最近交流群有小伙伴提问《单细胞转录组》数据分析,我给了他我录制好了3个系列视频,和十套完整代码。但是对方说根本就没有用,我就纳闷了, 我的资料教会了那么多人单细胞数据分析,为什么就渡不了他呢?
就问了他数据集,结果是来源于一个2021发表的最新文献,广西大学的,标题是:《Single-Cell RNA-Seq Revealed the Gene Expression Pattern during the In Vitro Maturation of Donkey Oocytes》,我直接进入文章正文搜索其公布的单细胞数据情况,很容易可以看到:https://www.ncbi.nlm.nih.gov/sra?linkname=bioproject_sra_all&from_uid=763991
全部的六个样品如下所示:
ILLUMINA (Illumina NovaSeq 6000) run: 23.1M spots, 6.9G bases, 2Gb downloads
Accession: SRX12217372
ILLUMINA (Illumina NovaSeq 6000) run: 20.1M spots, 6G bases, 1.8Gb downloads
Accession: SRX12217371
ILLUMINA (Illumina NovaSeq 6000) run: 21.8M spots, 6.5G bases, 1.9Gb downloads
Accession: SRX12217370
ILLUMINA (Illumina NovaSeq 6000) run: 23.2M spots, 6.9G bases, 2.1Gb downloads
Accession: SRX12217369
ILLUMINA (Illumina NovaSeq 6000) run: 24M spots, 7.1G bases, 2.2Gb downloads
Accession: SRX12217368
ILLUMINA (Illumina NovaSeq 6000) run: 19.7M spots, 5.8G bases, 1.9Gb downloads
Accession: SRX12217367
也就是说,它并不是我们常规描述的单细胞转录组数据,其实本质上仍然是一个普普通通的转录组数据,分成了2个组,每个组里面是3个样品而已!
既然是常规的转录组实验设计,所以基本上按照我们转录组数据分析思路来即可!
首先是质量控制
质量控制最重要的就是3张图了啊,如下所示:
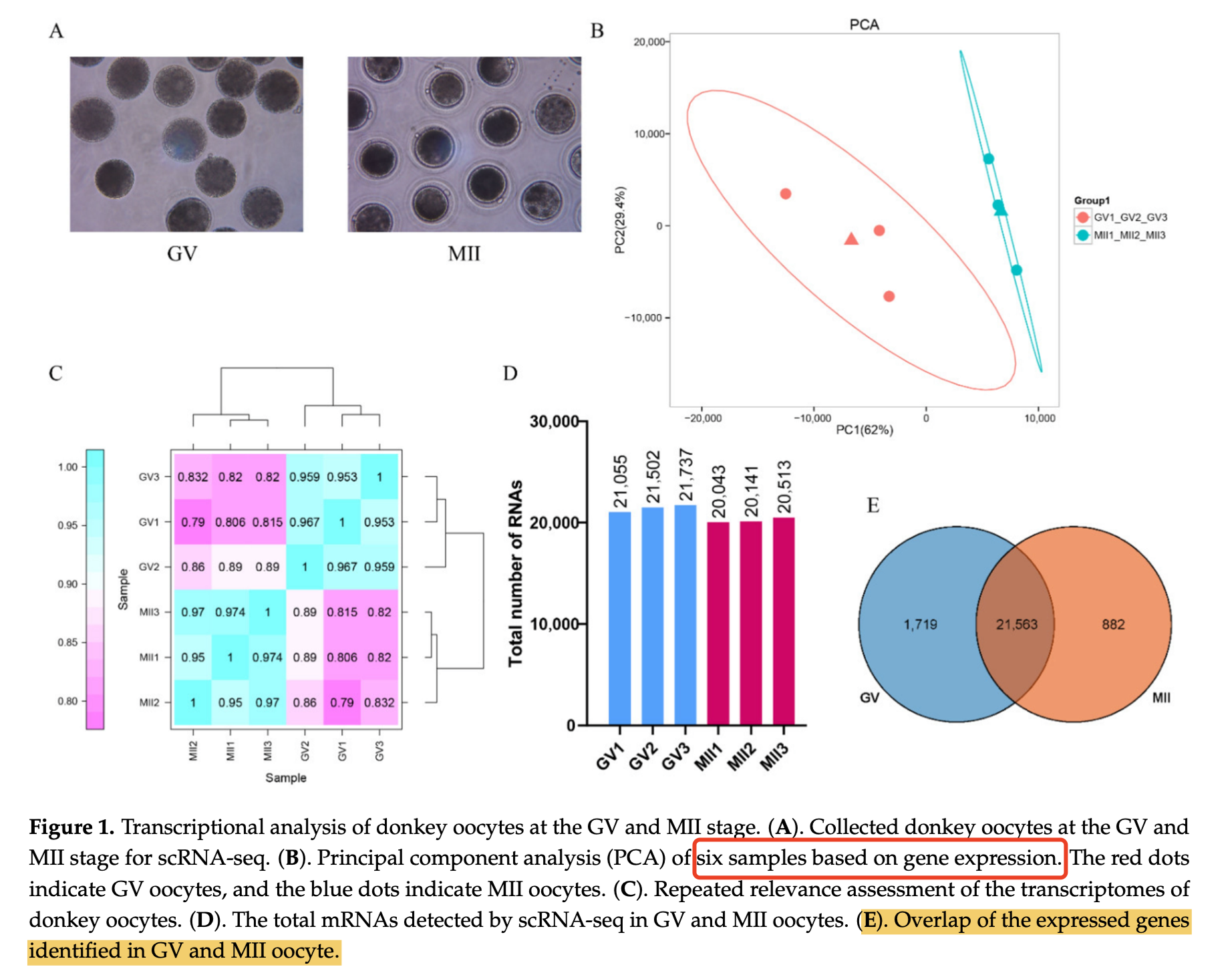
我在生信技能树的教程:《你确定你的差异基因找对了吗?》提到过,必须要对你的转录水平的全局表达矩阵做好质量控制,最好是看到标准3张图:主成分图和样品相关性热图,都是为了说明我们的分组的差异是大于组内样品的差异的。
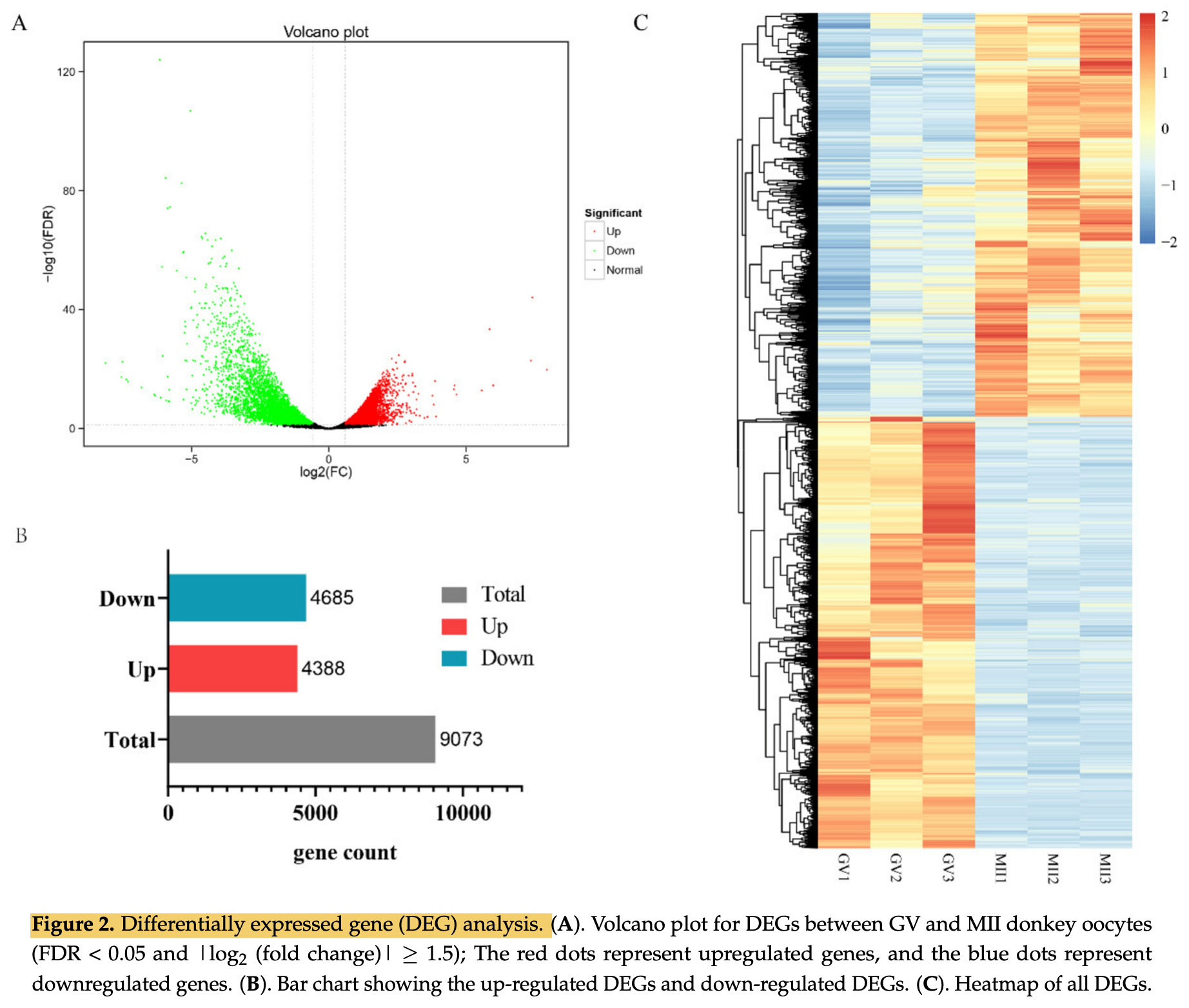
然后是差异分析
既然说明了们的分组的差异是大于组内样品的差异的,接下来就可以很简单的对两个分组进行普普通通的差异分析啦!
差异分析的图表也是固定的,火山图和热图!这个基本上 公众号推文即可,在:
- 解读GEO数据存放规律及下载,一文就够
- 解读SRA数据库规律一文就够
- 从GEO数据库下载得到表达矩阵 一文就够
- GSEA分析一文就够(单机版+R语言版)
- 根据分组信息做差异分析- 这个一文不够的
- 差异分析得到的结果注释一文就够
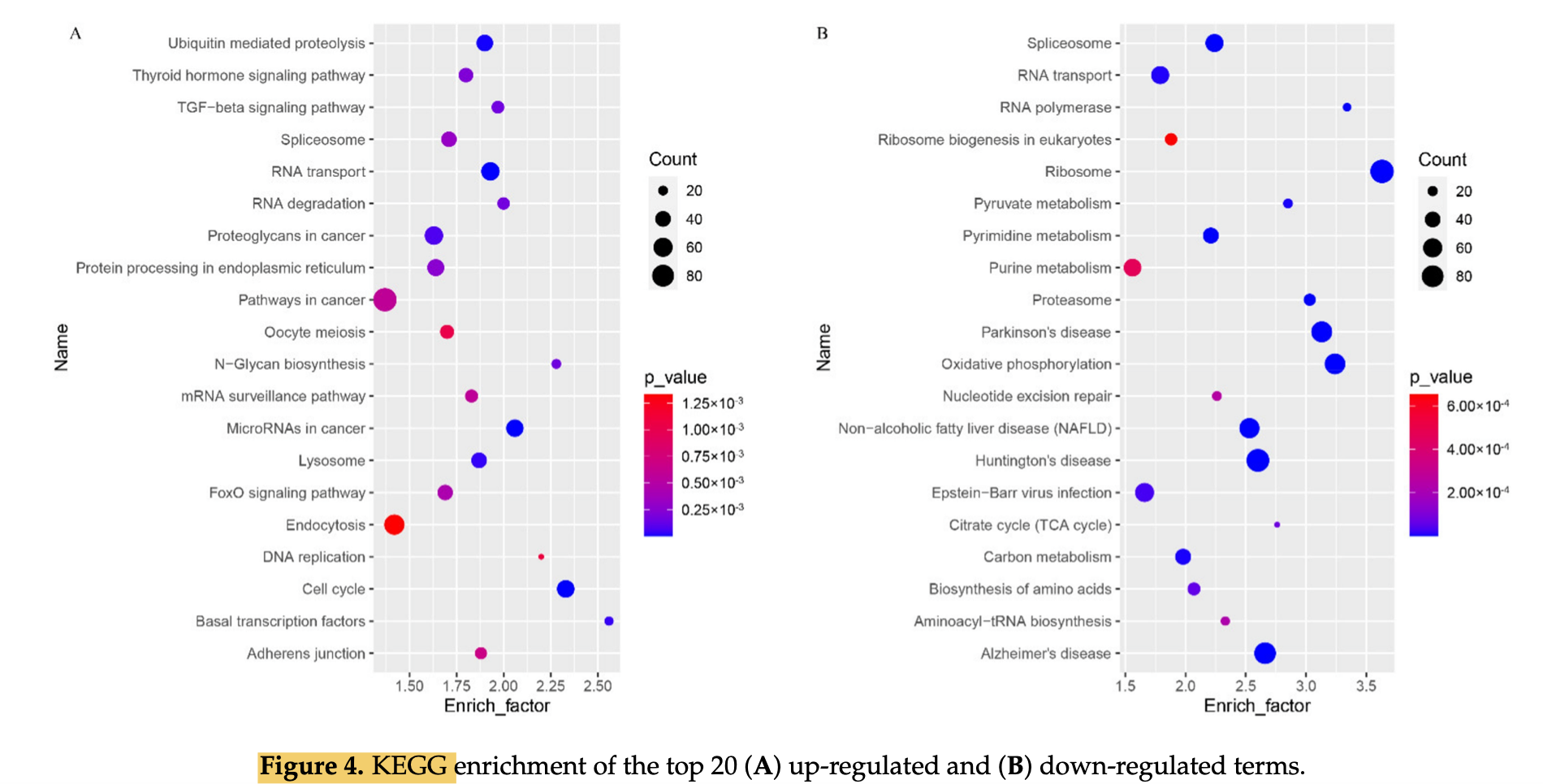
最后是上下调基因的go和kegg数据库注释
有了上下调基因列表,就可以进行标准的生物学功能数据库注释了,其实MSigDB(Molecular Signatures Database)数据库中定义了已知的基因集合:http://software.broadinstitute.org/gsea/msigdb 包括H和C1-C7八个系列(Collection),每个系列分别是:
- H: hallmark gene sets (癌症)特征基因集合,共50组,最常用;
- C1: positional gene sets 位置基因集合,根据染色体位置,共326个,用的很少;
- C2: curated gene sets:(专家)校验基因集合,基于通路、文献等:
- C3: motif gene sets:模式基因集合,主要包括microRNA和转录因子靶基因两部分
- C4: computational gene sets:计算基因集合,通过挖掘癌症相关芯片数据定义的基因集合;
- C5: GO gene sets:Gene Ontology 基因本体论,包括BP(生物学过程biological process,细胞原件cellular component和分子功能molecular function三部分)
- C6: oncogenic signatures:癌症特征基因集合,大部分来源于NCBI GEO 发表芯片数据
- C7: immunologic signatures: 免疫相关基因集合。
不过,通常情况下,大家并不需要对MSigDB数据库的全部类别的全部基因集进行注释,看看go和kegg数据库注释即可,如下所示:
全文升华需要一个故事落脚点
作者选择了 glycosylation genes. 主要是 N-Glycan biosynthesis 和 mucin-type O-Glycan biosynthesis 这两个 通路进行热图可视化。
而且,按照惯例,大家会实验验证部分差异基因,因为历史遗留原因,大家对ngs的高通量找差异的结果持怀疑态度。一般来说,就是 qPCR Validation 啦!