普通的爬虫,其实什么编程语言都差不多,因为都是网页的html源代码字符串的解析而已,但是很多网页是具有防止爬虫的功能,就是无法直接获取html源代码字符串,需要通过JavaScript来互动。比如:
- https://shuju.wdzj.com/
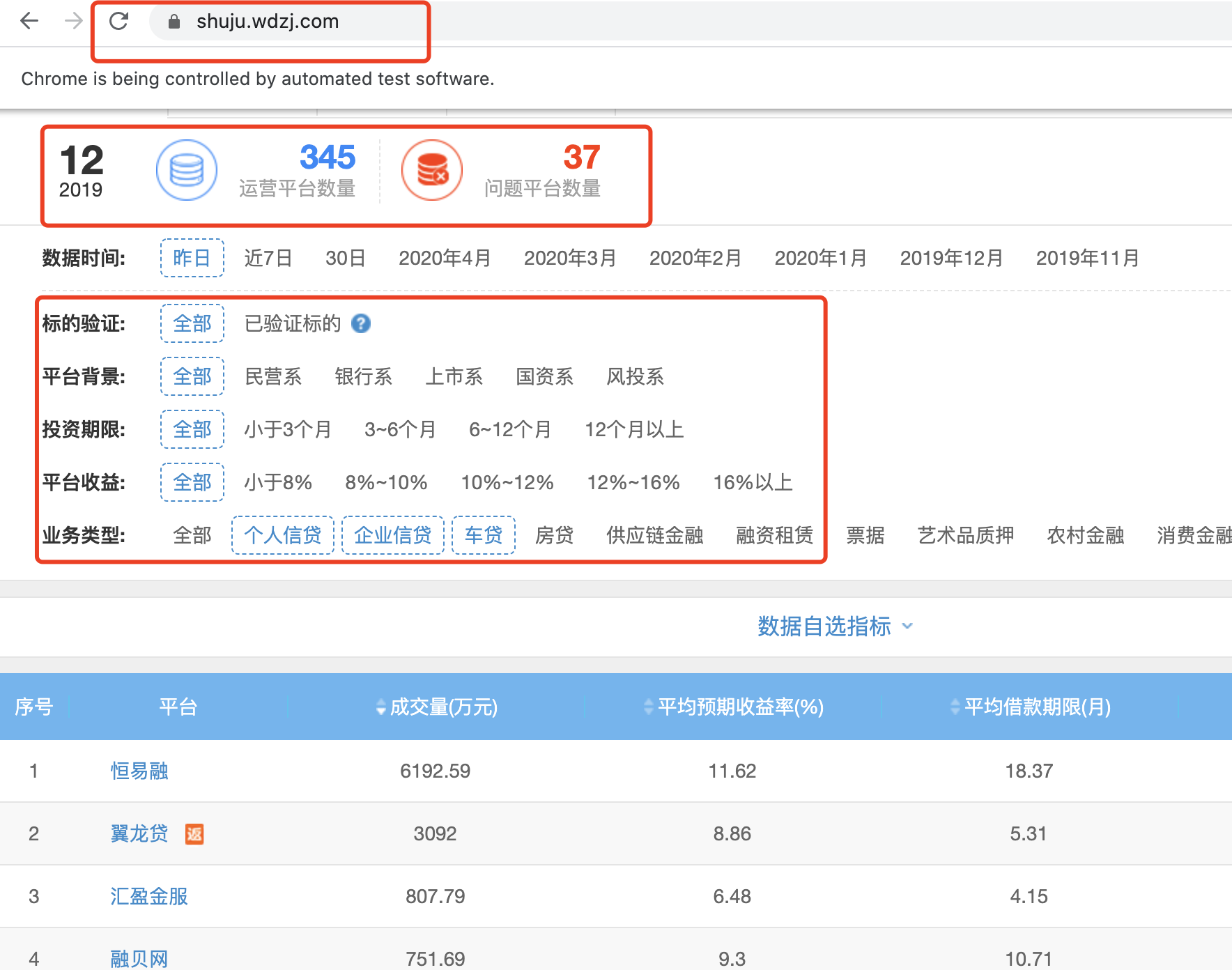
无论用户点击网页的什么内容,该网页的url都不变化,全部的内容都是数据库实时更新出来。所以我们的代码也需要跟这个网页进行交互,模拟JavaScript进程。
老实说,python写爬虫,真的是很爽,太多系统性的工具了: - re库(正则提取)
- requests库(网页数据抓取)
- 谷歌浏览器(对网页进行分析)
- BeautifulSoup库(网页标签和内容提取)
- selenium库+PhantomJS(获得渲染后的页面)
但是,我没有时间去系统性学习python了,而且python爬虫本来就是另外一个大的学习方向。不过我注意到,selenium库可能是有R的对应版本。首先下载Selenium Server (Grid)
Selenium是一个用于测试网页应用的开源软件。(通过代码操作浏览器,模拟人类鼠标和键盘浏览器操作)
- 它提供了浏览器中的点击,滚动,滑动,及文字输入等驱动程序。这样,利用Selenium即可以通过脚本程序来替代人工进行测试一个开发软件的各种功能。在处理爬虫任务中,经常遇到需要输入文字,进行下拉菜单选择,以及鼠标点击等情景。
- Selenium Server允许你在不同的浏览器上打开网址,对网页进行操作,并爬取网页元素的独立JAVA程序。在处理爬虫任务中,经常遇到需要输入文字,进行下拉菜单选择,以及鼠标点击等情景。通过Selenium Server我们可以对网页进行操作,然后爬取操作后的数据,从而进行爬取动态页面。
官网:https://www.selenium.dev/downloads/
是一个java程序,最新版(2020-05-21 )下载链接如下: - https://selenium-release.storage.googleapis.com/3.141/selenium-server-standalone-3.141.59.jar
不管你的电脑是Windows还是macOS,理论上都是需要自己搞定java运行环境的哈。然后配置chrome + chromeDriver
谷歌浏览器下载安装很简单,不管你的电脑是Windows还是macOS都是正常的软件安装步骤而已。
打开谷歌浏览器,输入: chrome://version/ 就可以看到你的谷歌浏览器安装文件夹路径,然后下载chromeDriver文件拷贝到谷歌浏览器安装文件夹路径,如下:cd /Applications/Google\ Chrome.app/Contents/MacOS/ (base) jmzengdeMacBook-Pro:MacOS jmzeng$ ls -lh -rwxrwxr-x 1 jmzeng admin 207K May 2 06:39 Google Chrome -rwxr-xr-x@ 1 jmzeng admin 10M May 21 09:19 chromedriver这两个文件非常重要,如果是苹果电脑,有一个权限设置也很重要:
xattr -d com.apple.quarantine chromedriver就在chromeDriver文件所在目录运行哦!
chromeDriver文件的下载链接是: - https://chromedriver.storage.googleapis.com/index.html?path=2.29/
接着开启Selenium Server (Grid)
前面下载了 selenium-server-standalone-3.141.59.jar,是java文件,所以调用你电脑配置好的java环境即可使用它啦,下面的命令:
java -jar selenium-server-standalone-3.141.59.jar日志如下:
09:27:52.106 INFO [GridLauncherV3.parse] - Selenium server version: 3.141.59, revision: e82be7d358 09:27:52.174 INFO [GridLauncherV3.lambda$buildLaunchers$3] - Launching a standalone Selenium Server onport 4444 2020-05-21 09:27:52.205:INFO::main: Logging initialized @274ms to org.seleniumhq.jetty9.util.log.StdErrLog 09:27:52.350 INFO [WebDriverServlet.<init>] - Initialising WebDriverServlet 09:27:52.416 INFO [SeleniumServer.boot] - Selenium Server is up and running on port 4444最后写R爬虫
代码很简单,如下:
library(RSelenium) library(rvest) library(stringr) ################调用R包######################################### library(rvest) # 为了read_html函数 library(RSelenium) # 为了使用JavaScript进行网页抓取 ###############连接Server并打开浏览器############################ remDr <- remoteDriver(remoteServerAddr = "127.0.0.1" , port = 4444 , browserName = "chrome")#连接Server remDr$open() #打开浏览器 remDr$navigate("https://shuju.wdzj.com/") #打开网页当然了,RSelenium用法肯定不止一次啦。一大波学习链接:
- https://ropensci.org/tutorials/rselenium_tutorial/
- http://thatdatatho.com/2019/01/22/tutorial-web-scraping-rselenium/
需要区分静态网页和动态网页
静态网页:https://phantomjs.org/api/webpage/property/cookies.html
动态网页:https://shuju.wdzj.com/