单细胞转录组交流群有小伙伴鞭尸了这样的一个单细胞文章,标题是:《Single-cell multiomics revealed the dynamics of antigen presentation, immune response and T cell activation in the COVID-19 positive and recovered individuals》,我看了看,是 December 2022 发表,并不算是很老的单细胞转录组数据集。可以看到该文献的数据集链接是:https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE201088
是 人的PBMC样品,Healthy (n = 4), COVID-19 (n = 16) and recovered (n = 13) ,这个单细胞转录组技术起初看起来是很高级 ,是BD single cell multiplexing kit (Human) ,包括:
- a pool of 40 oligo-attached antibody for surface markers (Ab-Seq).
- A poly-A transcripts library (WTA), Ab-Seq library and library from oligos of Sampe multiplexing kit (SMK)
然后,我看了看文章里面的降维聚类分群结果, 真的是一言难尽啊!
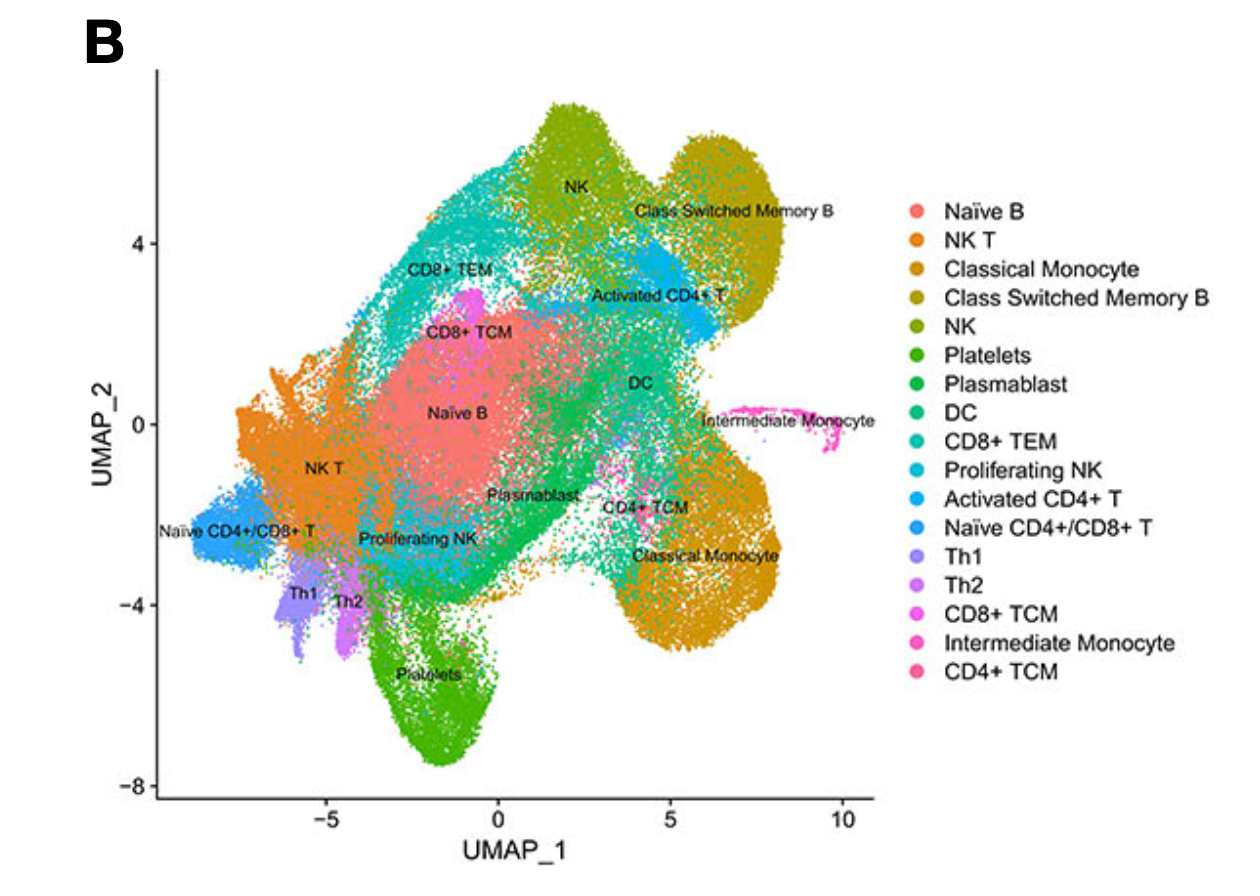
图例很清楚,是 (B) UMAP visualization of the 124726 cells across the healthy, active COVID-19 and the recovered individuals.
但是如果你仅仅是从它文章里面的描述来看,又不能保证它文章数据处理是否有错误啊!

我去该文献的数据集链接里面找到了它的表达量矩阵文件,很有意思的是需要去了解一下BD单细胞转录组技术的表达量矩阵情况:17M Apr 20 2022 GSM6050537_Combined_B1_RSEC_MolsPerCell.csv.gz 5.5M Apr 20 2022 GSM6050538_Combined_B2_RSEC_MolsPerCell.csv.gz 17M Apr 20 2022 GSM6050539_Combined_B3_RSEC_MolsPerCell.csv.gz 1.3M Apr 20 2022 GSM6050540_Combined_B4_RSEC_MolsPerCell.csv.gz 2.6M Apr 20 2022 GSM6050541_Combined_B5_RSEC_MolsPerCell.csv.gz 15M Apr 20 2022 GSM6050542_Combined_B6_RSEC_MolsPerCell.csv.gz 40M Apr 20 2022 GSM6050543_Combined_B7_RSEC_MolsPerCell.csv.gz如果你读取任意一个文件,就可以看到里面首先是有a pool of 40 oligo-attached antibody for surface markers (Ab-Seq).的表达量矩阵:
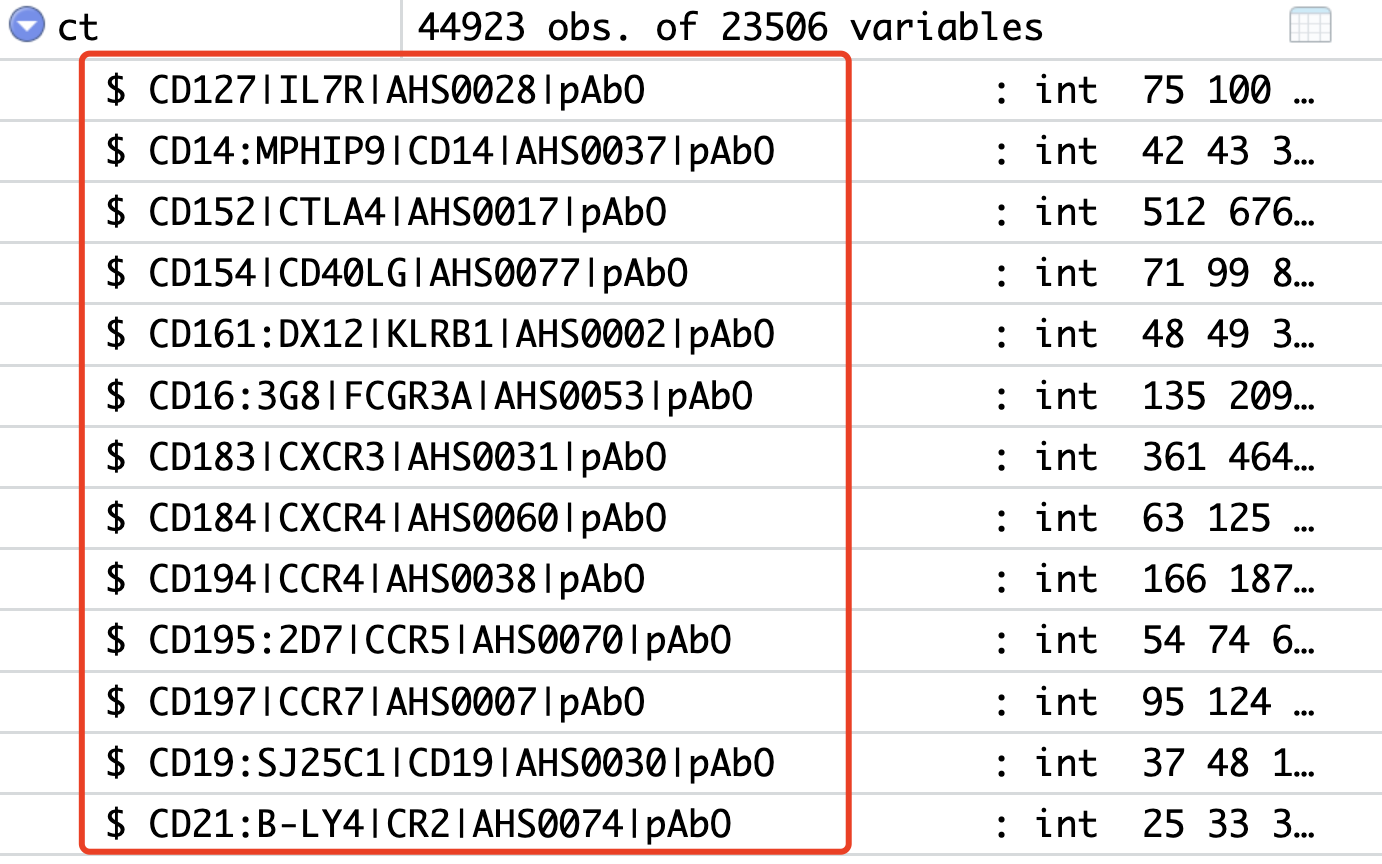
然后还有两万多个基因的表达量矩阵,理论上这两个矩阵应该是独立各自的下游降维聚类分群哈。学徒作业
上面的BD单细胞转录组应该是首先要区分Ab-Seq和WTA两个矩阵,各种独立降维聚类分群分析,大家试试看!
Smart-seq2和10x这两个单细胞技术是现在初学者进入单细胞领域最需要掌握的,它们代表着单细胞的两个全然不同的发展策略。绝大部分的技术原理介绍会从 单细胞悬浮液制备到测序细节面面俱到,其实并不那么的初学者友好。这里给推荐一个高度精炼的综述,这个综述于2020年9月发表在 《Experimental & Molecular Medicine》杂志,标题是:《Single-cell sequencing techniques from individual to multiomics analyses》,链接是:https://www.nature.com/articles/s12276-020-00499-2 - smart-seq2技术依赖于C1这个仪器,每次都是96个细胞一起测序,每个细胞的测序量这个综述可能是写错了,应该是1M-10M为佳,不太可能是100-1000个M,最重要的是它是整个RNA分子的全长测序,每个细胞都是独立的测序。
- 但是10X呢,每次可以测好几千的细胞,每个细胞只需要5-10K的reads,而且仅仅是测RNA分子的一段即可,全部的细胞都混合在一起,虽然说有barcode可以区分。