为了分析不同类型、组织起源肿瘤的共性、差异以及新课题。TCGA于2012年10月26日-27日在圣克鲁兹,加州举行的会议中发起了泛癌计划。参考:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6000284/ 为此我也录制了系列视频教程在:TCGA知识图谱视频教程(B站和YouTube直达)
本文发表的杂志还算中规中矩啦,在Nat Commun. 2013,题目是:Inferring tumour purity and stromal and immune cell admixture from expression data. 本研究者开发了一个基于表达信息的肿瘤纯度判定算法,Estimation of STromal and Immune cells in MAlignant Tumours using Expression data’ (ESTIMATE) 主要是基于ssGSEA,对 stromal and immune 两个基因集进行打分。文献解读属于100篇泛癌研究文献系列,首发于:http://www.bio-info-trainee.com/4132.html
这个ESTIMATE算法的引用还不错, 接近500次了,很多后续的公共数据库挖掘都采用它来对癌症进行分组比较。
算法流程
在数据集 GSE1133 里面,根据 造血细胞和其它细胞的差异分析,得到 上下调的基因集。
然后引入 leukocyte methylation signature score 概念把TCGA计划的OV数据集进行分组,再次找差异基因。
然后有3个数据集用到了 laser-capture microdissection 技术 研究 stroma-forming cells ,是:
- ovarian cancer (GSE9890),
- breast cancer (GSE14548)
- colorectal cancer (GSE35602)
如下:
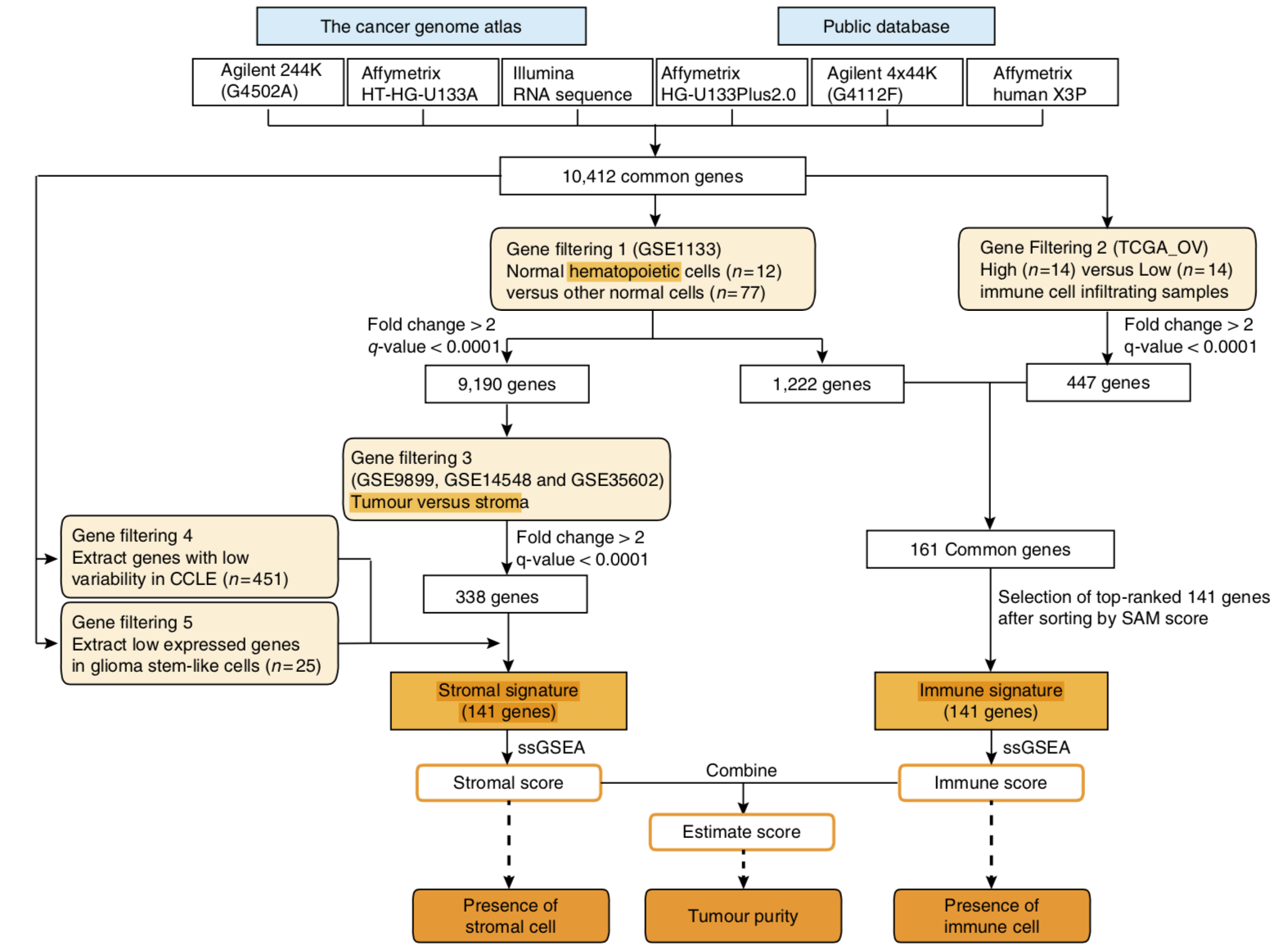
关于stromal基因集
前面步骤得到是338个基因,有点多,作者还添加了两个过滤步骤:
- 只保留在CCLE数据库的451个样本的MAD < 0.5的 那些表达比较稳定的基因
- 提取在GBM里面低表达的基因
关于immune基因集
主要就是TCGA计划的OV数据集根据 leukocyte methylation signature score进行分组后的差异基因。
GEO公共数据集验证
有了算法,很容易在表达数据集里面进行计算,复现下面的图:
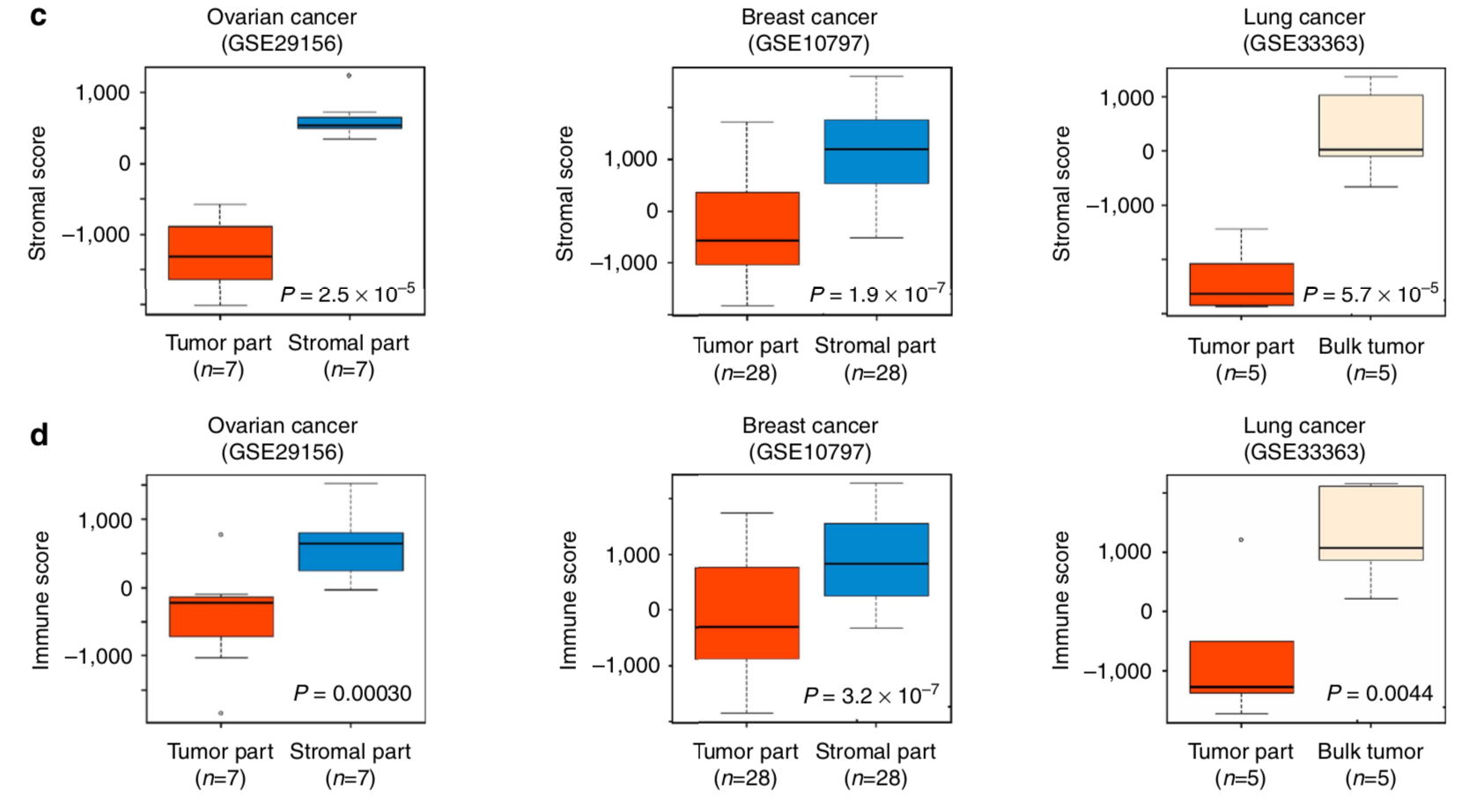
TCGA数据集验证
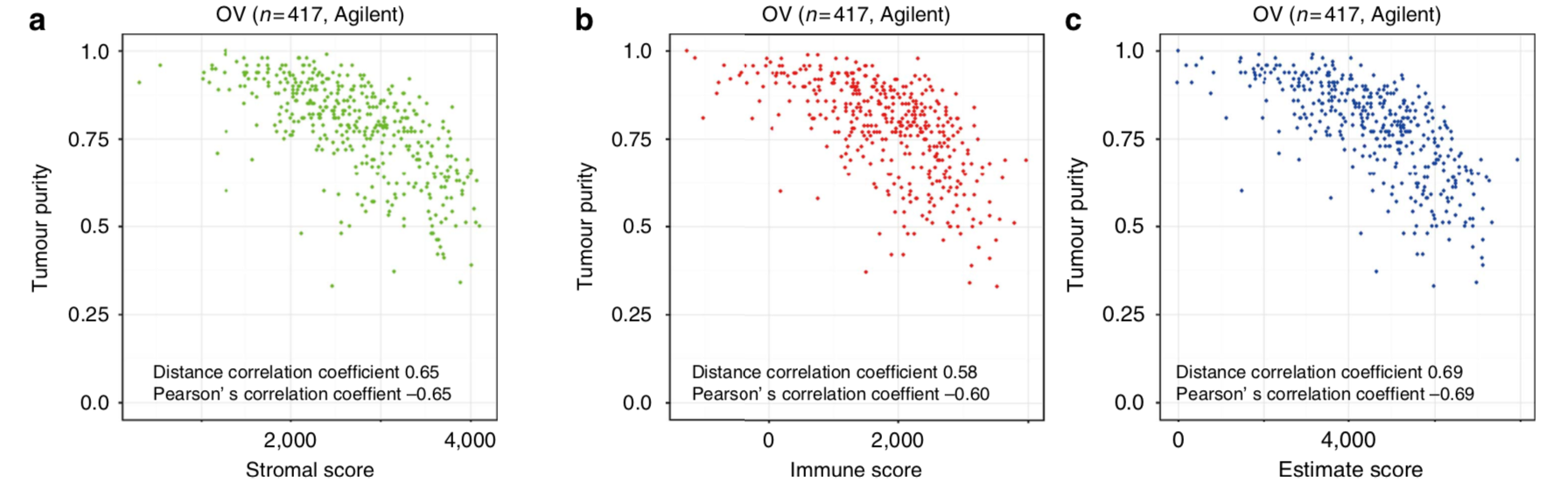
这里作者主要选择的OV,计算结果很容易看到作者提出的算法的指标都是跟肿瘤纯度相关性很高
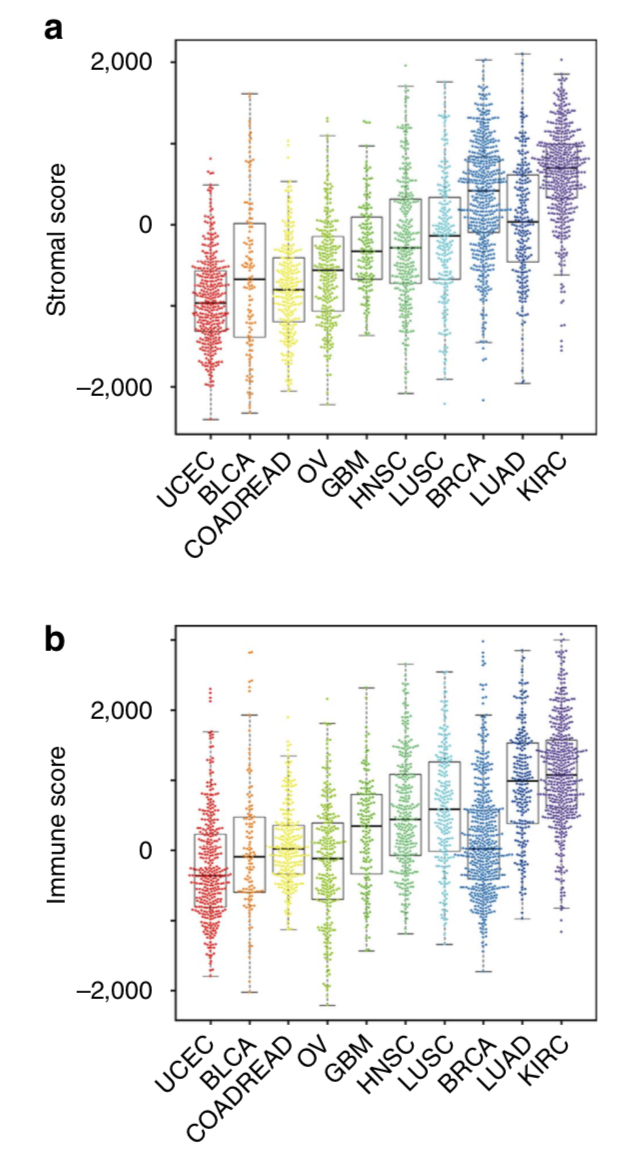
在其它癌症数据集里面验证效果也大同小异,非常好的表现。pan-cancer的表现
主要是计算两个score后看分布情况
后记
从流程图来看,本研究并不复杂,也很容易复现出来, 关键是如何提出还有如何挑选数据集。
本文献解读属于100篇泛癌研究文献系列,首发于:http://www.bio-info-trainee.com/4132.html