静态网站内容爬取rvest、RCurl、XML这几个包都可以实现这个功能。比如下面的网页:
- http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/xsjj/index.phtml?num=20&p=
很明显看到,页面有一个表格:
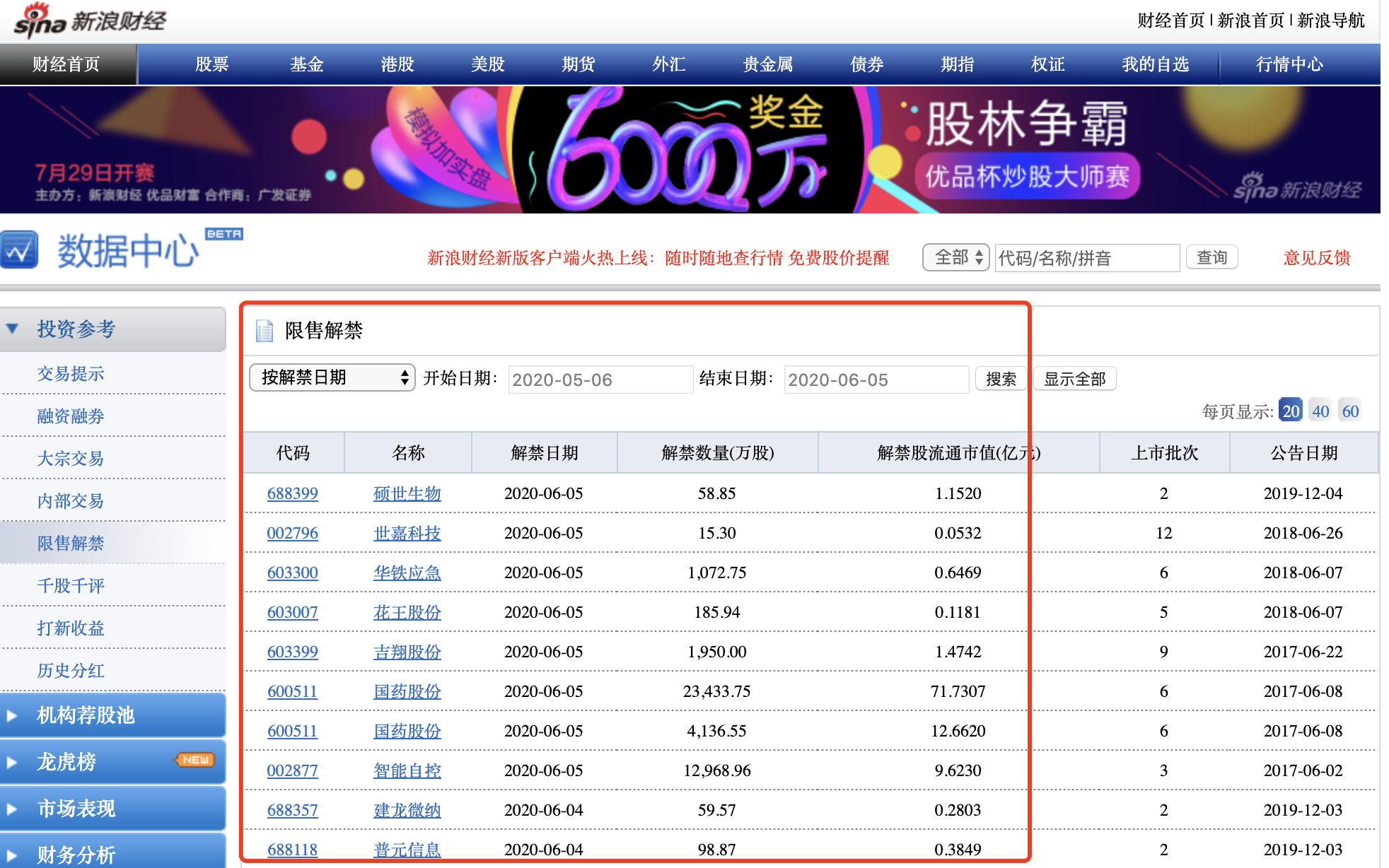
这些内容都是存放在该网页的html源代码里面,所以爬虫代码非常简单:rm(list = ls()) library(rvest) url <- paste0('http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/xsjj/index.phtml?num=20&p=', 1:6) trade <- lapply(url,function(x){ html_table(read_html(x), header =T)[[1]] }) trade1 <- do.call(rbind,trade)对全部的6个页面,循环走一下read_html函数即可,然后使用html_table提取里面的表格,然后综合起来。我以前介绍过的peerJ期刊的爬虫也是如此。
当然了,这个循环会以为某些url(如果你的url成百上千个)失效而断掉,所以你其实是需要加上一个判断机制,所以我修改后的代码是:library(rvest) url='http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/xsjj/index.phtml?p=' get_tables <- function(url){ fit<-try(web <- read_html(url),silent=TRUE) if('try-error' %in% class(fit)){ cat('HTTP error 404\n') }else{ return(html_table(web) [[1]]) } } trade=lapply(1:6, function(i){ get_tables(paste0(url,i)) }) trade1 <- do.call(rbind,trade)但并不是所有的网页内容都会显示在其对应的html源代码里面,比如局部动态刷新网站。
- http://www.brics.ac.cn/plasmid/template/plasmid/plasmid_list.html
可以看到,无论我们如何点击下一页,虽然网页的内容一直在修改,但是网页的url是不会变化的,而且使用rvest包根本就读不到真实的网页内容信息。

第一个想法是,使用rvest包模拟一个浏览器请求去访问这个网页,第二个想法是使用其它R包可以访问动态网页的,第三个想法是,使用JavaScript把网页交互后的源代码保存下来,然后去解析里面的信息。关于局部动态刷新网站
这样的网页爬虫的确很难搞,我看到了一个教程:
- https://blog.csdn.net/eastmount/article/details/80088948
但是它使用的是python爬虫的selenium模块,代码步骤如下:
1.定位驱动:driver = webdriver.Firefox()
2.访问网址:driver.get(url)
3.定位节点获取第一页内容并爬取:driver.find_elements_by_xpath()
4.获取“下一页”按钮,并调用click()函数点击跳转
5.爬取第2页的网站内容:driver.find_elements_by_xpath()
其核心步骤是获取“下一页”按钮,并调用Selenium自动点击按钮技术,从而实现跳转,之后再爬取第2页内容。
但是,我没有时间去学习python了,而且python爬虫本来就是另外一个大的学习方向。 本来准备是求助一个python大神,但是想了想开不了口,我好歹也是一方风云人物。
唉,只好硬着头皮继续上。接下来测试使用JavaScript把网页交互后的源代码保存下来,然后去解析里面的信息。 - https://zhuanlan.zhihu.com/p/24772389
关于phantomjs
学起来也是一个大工程:https://phantomjs.org/
- https://phantomjs.org/quick-start.html
- https://javascript.ruanyifeng.com/tool/phantomjs.html
- https://mp.weixin.qq.com/s/mGwm-rAdwyr63l8mv0l_DQ
需要了解的是webpage模块是PhantomJS的核心模块,用于网页操作。所以标准代码头部如下:var webPage = require('webpage'); var page = webPage.create();我略微思考,写出来了下面的代码,因为不会JavaScript,所以这个代码其实是有问题的。
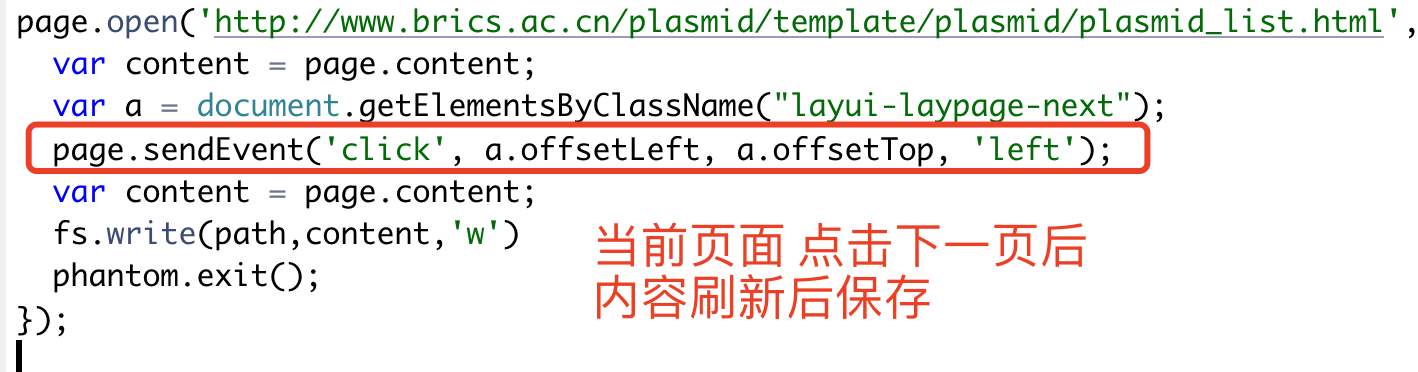
主要的原因其实是phantomjs打开的网页,仍然不是最终的HTML源代码,虽然是可以使用 page.content保存那个HTML源代码,但是并不能解析获取里面的“下一页”去点击它。
有意思的是我看到了PhantomJS从入门到放弃,https://www.jianshu.com/p/8210a17bcdb8最后本来是准备按照url规律都保存为html网页文件
看了看,总共是33951 个记录 plasmid,但是很明显ID过界了。不过这个并不是重点:
- http://www.brics.ac.cn/plasmid/template/plasmid/plasmid_detail.html?id=39983
- http://www.brics.ac.cn/plasmid/template/plasmid/plasmid_detail.html?id=39982
- http://www.brics.ac.cn/plasmid/template/plasmid/plasmid_detail.html?id=39979
关键是 phantomjs 仍然是拿不到里面的信息:var webPage = require('webpage'); var page = webPage.create(); var fs = require('fs'); var path = 'test.html' page.open('http://www.brics.ac.cn/plasmid/template/plasmid/plasmid_detail.html?id=39983', function (status) { var content = page.content; fs.write(path,content,'w') phantom.exit(); });即使我暴力循环10000到99999的全部ID,仍然是拿不到里面真正的HTML源代码里面的信息。
回到了selenium
我的想法是,既然python爬虫的selenium模块可以做到,R里面也应该是有selenium类似的,略微搜索,居然真的有!
我花半个小时学了一下selenium的R代码实现方式,就解决了这个问题。
明天分享这个解决过程,预计会出4个教程。