总有一些难关,需要帮助才能跨过去,一起来看看学员的真实反馈吧!
下面是第五期生信入门学员的分享
介绍一下自己,一枚生信小白,研一在读,之前基本没有生信基础。
19年开学的时候是打算自学,偶然间发现生信技能树,然后在b站上看了生信技能树的视频,基础不够,看了一部分R语言的相关视频就没有继续看下去了。我在天津上学,一开始还想等生信技能树来天津然后报线下课,由于这次疫情的我,有机会上了线上班。我是第五期学员,现在已经是上完课的状态,虽然自己上完课了依旧很菜,但是至少让我有勇气,有底气觉得自己有一点点入门的希望,有可以让自己继续学下去的勇气。也把如此好的课程推荐给大家,生信技能树官方举办的学习班:
- 数据挖掘学习班第5期(线上直播3周,马拉松式陪伴,带你入门),原价4800的数据挖掘全套课程, 疫情期间半价即可抢购。
- 生信爆款入门-第7期(线上直播4周,马拉松式陪伴,带你入门),原价9600的生信入门全套课程,疫情期间3.3折即可抢购。
在六月初开始上课,当时一度怀疑自己跟不下来,现在想想真的是没有什么干不成的事儿。哈哈哈,我竟然这么飘。小洁老师的耐心,一直在说新手犯错没关系,让我一直有勇气学下去;郭老师的Linux,让我从之前听到Linux就有点害怕学习这个,到现在大概了解了这个系统,初入门的感觉真好;张老师带我们做的转录组测序,虽然老师上课的时候我在上第二天的课的时候就已经跟不上了,我都是上完课第二天去复习,在结课的最后一天也是晕晕乎乎的结课了。
我告诉自己一定要加油,因为钉钉群授课,我们的直播互动视频都保存下来了,所以我上周开始重新复习课程,印象最深的张老师讲的课开始的目录管理,非常非常非常重要!!!我现在就在想我一开始用windows系统的时候怎么没有人教我这个,所以在一开始用电脑现在想想真的是混乱。
我想分享一下转录组测序准备工作到数据下载我踩的大坑,每次登录服务器要先激活我的小环境(时刻提醒自己),目录管理要做好,软件,数据,项目要分开。
下面主要说说我的数据下载踩的坑,多亏了张老师的帮助让我从这两天的坑中跳了出来,我是用的aspera软件下载的。
在conda下安装aspera软件
conda install-y-chcc aspera-cli
which ascp
找到要下载的数据的BioProject;一般知道它的GEO accession和SRA number就可以从GEO和SRA网站上找到。通过下面这个网站进入https://www.ebi.ac.uk/ena/browser/home


show selected columns

下载它的tsv格式文件,用xftp上传到Linux自己操作的目录下面数据下载
单个文件下载 sra格式文件和gz格式文件,这个操作是简单的,完成的很好。
# sra格式 ascp -k 1 -QT -l 300m -P33001 -i ~/miniconda3/envs/rna/etc/asperaweb_id_dsa.openssh era-fasp@fasp.sra.ebi.ac.uk:/vol1/srr/SRR103/000/SRR1039510 ~/project/Human-16-Asthma-Trans/data/rawdata/sra # gz格式 ascp -k 1 -QT -l 300m -P33001 -i ~/miniconda3/envs/rna/etc/asperaweb_id_dsa.openssh era-fasp@fasp.sra.ebi.ac.uk:/vol1/fastq/SRR103/000/SRR1039510/SRR1039510_1.fastq.gz ~/project/Human-16-Asthma-Trans/data/rawdata/sra批量下载(对我来说很有问题)
得到sra.url文件,如果行尾存在特殊字符,运行
sed -i "s/\s*$//g" sra.url去掉行尾特殊字符
cat filereport_read_run_PRJNA229998_tsv.txt |awk'NR>1{print $NF}'>sra.url
这里我踩了个大坑。下载下来数据在windows下面用Excel打开了一下再上传的,由于点了每行行尾,然后在上传上去之后生成的sra.url文件每行行尾多了特殊字符,对数据下载流程即代码都不熟悉的我,开启了为时两天的踩坑。
在这里我是在后面生成sra.download.sh的时候才发现的,vim sra.download.sh,然后出现了下面这个图,我一直没有想明白怎么回事,后来在张老师的指点下,了解到时我上面写的那个问题,由于自己在windows下打开了文件并操作了一下再上传的。

去掉了这个特殊字符以后满怀信心的本以为我可以一路畅通的做下去。
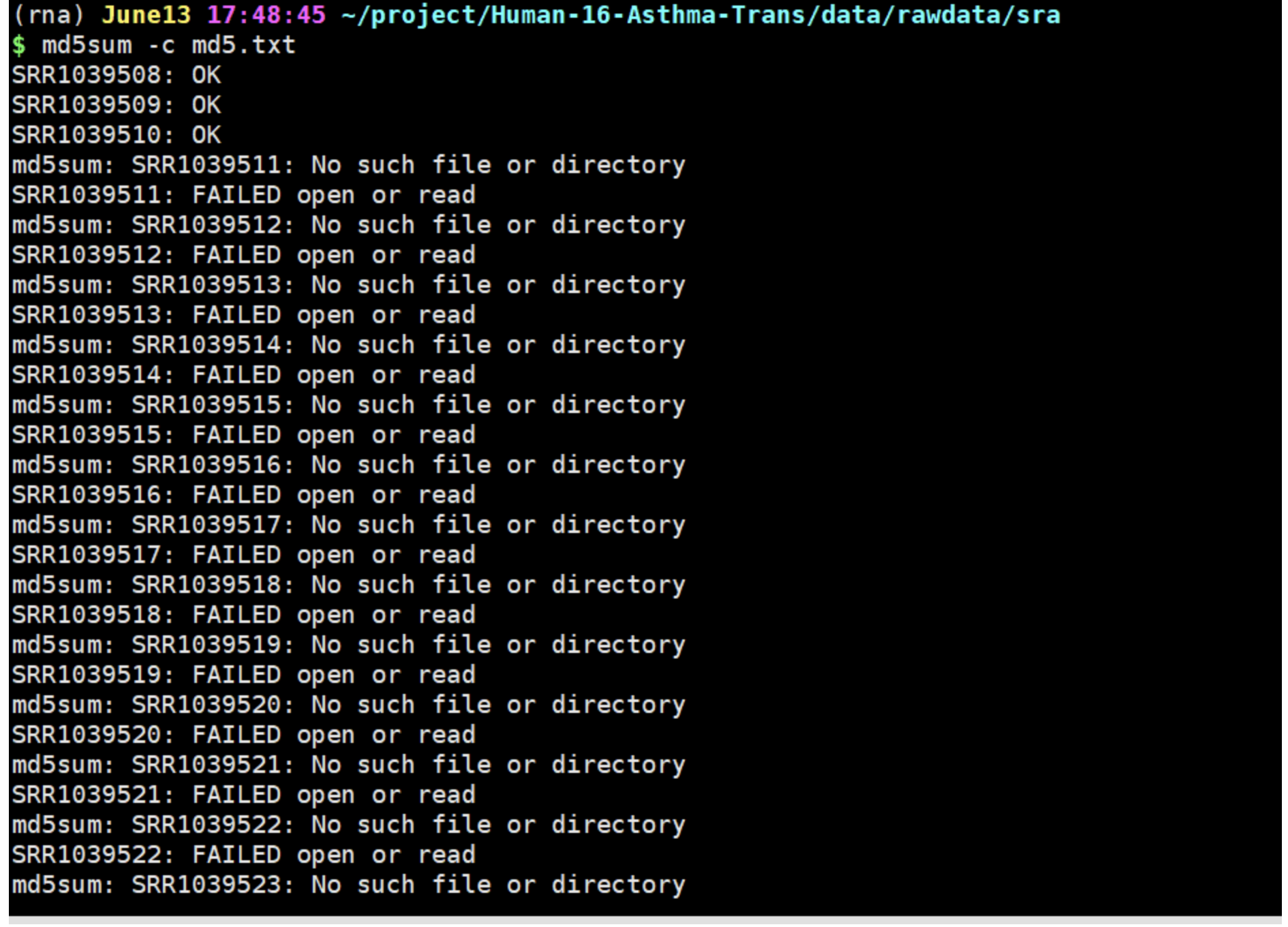
接着继续按照张老师上课的代码依据自己的目录修改了一下,去做了下面的命令最后显示的还是报错,在我挽救了一天的情况下,还是求助了张老师,最后发现outputdir=/project/Human-16-Asthma-Trans/data/rawdata/sra这句命令错了,错误命令(outputdir=/project/Human-16-Asthma-Trans/data/rawdata/sra)没有加~ 。
由于我错误的理解了绝对路径,在前几周上郭老师的课的时候Linux掌握的不好,所以在经过这次报错之后一定要好好的把郭老师的课反复听几遍并掌握。批量下载的命令
outputdir=~/project/Human-16-Asthma-Trans/data/rawdata/sra cat sra.url |while read id do echo"ascp -k 1 -QT -l 300m -P33001 -i ~/miniconda3/envs/rna/etc/asperaweb_id_dsa.openssh era-fasp@${id} ${outputdir}" done>sra.download.sh就成功了。
提交后台
这里需要使用nohup这个技巧,:
nohup bash sra.download.sh >sra.download.log &数据完整性检验(非常重要!!!)
得到md5值
awk 'NR>1{print $11"\t"$4}' filereport_read_run_PRJNA229998_tsv.txt >md5.txtmd5值检验
md5sum -c md5.txt
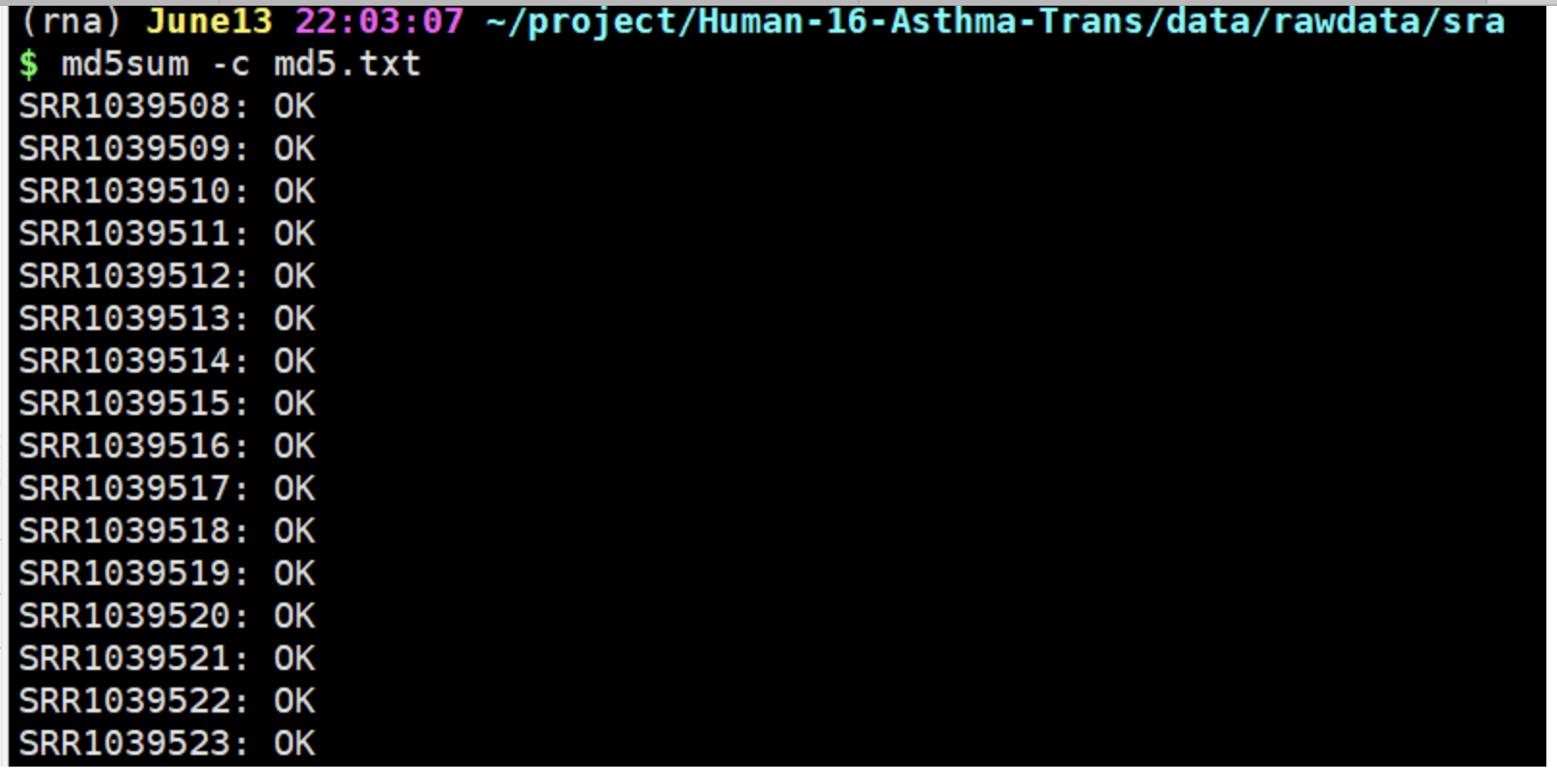
由于上面的命令错误,导致了md5值检验的错误,在整体改正之后出现了下面第二个图的结果。md5值检验 OK
希望自己以后多多踩坑,多多解决问题,在生信的道路上越走越顺利,哈哈哈。诚挚地感谢曾老师一直的鼓励,也谢谢生信技能树第五期课程上课的几位老师。