我在生信技能树分享了一个教程:不要怀疑,你的基因就是没办法富集到统计学显著的通路,然后在生信菜鸟团给了一个解决方案:差异基因没办法富集到通路你就放弃了吗,但是他们都是基于转录组表达量来的,这并不意味着GO/KEGG这样的生物学功能数据库的注释仅仅是只能针对转录表达的数据。
实际上,GO/KEGG数据库针对的是基因,不需要是表达量上下调的基因,也可以是突变与否的基因。比如下面的表格:
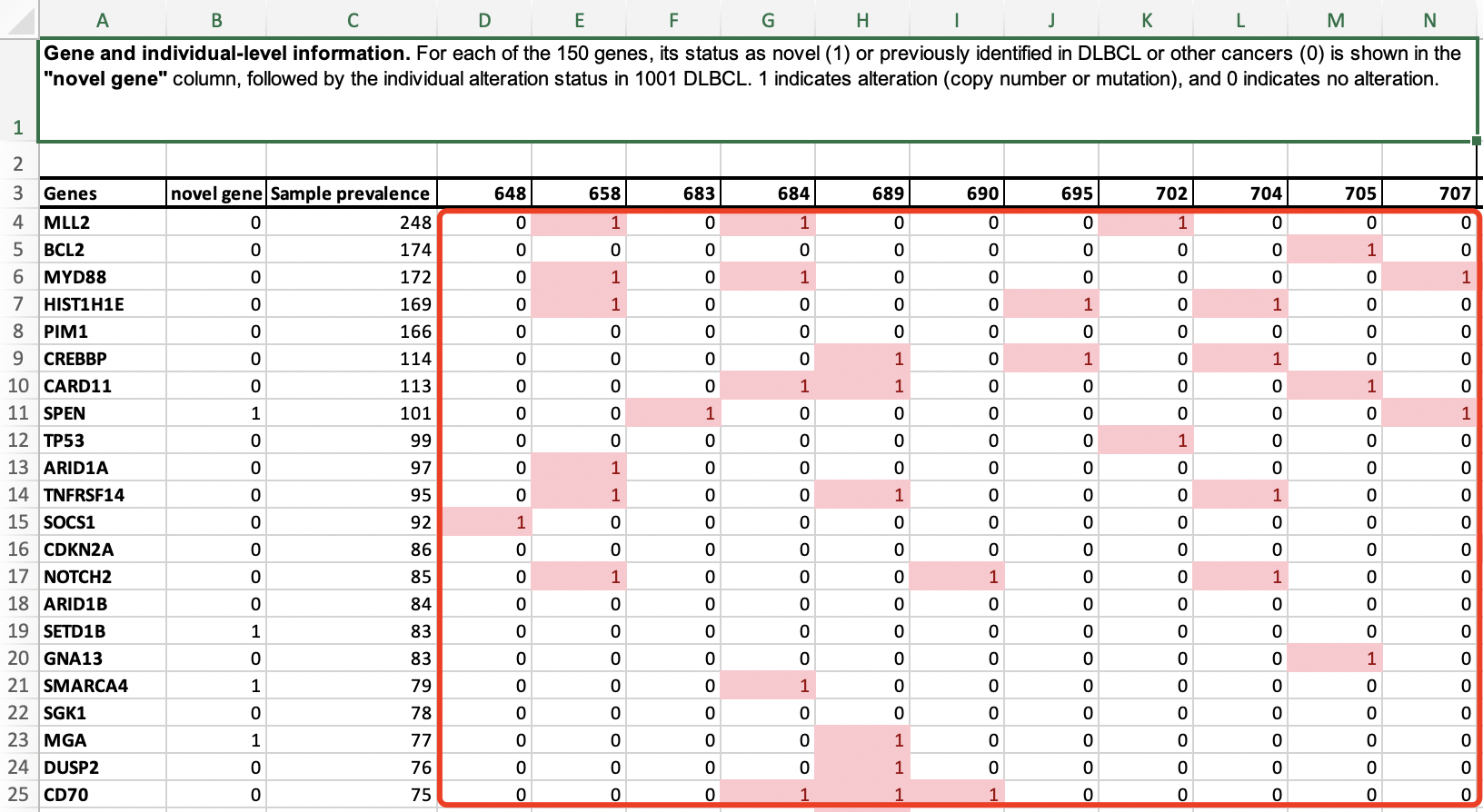
这是一个突变与否的二值矩阵,每一个病人的每一个基因,是否有突变,都列出来了。那么这个时候有一个分析就顺理成章了,就是我们通常想关心具体的某些通路是否突变,而不是某一个基因,因为目前的药物领域还有很多是靶向通路的。上面的样本-基因突变与否二值矩阵,就需要进行GO/KEGG数据库注释,作为样本-通路突变与否二值矩阵。
这个时候就完全没有超几何分布检验的事情了,因为哪怕一个通路里面仅仅是只有一个基因发生了突变,我们都会认为这个通路是突变的,无需要计算P值。因为这个时候每个病人突变的基因数量本来就很少,通常是10个左右,这个数量级是无需超几何分布检验的。但是我们仍然可以使用超几何分布检验,仅仅是需要把P值的阈值去掉即可:
genes=c("MLL2","BCL2","MYD88","HIST1H1E","PIM1",
"CREBBP","CARD11","SPEN","TP53","ARID1A",
"TNFRSF14","SOCS1","CDKN2A","NOTCH2","ARID1B",
"SETD1B","GNA13","SMARCA4","SGK1","MGA","DUSP2","CD70",
"ATM","BTG2","ZNF608","STAT6","KLHL6","MTOR","BIRC6","IRF8",
"IRF4","PIK3CD","SETD2","TET2","B2M","TNFAIP3","ARID5B","EZH2",
"ETS1","ZNF292","FAM5C","MCL1","EP300","MLL3","MEF2B","MYC","TBL1XR1",
"DCAF6","DDX10","PAX5","KLHL14","GNAS","RB1","INO80","CHD8","BTG1","CD79B",
"DNMT3A","FOXO1","PTPN6","BCL6","BCL7A","TMEM30A","ZEB2","JAK3","MECOM","EBF1",
"ANKRD17","ETV6","ZFAT","NCOR1","IKZF3","MSH2","ATR","CHD1","NFKBIE","PRDM1",
"CD83","STAT3","TAF1","ZBTB7A","CCND3","MAP4K4","NF1","UBE2A","DDX3X","IL16",
"SETD5","JUNB","JAK1","PTPRK","CHST2","GOLGA5","NFKBIA","RHOA","ACTB","CDC73",
"PIM2","BCL10","BTK","CD58","CBLB","MARK1","HNRNPU","SF3B1","UBR5","MYB",
"TIPARP","NFKB2","MET","RRAGC","IKBKB","TOX","FAS","DICER1","TMSB4X","GNAI2",
"MAGT1","PHF6","POU2F2","XPO1","WAC","YY1","CD22","HRAS","BRAF","FOXP1",
"HIST1H2BC","RARA","S1PR2","FUBP1","STAT5B","KRAS","RUNX1","TCL1A","CXCR4",
"PTEN","FBXW7","MAP2K1","ZFX","BTBD3","CIITA",
"HNRNPD","LIN54","MSH6","PIK3R1","KCMF1","SYK","TGFBR2","CASP8")
patient=sample(genes,10)
library(clusterProfiler)
library(org.Hs.eg.db)
gene.df<-bitr(patient,fromType="SYMBOL",
toType=c("ENSEMBL","ENTREZID"),
OrgDb=org.Hs.eg.db)
head(gene.df)
genelist=gene.df$ENTREZID
kegg <- enrichKEGG(genelist, organism = 'hsa',
pvalueCutoff = 1,
qvalueCutoff =1)
kegg=setReadable(kegg,org.Hs.eg.db,keyType = 'ENTREZID')
head(kegg)
dt=kegg@result
dotplot(kegg,showCategory=30)
可以看到,随便去10个基因,都是可以在kegg里面找到113条通路的,虽然是大量的通路仅仅是被“富集”到一个基因,如果从统计学角度来看,当然是没有“富集”的统计学意义啦。
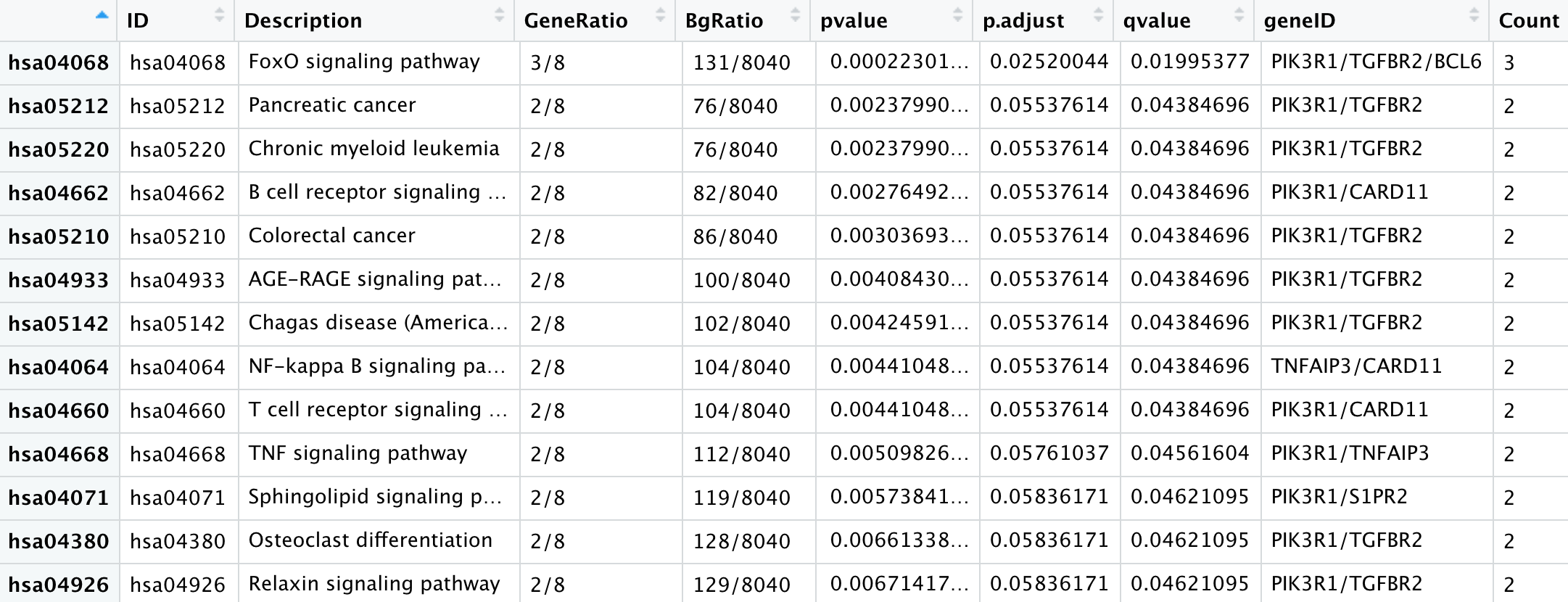
但是在这113个通路里面,是有我们感兴趣的肿瘤免疫相关的,就可以制作样本-通路突变与否的二值矩阵啦。
步骤如下:
- 对每个病人的突变基因,都走上面的流程拿到全部的kegg通路
- 然后把全部的病人的kegg通路结果数据塑性,长变宽
- 如果要求更多的通路,就试试看msigdb啦
这个时候的超几何分布检验对我们来说,仅仅是起通路注释的作用,所以P值显著与否没有关系!