前面我在生信菜鸟团的肿瘤外显子数据分析专辑提到了,很多研究者会嫌弃cosmic数据库的30个肿瘤突变signatures,他们觉得cosmic数据库30个signature的生物学意义并不好,自己会尝试分解出来自己的signature。比如:0元,10小时教学视频直播《跟着百度李彦宏学习肿瘤基因组测序数据分析》 这篇文献,研究者就是使用R包SomaticSignatures进行denovo的signature推断,拿到了11个自定义的signature。
首先阅读 SomaticSignatures 包的文档
library(SomaticSignatures)
library(SomaticCancerAlterations)
library(BSgenome.Hsapiens.1000genomes.hs37d5)
sca_metadata = scaMetadata()
sca_metadata
sca_data = unlist(scaLoadDatasets())
sca_data$study = factor(gsub("(.*)_(.*)", "\\1", toupper(names(sca_data))))
sca_data = unname(subset(sca_data, Variant_Type %in% "SNP"))
sca_data = keepSeqlevels(sca_data, hsAutosomes(), pruning.mode = "coarse")
sca_vr = VRanges(
seqnames = seqnames(sca_data),
ranges = ranges(sca_data),
ref = sca_data$Reference_Allele,
alt = sca_data$Tumor_Seq_Allele2,
sampleNames = sca_data$Patient_ID,
seqinfo = seqinfo(sca_data),
study = sca_data$study)
sca_vr
可以看到,这个包,需要的是sca_data这个变量里面各个列,用到了的就是 c( “Sample”,”chr”, “pos”,”ref”, “alt”) 这些列。所以我们自己的somatic突变信息,也需要制作成为这5列。
把508个ESCC的WGS数据的somatic突变制作成为 SomaticSignatures 包的输入数据
这个是大于500M的CSV文件,下载后修改名字,然后读入R,并且制作成为 SomaticSignatures 包的输入数据的代码如下:
library(data.table)
b=fread('../maf.csv',data.table = F)
b[1:4,1:3]
colnames(b)
mut=b
table(mut$Variant_Type)
mut=mut[mut$Variant_Type=='SNP',]
a=mut[,c(10,2,3,8,9)]
colnames(a)=c( "Sample","chr", "pos","ref", "alt")
alls=as.character(unique( a$Sample))
a$study=a$Sample
head(a)
虽然我们使用了 data.table 包的 fread函数,可以超级快的读入大于500M的CSV文件,但是也需要一点时间啦。
制作的a这个变量,如下:
> head(a)
Sample chr pos ref alt study
2 FP1705100059DN01 chr1 4870770 G T FP1705100059DN01
3 FP1705100059DN01 chr1 5111686 C T FP1705100059DN01
4 FP1705100059DN01 chr1 5116099 C T FP1705100059DN01
5 FP1705100059DN01 chr1 5151401 C T FP1705100059DN01
6 FP1705100059DN01 chr1 5151403 G C FP1705100059DN01
7 FP1705100059DN01 chr1 5217189 G A FP1705100059DN01
一个很普通的数据框而已,并不是SomaticSignatures 包的文档介绍sca_data这个变量的类型,但是该有的5列信息是有的。
sca_vr = VRanges(
seqnames = a$chr ,
ranges = IRanges(start = a$pos,end = a$pos+1),
ref = a$ref,
alt = a$alt,
sampleNames = as.character(a$Sample),
study=as.character(a$study))
sca_vr
提取突变上下文已经计算96突变形式的比例
在SomaticSignatures 包已经是封装好的函数,很容易就可以获取,而且速度超级快哦,代码如下:
# 突变位点坐标基于hg19,从基因组根据坐标获取碱基上下文
sca_motifs = mutationContext(sca_vr, BSgenome.Hsapiens.UCSC.hg19)
head(sca_motifs)
# 对每个样本,计算 96 突变可能性的 比例分布情况
escc_sca_mm = motifMatrix(sca_motifs, group = "study", normalize = TRUE)
dim( escc_sca_mm )
table(colSums(escc_sca_mm))
head(escc_sca_mm[,1:4])
使用NMF确定denovo的signature数量
我们都知道,sanger研究所科学家【1】提出来了肿瘤somatic突变的signature概念 ,把96突变频谱的非负矩阵分解后的30个特征,在cosmic数据库可以学习它。不同的特征有不同的生物学含义【2】,比如文章【3】 就是使用了 这些signature区分生存!主要是R包deconstructSigs可以把自己的96突变频谱对应到cosmic数据库的30个突变特征。
- 【1】https://software.broadinstitute.org/cancer/cga/msp
- 【2】https://en.wikipedia.org/wiki/Mutational_signatures
- 【3】https://www.nature.com/articles/s41586-019-1056-z
但是我们现在要自己推断denovo的signature,所以使用SomaticSignatures 包的identifySignatures函数哦,代码如下:
# 预先设定待探索的 signature 数量范围,文章最后选定11个
if(F){
n_sigs = 5:15
gof_nmf = assessNumberSignatures(escc_sca_mm , n_sigs, nReplicates = 5)
save(gof_nmf,file = 'gof_nmf.Rdata')
}
load(file = 'gof_nmf.Rdata')
# 这个 assessNumberSignatures 步骤耗时很严重。
plotNumberSignatures(gof_nmf)
# 根据这个图表,选择11个 signature
sigs_nmf = identifySignatures(escc_sca_mm ,
11, nmfDecomposition)
save(escc_sca_mm,sigs_nmf,file = 'escc_denovo_results.Rata')
绘制自己NMF确定denovo的11个signatures的96突变频谱
代码如下:
load(file = 'escc_denovo_results.Rata')
str(sigs_nmf)
library(ggplot2)
plotSignatureMap(sigs_nmf) + ggtitle("Somatic Signatures: NMF - Heatmap")
plotSignatures(sigs_nmf, normalize =T) +
ggtitle("Somatic Signatures: NMF - Barchart") +
facet_grid(signature ~ alteration,scales = "free_y")
出图如下:
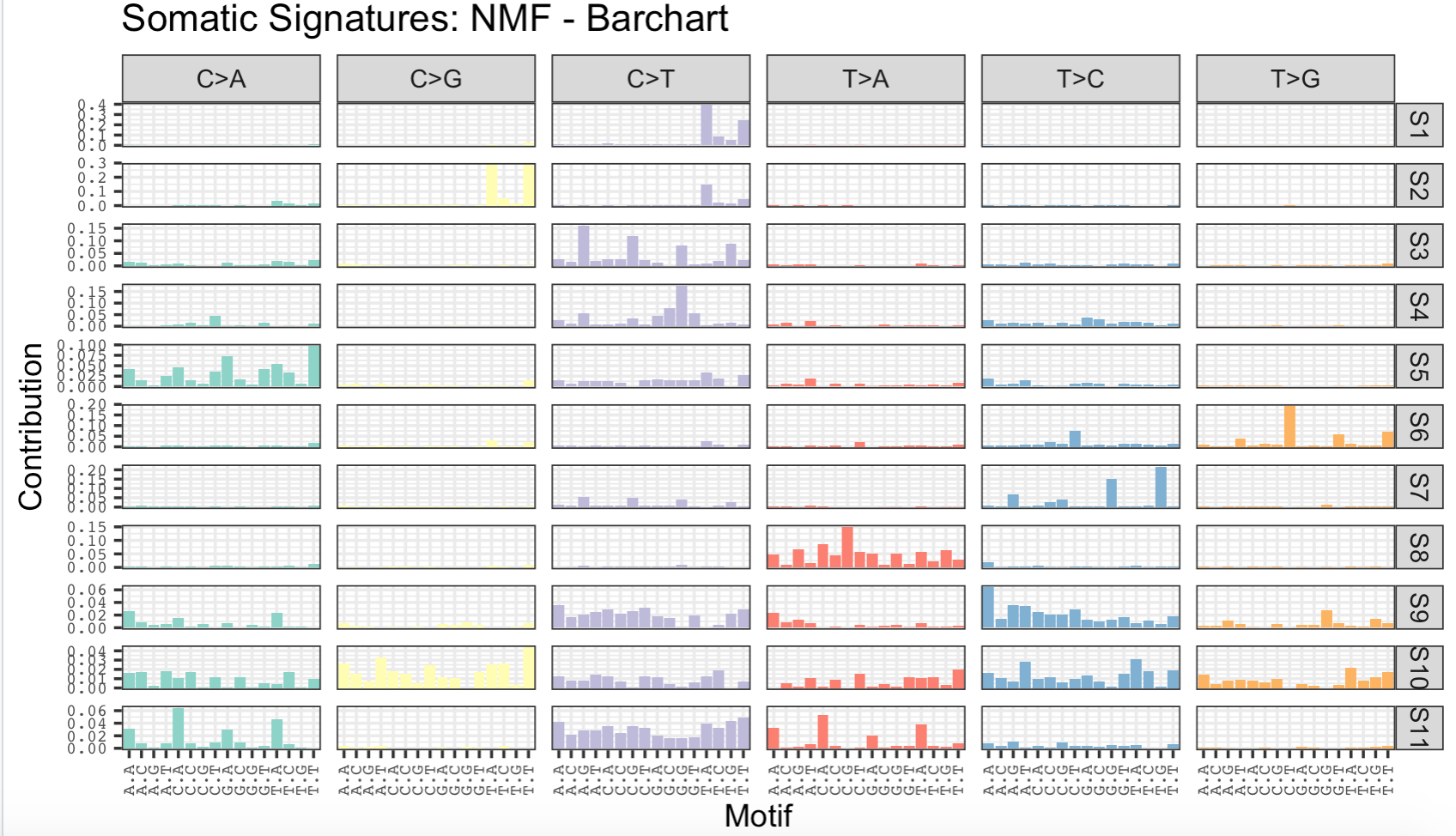
你可以去跟Whole-genome sequencing of 508 patients identifies key molecular features associated with poor prognosis in esophageal squamous cell carcinoma文章对比一下,几乎是一模一样。
当然,拿到了自己NMF确定denovo的11个signatures,还仅仅是这篇文章的开始而已,后续分析更精彩哈, 欢迎继续follow我们的0元,10小时教学视频直播《跟着百度李彦宏学习肿瘤基因组测序数据分析》 。