前面我们通过RcisTarget包的 cisTarget()函数,一句代码就完成了我们的hypoxiaGeneSet.txt文本文件的171个基因的转录因子注释。见:基因集的转录因子富集分析
通过学习,我们知道这个RcisTarget包内置的motifAnnotations_hgnc是16万行,可以看到每个基因有多个motif。而且下载好的 hg19-tss-centered-10kb-7species.mc9nr.feather 文件,也是 24453个motifs的基因排序信息。但是我们留下来了一个悬念,如何从几万个注释结果里面挑选到最后100个富集成功的motif呢?
首先批量计算AUC值
如果是单细胞转录组数据里面,每个单细胞都是有一个geneLists,那么就是成千上万个这样的calcAUC分析,非常耗费计算资源和时间,就需要考虑并行处理,我们这里暂时不需要,所以直接 nCores=1 即可。
其中geneLists和motifRankings来自于前面的教程,见:基因集的转录因子富集分析
motifs_AUC <- calcAUC(geneLists, motifRankings, nCores=1)
motifs_AUC
可以看到是 24453个motifs的AUC值都被计算了:
> motifs_AUC
AUC for 1 gene-sets and 24453 motifs.
AUC matrix preview:
jaspar__MA1023.1
geneListName 0.03819963
taipale_cyt_meth__IRX3_NACGYRNNNNNNYGCGTN_eDBD_meth
geneListName 0.05625049
taipale__DBP_DBD_NRTTACGTAAYN
geneListName 0.0640565
cisbp__M4240
geneListName 0.02816458
scertf__macisaac.ACE2
geneListName 0.03124153
>
挑选统计学显著的motif
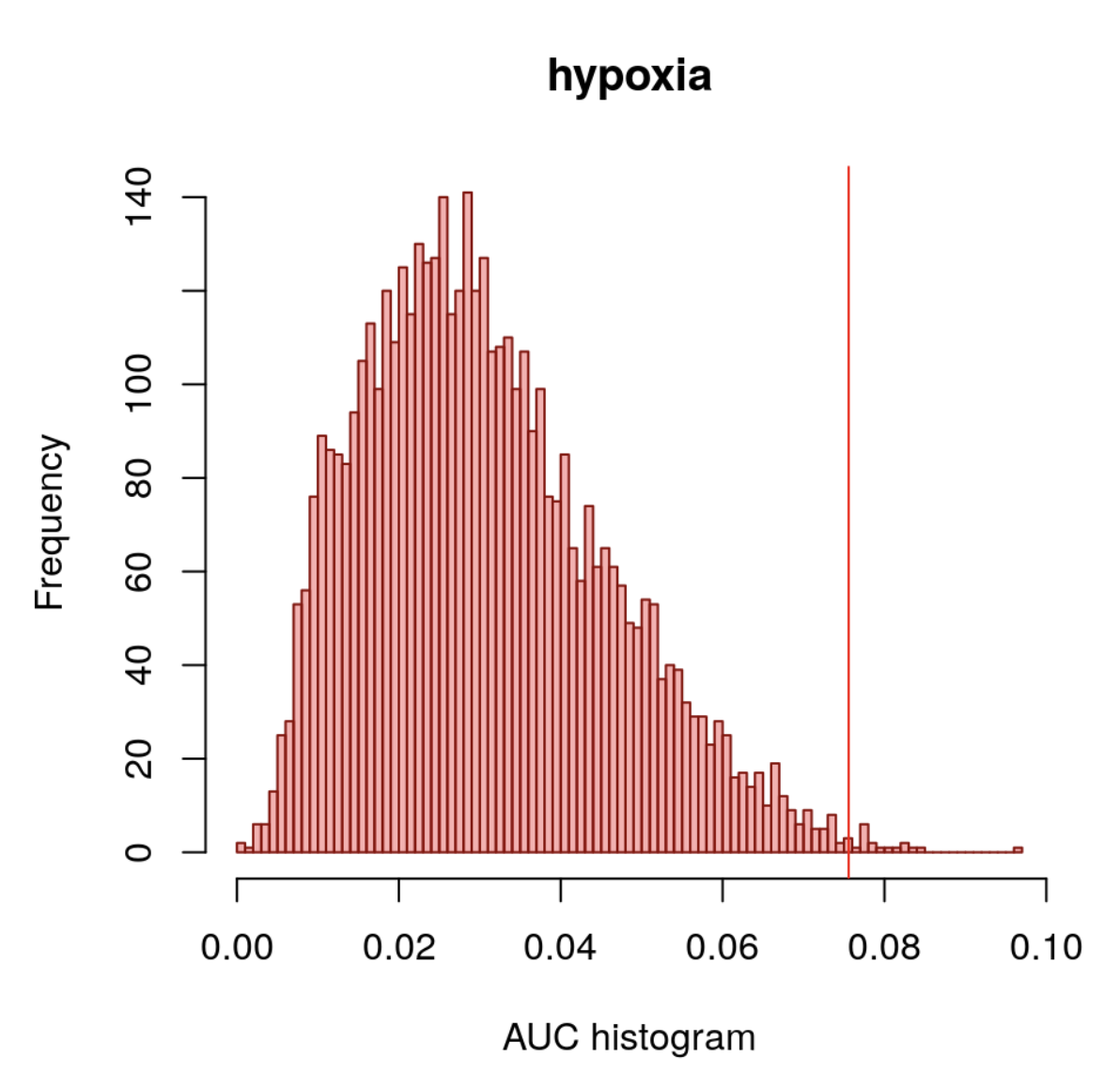
auc <- getAUC(motifs_AUC)[1,]
hist(auc, main="hypoxia", xlab="AUC histogram",
breaks=100, col="#ff000050", border="darkred")
nes3 <- (3*sd(auc)) + mean(auc)
abline(v=nes3, col="red")
可以看到 24453个motifs的AUC值看起来满足正态分布,一般来说,对正态分布,我们会挑选 mean+2sd范围外的认为是统计学显著,但是作者卡的比较严格,是 mean+3sd ,示意图如下:
看看Area Under the Curve (AUC)如何计算
这个时候就需要一个取舍了,我们是否需要知道每个细节,比如GSEA分析,我也多次讲解:
但实际上,绝大部分读者并没有去细看这个统计学原理,也不需要知道gsea分析的nes值如何计算,或者说这个Area Under the Curve (AUC)如何计算。
我这里也不想耗费时间去深究,去讲解了。不理解原理并不影响大家使用,知道这个概念,知道如何根据AUC值去判断结果就好。其实这个包的核心在于motifRankings变量,数据库文件来自于前面的教程,见:基因集的转录因子富集分析,也是很容易制作的,选取人类的不到2000个TF的全部chip-seq数据的peaks文件的bed,把人类的2万个基因的启动子区域的该TF的信号强度排序即可。
然后看看motif的详情
这个RcisTarget包内置的motifAnnotations_hgnc是16万行,可以看到每个基因有多个motif,我们挑选出来了105个moif,去这个表格里面筛选一下,就只剩下82个了。
data(motifAnnotations_hgnc)
motifAnnotations_hgnc
cg=auc[auc>nes3]
names(cg)
cgmotif=motifAnnotations_hgnc[match(names(cg),motifAnnotations_hgnc$motif),]
cgmotif=na.omit(cgmotif)
高级分析之可视化motif
前面的教程,一句代码就完成了motif的富集 ,见:基因集的转录因子富集分析
这个时候,我们可以根据 addLogo 函数,对我们富集好的转录因子的motif加上一些可视化图表,代码如下:
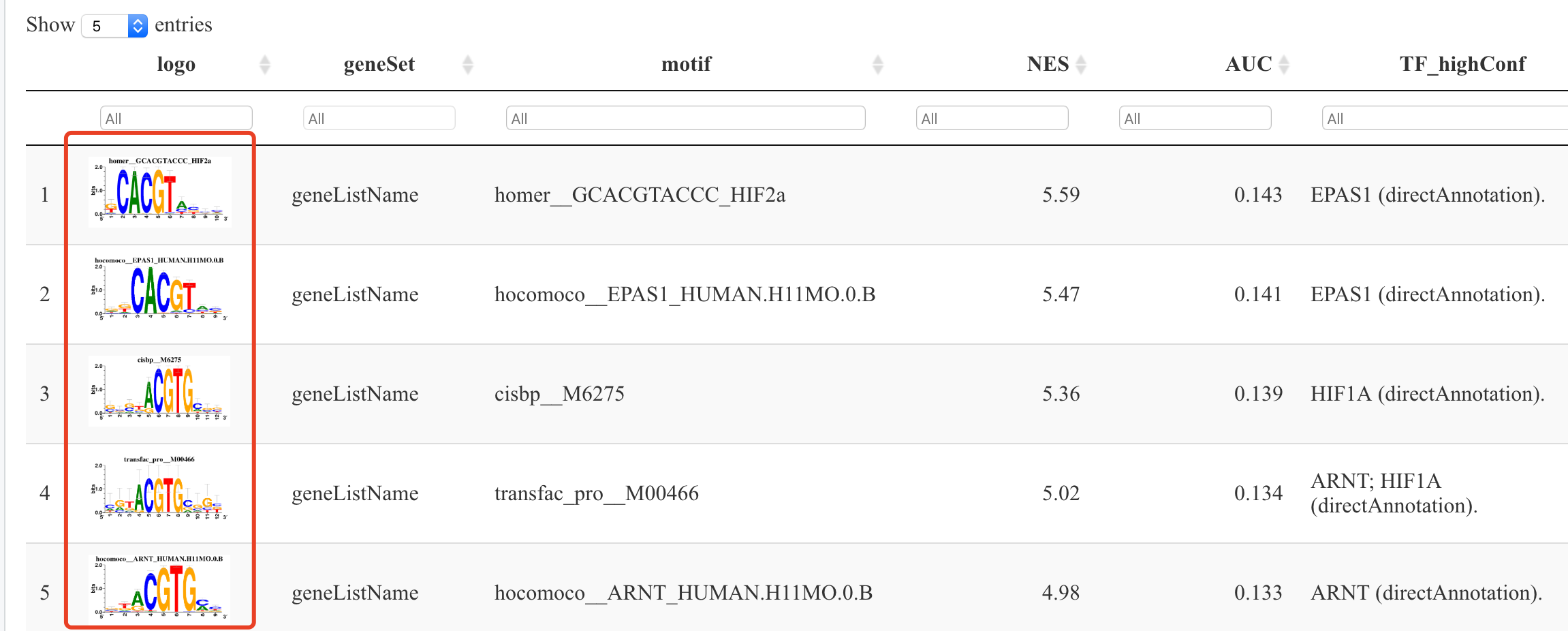
motifEnrichmentTable_wGenes
motifEnrichmentTable_wGenes_wLogo <- addLogo(motifEnrichmentTable_wGenes)
library(DT)
datatable(motifEnrichmentTable_wGenes_wLogo[,-c("enrichedGenes", "TF_lowConf"), with=FALSE],
escape = FALSE, # To show the logo
filter="top", options=list(pageLength=5))
这些motif都是数据库已知的,其可视化如下:
高级分析之网络图
这里面的R代码技巧还是蛮值得细细品读的:
anotatedTfs <- lapply(split(motifEnrichmentTable_wGenes$TF_highConf,
motifEnrichmentTable$geneSet),
function(x) {
genes <- gsub(" \\(.*\\). ", "; ", x, fixed=FALSE)
genesSplit <- unique(unlist(strsplit(genes, "; ")))
return(genesSplit)
})
anotatedTfs$hypoxia
signifMotifNames <- motifEnrichmentTable$motif[1:3]
incidenceMatrix <- getSignificantGenes(geneLists$hypoxia,
motifRankings,
signifRankingNames=signifMotifNames,
plotCurve=TRUE, maxRank=5000,
genesFormat="incidMatrix",
method="aprox")$incidMatrix
library(reshape2)
edges <- melt(incidenceMatrix)
edges <- edges[which(edges[,3]==1),1:2]
colnames(edges) <- c("from","to")
library(visNetwork)
motifs <- unique(as.character(edges[,1]))
genes <- unique(as.character(edges[,2]))
nodes <- data.frame(id=c(motifs, genes),
label=c(motifs, genes),
title=c(motifs, genes), # tooltip
shape=c(rep("diamond", length(motifs)), rep("elypse", length(genes))),
color=c(rep("purple", length(motifs)), rep("skyblue", length(genes))))
visNetwork(nodes, edges) %>% visOptions(highlightNearest = TRUE,
nodesIdSelection = TRUE)
一个简陋的网络图就出来了:
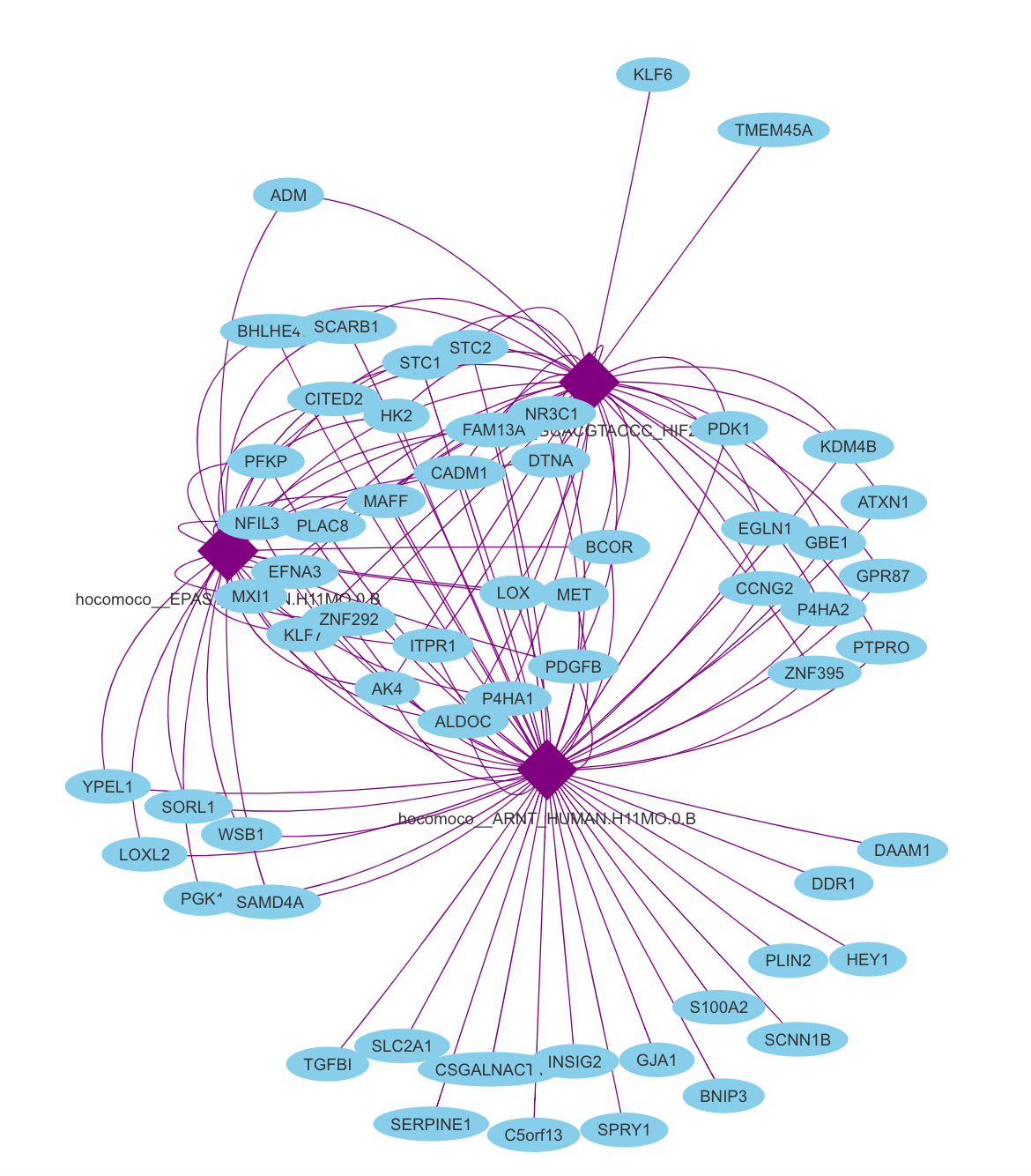
PPI调控网络图确实有点老套了
我有预感,这个转录因子调控网络图应该是在未来5年内会逐步替代PPI调控网络图,直到转录因子调控网络图也变得俗气为止。