这是一个终极命令,比写什么爬虫简单多了
wget -c -r -np -k -L -p -A.pdf --http-user=CS374-2011 --http-passwd=AlgorithmsInBiology http://ai.stanford.edu/~serafim/CS374_2011/papers/
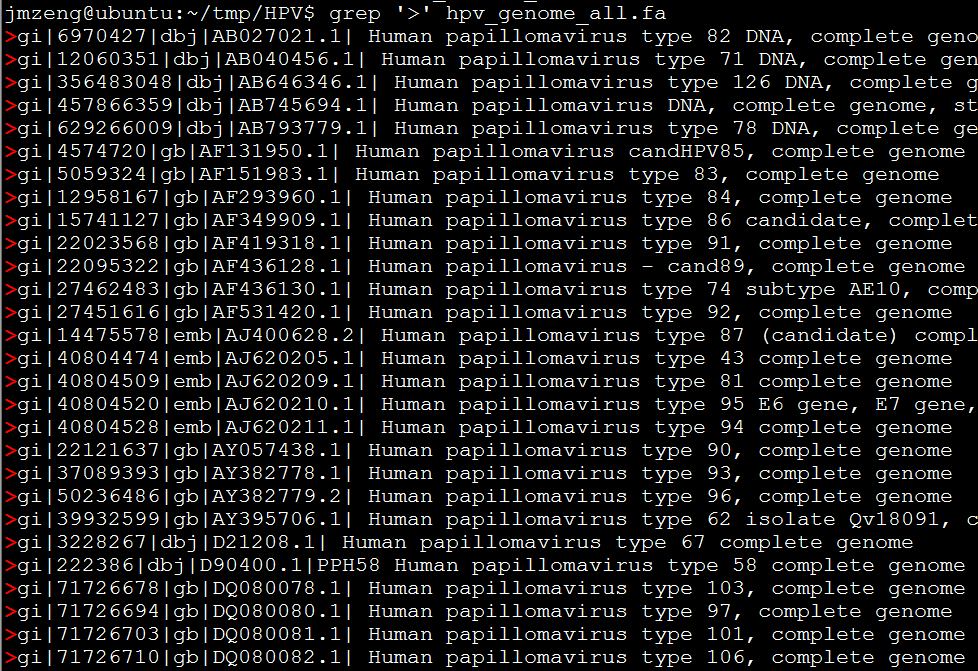
我这里的例子是斯坦福大学的生物信息学算法课程里面推荐阅读的的所有pdf格式的paper
课程的网址是:http://ai.stanford.edu/~serafim/CS374_2011/
可以看到,这个网站推荐的文献分成8大类,本身这个网站打开就需要登录用户名和密码
--http-user=CS374-2011 --http-passwd=AlgorithmsInBiology
每一篇文献的单独地址是http://ai.stanford.edu/~serafim/CS374_2011/papers/Miscellaneous_topics/Self-assembly_of_DNA/self_healing_and_proofreading.pdf 类似的格式。
我这里简单解释一下这些参数的意思:
-c -r -np -k -L -p -A.pdf
-c 断点续传
-r 递归下载,下载指定网页某一目录下(包括子目录)的所有文件
-nd 递归下载时不创建一层一层的目录,把所有的文件下载到当前目录(特殊要求会选择这个参数)
-np 递归下载时不搜索上层目录,如wget -c -r www.xxx.org/pub/path/
没有加参数-np,就会同时下载path的上一级目录pub下的其它文件 (所以一定要加上这个参数,不然会下载太多东西的)
-k 将绝对链接转为相对链接,下载整个站点后脱机浏览网页,最好加上这个参数
-L 递归时不进入其它主机,如wget -c -r www.xxx.org/
-r 递归下载,下载指定网页某一目录下(包括子目录)的所有文件
-nd 递归下载时不创建一层一层的目录,把所有的文件下载到当前目录(特殊要求会选择这个参数)
-np 递归下载时不搜索上层目录,如wget -c -r www.xxx.org/pub/path/
没有加参数-np,就会同时下载path的上一级目录pub下的其它文件 (所以一定要加上这个参数,不然会下载太多东西的)
-k 将绝对链接转为相对链接,下载整个站点后脱机浏览网页,最好加上这个参数
-L 递归时不进入其它主机,如wget -c -r www.xxx.org/
-p 下载网页所需的所有文件,如图片等
-A 指定要下载的文件样式列表,多个样式用逗号分隔
-A 指定要下载的文件样式列表,多个样式用逗号分隔
至于最后的--http-user=CS374-2011 --http-passwd=AlgorithmsInBiology 就是登录该课程网站需要的用户名和密码