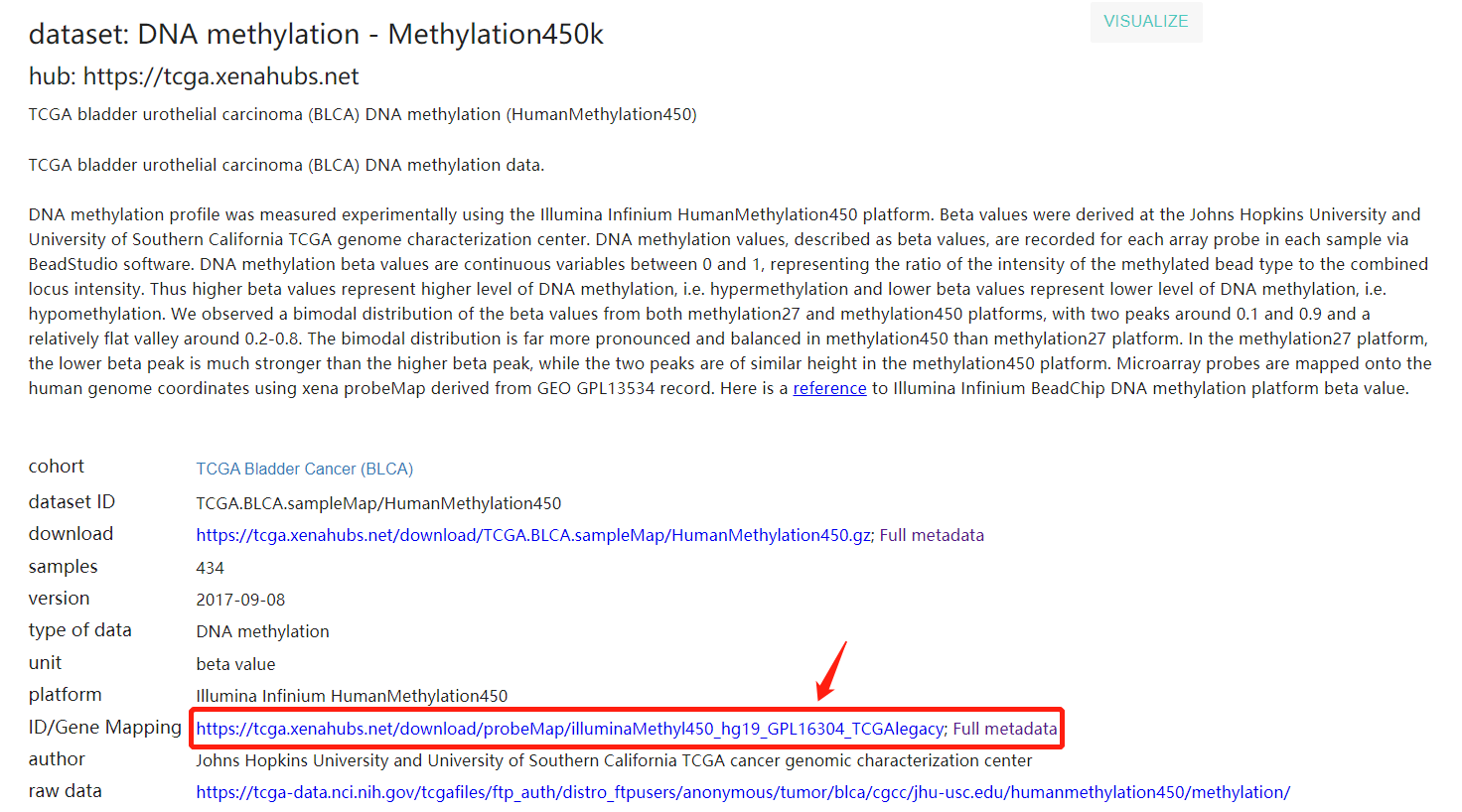
直接从UCSC Xena相应的癌症甲基化数据库里下载对应的文件。可以看到是来自GPL16304平台的芯片,其实和下面要介绍的从GEO下载注释信息是一样的,不过TCGA的探针数可能会少于45w,大约39w,因为提前过滤了一些低质量的探针。
# 方法二:从GEO下载对应平台的注释文件
在GEO的官网platform下搜索Illumina HumanMethylation450,可以看到450k的芯片主要来自三个平台,探针数也是不一样的,TCGA中下载时一般都会标明来自那个平台,从GEO中下载数据都会得知平台的信息。直接进入对应平台的介绍就可以了。
看一下最常见的GPL13534平台的内容
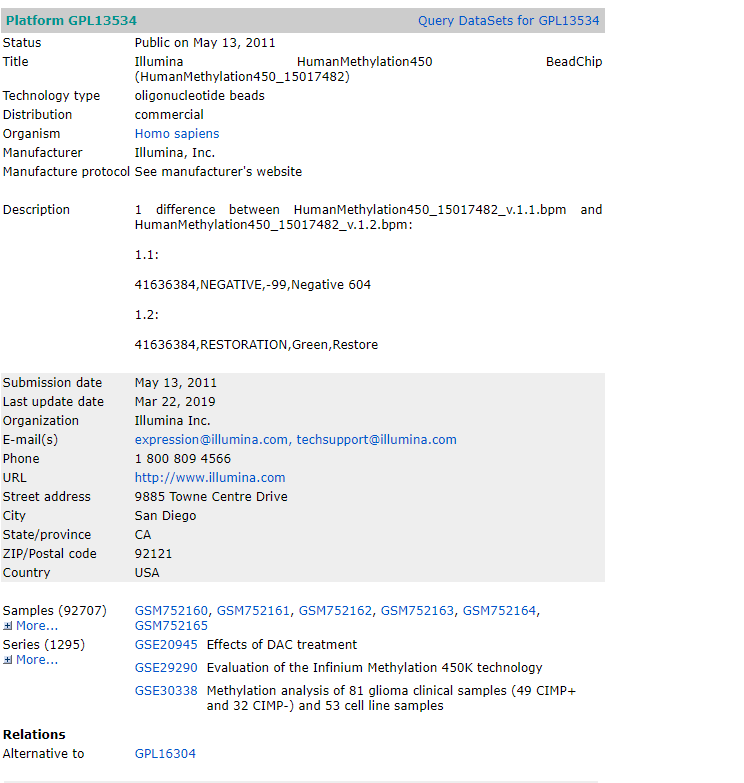
可以看到有1295个GSE来自这个平台,可以利用的数据相当多,这里给出了一部分数据的概览
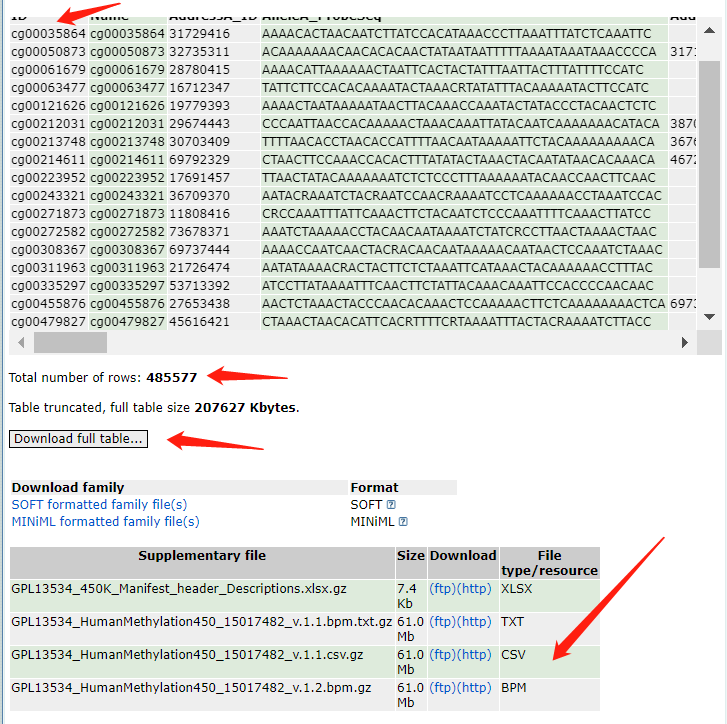
表格中展示了部分信息,直接下载然后就可以提取我们需要的注释信息了,485577个探针一个不差,可能是因为我网速的问题,只有下载CSV这个的时候速度比较快,其他速度都非常感人

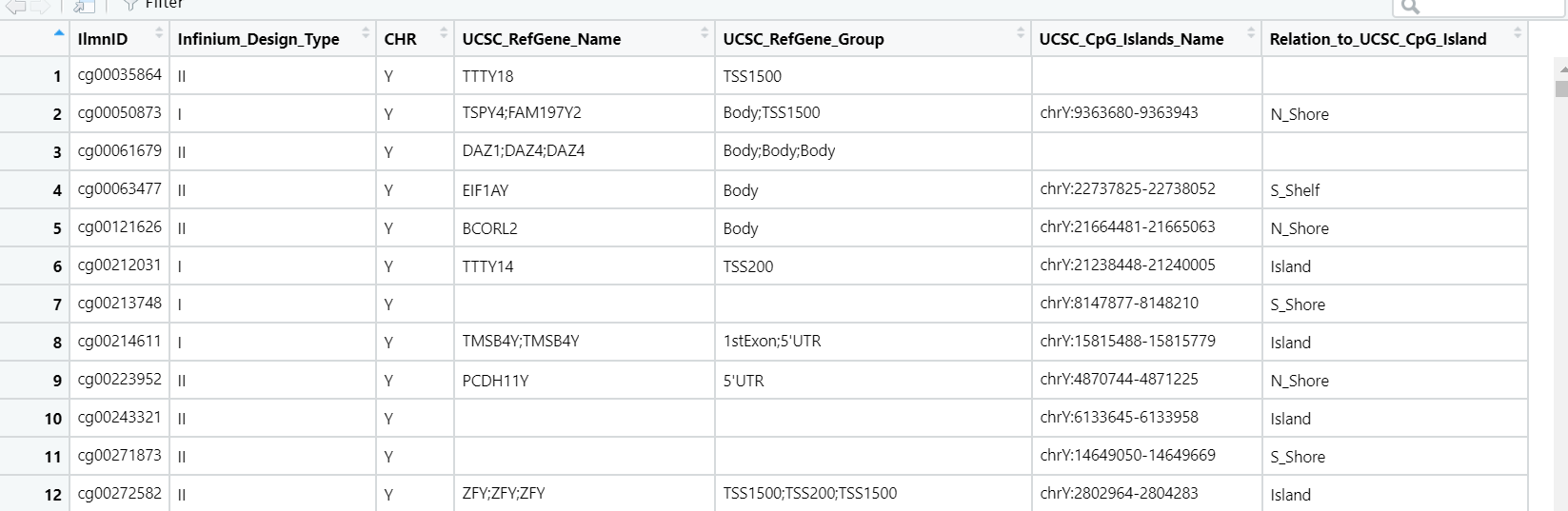
可以看到信息非常全面了,但实际上我们并用不到这么多,有下面这些就够了
ids<-a[,c("IlmnID",
"Infinium_Design_Type",
"CHR",
"UCSC_RefGene_Name",
"UCSC_RefGene_Group",
"UCSC_CpG_Islands_Name",
"Relation_to_UCSC_CpG_Island")]
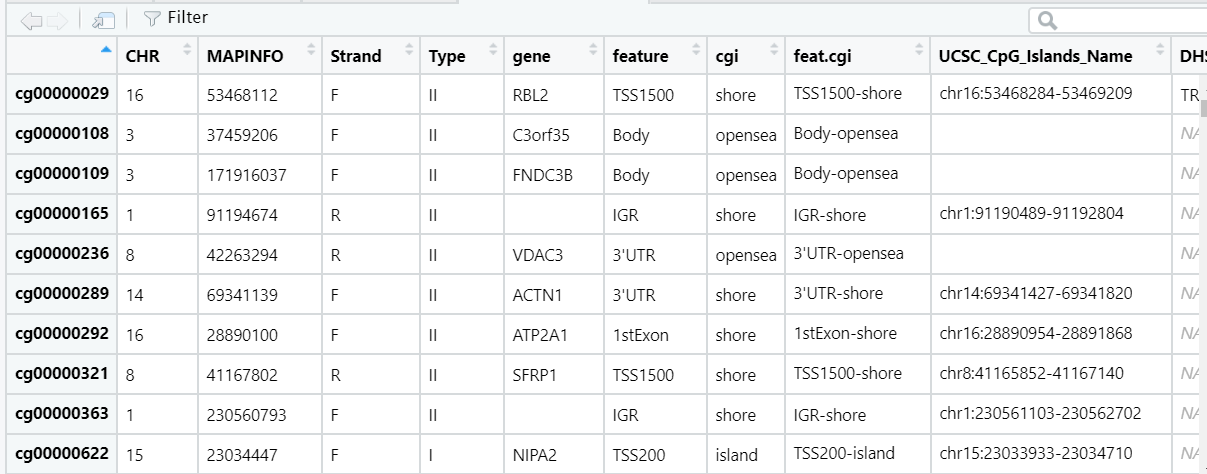
#可以看到,包含了探针的名称,探针类型(可用来去批次),染色体编号,对应的基因名,在染色体上的位置信息,以及与CpG岛的位置信息,这样就可以注释差异的探针了
# 方法三:从ChAMP包中提取
这个方法严格来说其实是从ChAMP依赖的两个注释包中提取的,但是我又懒又笨,懒得看原始的包里数据藏在哪里了,ChAMP包在做甲基化分析的时候也很方便,而其中champ.filter函数直接就提取好了
myimport <- champ.import(directory=system.file("extdata",package="ChAMPdata"))
myImport=myimport#包里的演示代码有个小细节错了,没有区分大小写,无伤大雅的
myfilter <- champ.filter(beta=myImport$beta,pd=myImport$pd,detP=myImport$detP,beadcount=myImport$beadcount)
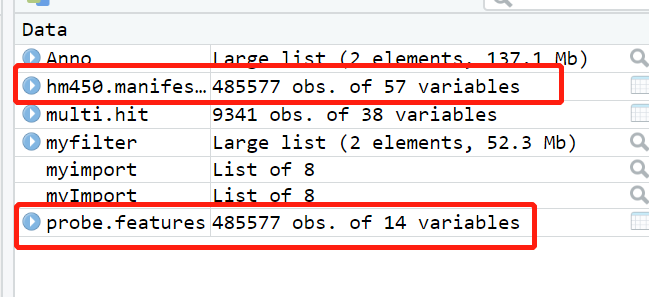
View(hm450.manifest.hg19)
View(probe.features)#两个信息是一样的,包已经把我们需要的信息自动提取了
850k和450k本质上没有什么区别,所以方法都是通用的。
写在后面
以上教程,来自于2019年9月份学徒,谢谢大家观看!
实际上,芯片探针如果有坐标,也可以参考:对bed格式的基因组区间文件进行基因注释
表达芯片的公共数据库挖掘系列推文感兴趣的也可以去看看;