免疫组库测序(Immune Repertoire Sequencing,IR-Seq)是非常小众的产品,并不属于TCGA的7种数据(WGS,WES,RNA-seq,miRNA,450K等等),所以我并没有在B站录制公益教学视频。
有趣的是,最近突然接到了一些粉丝求助,关于免疫组库数据处理的。所以就系统性的整理一下相关知识点,并且带领大家实战演练一个完整的免疫组库测序数据项目分析流程哈。
关于IMGT数据库
在HGM(人类基因组图谱)的赞助下,IMGT(国际免疫遗传学数据库)于1989年6月在蒙彼利埃(蒙彼利埃大学和CNRS)成立。IMGT的诞生标志着免疫遗传学和生物信息学的交叉学科免疫信息学的诞生。
蒙彼利埃市(Montpellier)位于法国南部地中海畔,北距巴黎746公里。是法兰西共和国埃罗省省会,郎格多克地区经济、文化教育、中心。它也是法国的避寒圣地,被称为“阳光之城”。
国际免疫遗传学数据库(IMGT,http://www.imgt.org)用于分析抗原受体、免疫球蛋白(抗体)的基因(等位基因)以及T细胞受体,整理从鱼类到人类等颌骨脊椎动物的巨大且复杂的适应性免疫库!
在New Haven举行的第十届人类基因组图谱(HGM10)研讨会上,免疫球蛋白(IG)或抗体和T细胞受体(TR)的V、D、J和C基因与常规基因一样,被正式命名为“基因”!
参考: IMGT® and 30 Years of Immunoinformatics Insight in Antibody V and C Domain Structure and Function[J]. Antibodies 2019, 8, 29: doi:10.3390/antib8020029
关于免疫球蛋白(IG)或抗体和T细胞受体(TR)
关于 可变区(V区)和恒定区(C区)
IG和TR都是复合蛋白,由多个基因各自转录翻译后的蛋白加工组成。比如每一个BCR,包含两条重链和两条轻链。其中重链由一个可变区(V区)和三个恒定区(C区)组成,轻链则包含一个可变区与一个恒定区。
可变区(V区)
可变区(V区)则决定了它的特异性,即决定了它能和什么样的抗原结合。主要是V、D和J基因组成,如下:
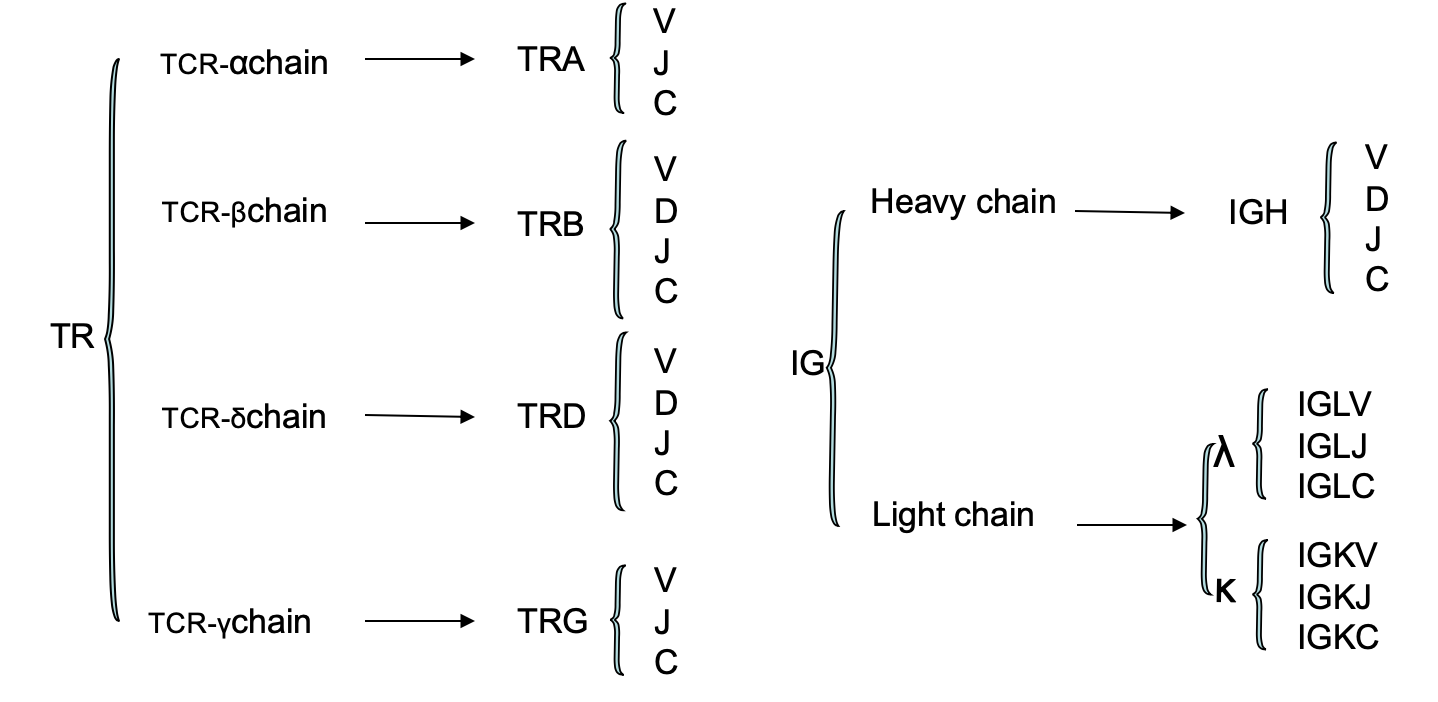
其中IG分成IGH,IGK,IGL这3类,而TR分成TRA,TRB,TRD,TRG这4类。
可以看到D基因并不是必需品哦!
恒定区(C区)
就是上图的C基因啦。
重链的恒定区,决定了BCR的免疫原性,即决定了它属于5类免疫球蛋白(IgA、IgG、IgM、IgD、IgE)中的哪一种。而轻链的恒定区,则决定了搭配的轻链种类(k或入型)。
在IMGT数据库的V,D,J和C基因记录情况
进入:http://www.imgt.org/IMGTrepertoire/LocusGenes/#F
可以看到,并不是所有的物种的免疫相关基因,都被IMGT数据库收录
首先看IG相关的V,D,J和C基因记录情况:

同理,可以看TR的V,D,J和C基因记录情况

如果大家要做免疫组库,最好是有IMGT提供你研究的物种的相关新,后续数据分析会简单很多。
查看相应V,D,J和C基因数量,比如人类的 :http://www.imgt.org/IMGTrepertoire/LocusGenes/genetable/human/geneNumber.html
The human genome comprises a total number of 608-665 IG and TR genes (371-422 IG and 237-243 TR), depending on the haplotypes, per haploid genome of which 531-588 genes are located in the 7 major loci (distributed in 369-418 V, 32 D, 105-109 J and 25-29 C genes).
其中V基因数量比较多,两百多个, 但是D和J都只有几十个,C也是很少。

There are also 77 orphons (68 IG and 9 TR) (including two processed IG genes which are IGHEP2 and IGLJ-C/OR18), outside the major loci.
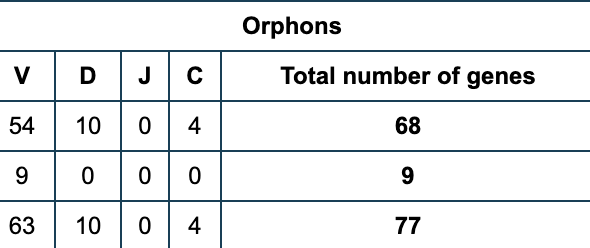
前面我们提到过IG分成IGH,IGK,IGL这3类,而TR分成TRA,TRB,TRD,TRG这4类。前面的IG的两百多个V基因分到3类,每个类别就100个左右的V基因啦。

而TR需要分配到TRA,TRB,TRD,TRG这4类,所以每个类别里面的V基因数量不到100,其它D,J,C基因更是少得可怜。
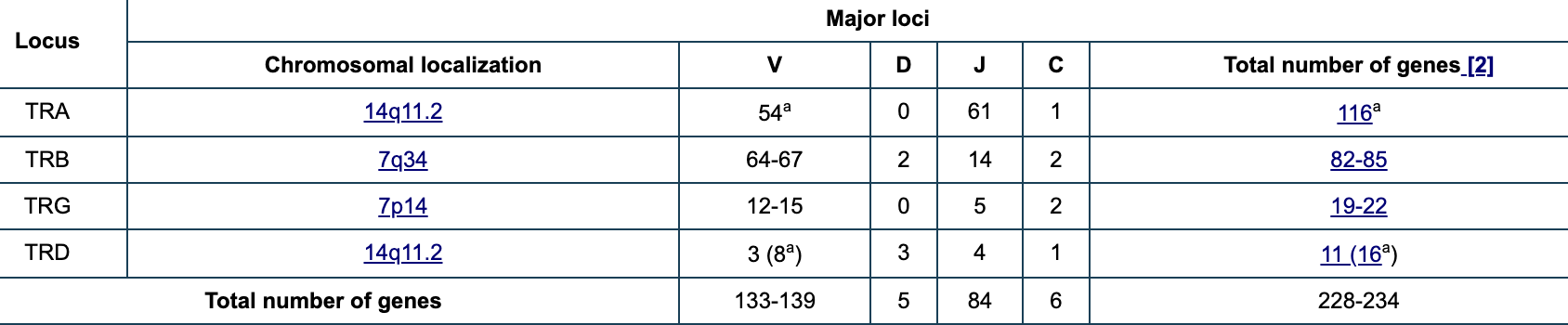
V,D,J基因的组成
前面的IG的两百多个V基因分到3类,每个类别就100个左右的V基因啦,比如我们具体看IGHV,就是123-129个基因,可以分成3大类和7小类:
- clan I: IGHV1, IGHV5 and IGHV7 subgroup genes
- clan II: IGHV2, IGHV4 and IGHV6 subgroup genes
- clan III: IGHV3 subgroup genes
这些基因都拥挤在狭小的染色体片段上面:
All the IGHV genes are in a fully sequenced contig which comprises the following accession numbers: - AB019437 (200000 bp): IGHV(III)-82 to IGHV(II)-60-1
- AB019438 (200000 bp): IGHV3-60 to IGHV4(II)-40-1
- AB019439 (200000 bp): IGHV7-40 to IGHV3-21
- AB019440 (200000 bp): IGHV(II)-20-1 to IGHV2-5
- AB019441 (157090 bp): IGHV4-4 to IGHV6-1
详细表格在 http://www.imgt.org/IMGTrepertoire/index.php?section=LocusGenes&repertoire=genetable&species=human&group=IGHV ,如下:
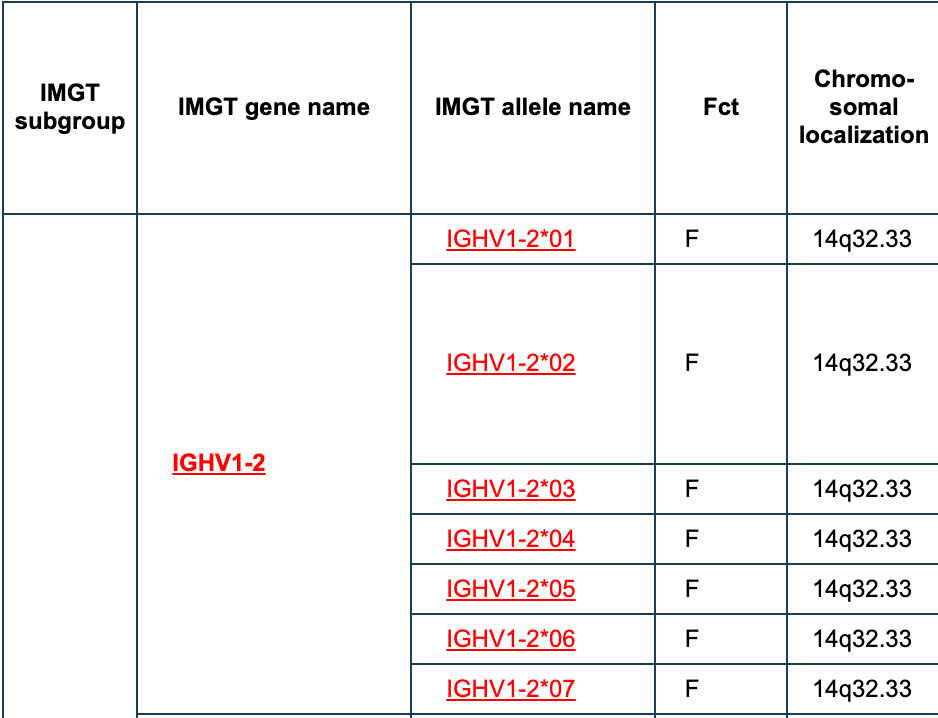
其它的IGH,IGK,IGL这3类,以及TRA,TRB,TRD,TRG上面的 V,D,J基因也是类似的查看即可。具体查看单个基因
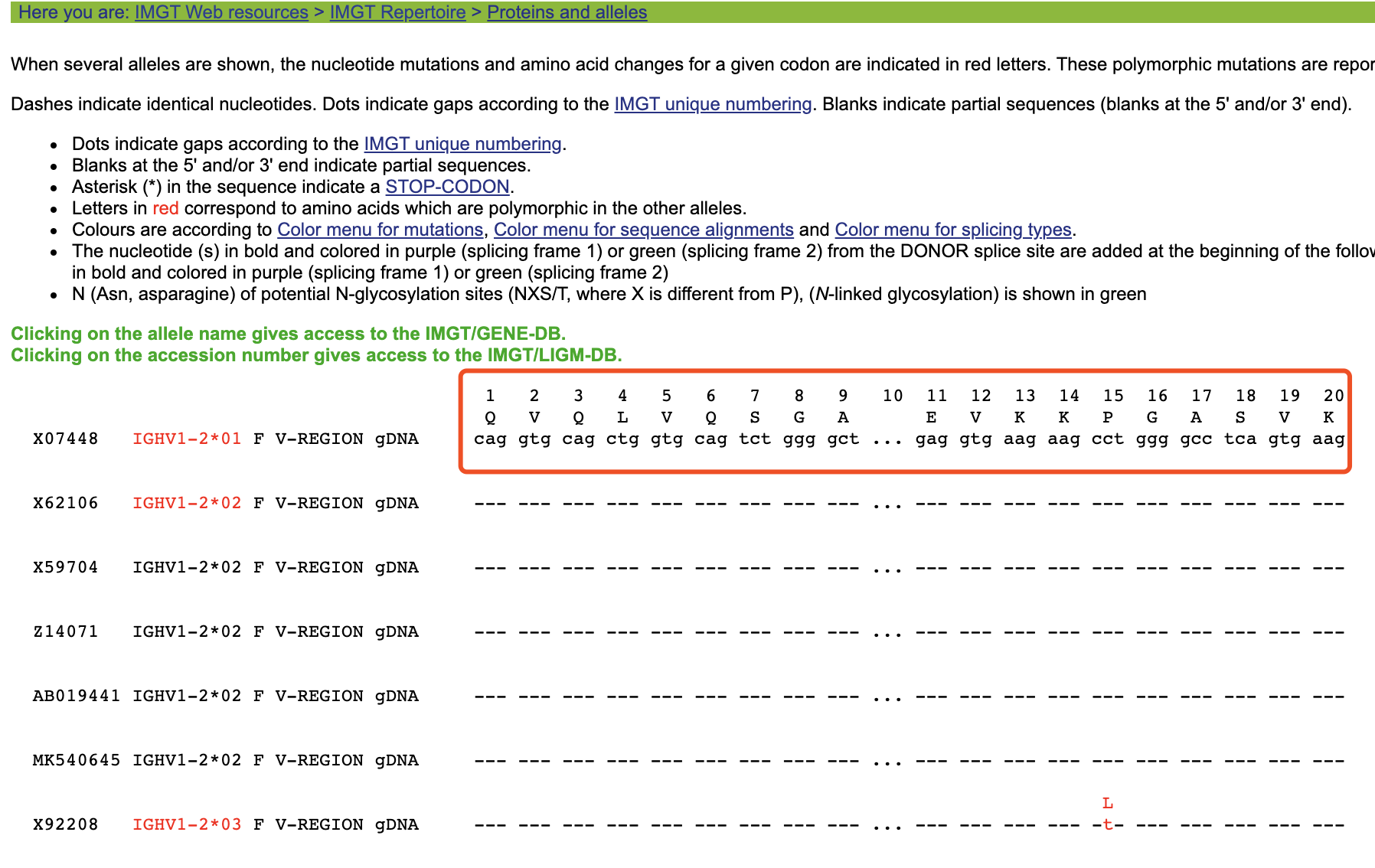
比如进入 http://www.imgt.org/IMGTrepertoire/Proteins/alleles/index.php?species=Homo%20sapiens&group=IGHV&gene=IGHV1-2
这个IGHV1-2属于IGHV的一百多个基因里面的一个而已,就有很多allele。
但是IGHV的一百多个基因它们的开头都是类似的, 所以设计有限的引物,就可以把全部的IGHV的一百多个基因都覆盖。如下所示,是一篇文章的BCR的引物列表:

直接下载全部IG或者TR的V,D,J,C基因序列
其中IGH,IGK,IGL这3类,以及TRA,TRB,TRD,TRG四类。V,D,J,C基因在人类的数量约 608-665 IG and TR genes 。
比如前面提到的,IG里面的IGH里面的V基因,就是IGHV,总共有123到129个基因 : - IGHV1-2
- IGHV1-3
- IGHV1-8
- IGHV1-18
- IGHV1-24
- ···中间省略100个基因···
- IGHV1-38-4
- IGHV1-45
- IGHV1-46
- IGHV1-58
- IGHV7-34-1
- IGHV7-81
- IGHV8-51-1
免疫组库测什么
有了上述背景知识,再讲解免疫组库就容易理解了。免疫组库测序(Immune Repertoire Sequencing,IR-Seq)是一种专用于研究淋巴细胞表面受体多样性的方法。而且淋巴细胞,通常是T淋巴细胞或B淋巴细胞,它们的表明就是TCR或BCR。
免疫组库其实是某种程度的捕获基因组测序,全基因组测序,全外显子测序大家都很熟悉了,基因panel也不陌生,其实免疫组库就是一种基因panel,关注的是 608-665 IG and TR genes 。区别在于,普通的基因panel需要在每个基因的每个外显子上面设计探针,保证全方位的覆盖,捕获效率很重要。
但是如果关注的是 608-665 IG and TR genes ,它们其实过于同源了。所以只需要设计有限引物,
免疫组库测序(Immune Repertoire Sequencing,IR-Seq)的生物信息学数据分析主要包括: - 测序数据评估与过滤;
- 不同种类V,D/J基因的数目、频率统计;
- 不同种类V-J组合(气泡图)和V-D-J组合(桑基图)的数目、频率统计;
- V基因、J基因、V-J组合、V-D-J组合的组间差异比较;(火山图)
- CDR3氨基酸克隆型的数目、频率、长度统计;
- 基于CDR3氨基酸克隆型频率的样本间相似性评估;
- CDR3氨基酸克隆型的多样性分析,包括Gini、Simpson、Shannon、d50;
- CDR3氨基酸克隆型差异表达分析;
- 样本间共有CDR3氨基酸克隆分析;
关键是,免疫组库的数据量都不大,因为类似于普通的基因panel,而且仅仅是需要看多样性
大家可以拿这个:https://www.ncbi.nlm.nih.gov/bioproject/PRJEB33490 练手
来自于文章;https://www.tandfonline.com/doi/full/10.1080/2162402X.2019.1644110
后面我们会带领大家完成这个练手数据的全部分析!争取制作成为视频教程,免费上传到b站哈,感谢支持了我六年的生信技能树全体粉丝!文末友情宣传
强烈建议你推荐我们生信技能树给身边的博士后以及年轻生物学PI,帮助他们多一点数据认知,让科研更上一个台阶:
- 生信爆款入门-全球听(买一得五)(第4期),你的生物信息学入门课
- 数据挖掘第2期(两天变三周,实力加量),医学生/临床医师首选技能提高课
- 生信技能树的2019年终总结 ,你的生物信息学成长宝藏
- 2020学习主旋律,B站74小时免费教学视频为你领路,还等什么,看啊!!!