看到数据集 GSE103115,是关于:Cisplatin-induced gene expression changes in triple-negative breast cancer (TNBC) cells,是4种三阴性乳腺癌细胞系的同一个药物的不同时间的转录表达水平效应,每个处理是2个生物学重复。这个数据集发表在Cell Rep. 2019 Aug ,题目是:Modeling of Cisplatin-Induced Signaling Dynamics in Triple-Negative Breast Cancer Cells Reveals Mediators of Sensitivity. 分析策略的确是蛮有意思的。
The complete signaling dataset for four TNBC cell lines following 2 or 20 mM cisplatin treatment. Each box represents an 11-point time course of biological duplicate experiments.
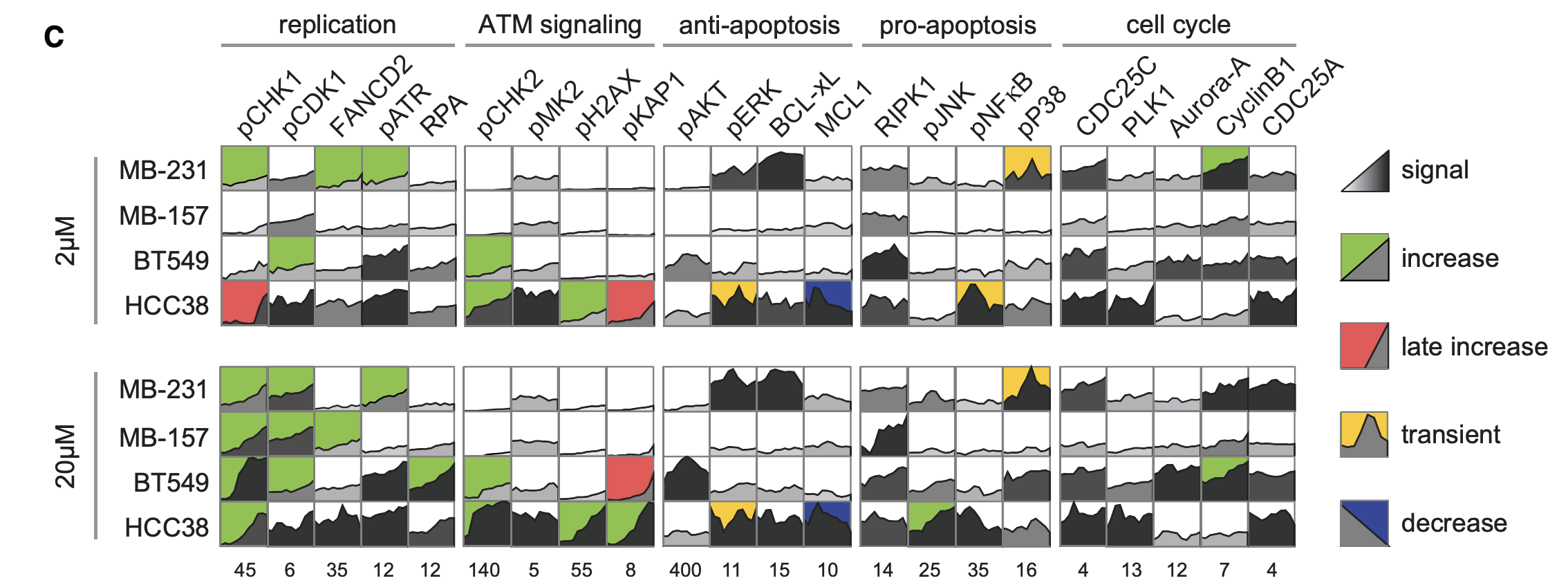
Grayscale reflects signal strength. Background color indicates signaling profile: sustained increase in green, late increase in red, transient increase in yellow, and sustained decrease in blue, as explained in the STAR Methods section. Numbers below each plot report the maximum FLD on the y axis.
使用的是Illumina HumanHT-12 V4.0 expression beadchip芯片,共24个样本,也就是4X3X2=24 ,其中4个细胞系和3个时间点分别是:
Four triple-negative breast cancer cell lines, MDA-MB-231, MDA-MB-157, BT549 and HCC38, were treated with 2 µM cisplatin for 0, 24 or 72 hours. Two independent replicates were collected for each cell line.
大家发现这个数据集分析策略跟我们以前介绍的就很不一样,以前是走标准分析流程,火山图,热图,GO/KEGG数据库注释等等。这些流程的视频教程都在B站和GitHub了,目录如下:
- 第一讲:GEO,表达芯片与R
- 第二讲:从GEO下载数据得到表达量矩阵
- 第三讲:对表达量矩阵用GSEA软件做分析
- 第四讲:根据分组信息做差异分析
- 第五讲:对差异基因结果做GO/KEGG超几何分布检验富集分析
- 第六讲:指定基因分组boxplot指定基因list画热图
感兴趣可以细读表达芯片的公共数据库挖掘系列推文 ;- 解读GEO数据存放规律及下载,一文就够
- 解读SRA数据库规律一文就够
- 从GEO数据库下载得到表达矩阵 一文就够
- GSEA分析一文就够(单机版+R语言版)
- 根据分组信息做差异分析- 这个一文不够的
- 差异分析得到的结果注释一文就够
也就是说,两个组别,进行比较即可,而现在这个数据集,有24个样本,是4X3X2=24 ,其中4个细胞系和3个时间点。如果是两两对比,至少可以是8次差异分析,每个细胞系的24和72小时处理都需要与0小时进行差异分析,拿到上下调基因!
这里给大家学徒作业,做这8次差异分析,拿到上下调基因,然后上下调基因分开,绘制upsetR这个高级韦恩图,还有8个基因集合并起来绘制GO-KEGG富集分析图表,看起来工作量大, 但是这个分析很有意义,希望你能完成!尤其是凉皮同学我相信你肯定可以!如果你觉得多次差异分析很麻烦
也可以试试看WGCNA,样本数量要求是绝对足够了,这个时候,你的细胞系的不同种类,时间上不同处理,都是你想性状,是用来跟WGCNA得到模块进行关联解释的。我在生信技能树多次写教程分享WGCNA的实战细节:
- 一文看懂WGCNA 分析(2019更新版)
- 通过WGCNA作者的测试数据来学习
- 重复一篇WGCNA分析的文章(代码版)
- 重复一篇WGCNA分析的文章(解读版)(逆向收费读文献2019-19)
再给大家一个学徒作业,对这个表达矩阵,工具mad值排序后,取top5000或者top10000走WGCNA划分为模块,看看跟细胞系的不同种类,时间上不同处理相关的模块,是不是跟前面的8次独立的差异分析,拿到的基因集的生物学功能是有类似的?还可以增加变量,比如不同药物
这个时候的典型数据集是:https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE116436 总共是
60X15X3X3数据,细胞系的数量很可观啦,NCI-60大名鼎鼎了,药物就包括常见的15种抗癌药物了,也有不同浓度,还有不同时间。更丰富多彩的实验设计意味着更精彩的分析,简简单单差异分析和wgcna都无法满足CNS级别的要求啦!
Drug-induced change in gene expression across NCI-60 cell lines after exposure to 15 anticancer agents for 2, 6 and 24h (cisplatin)GSM3231820 MCF7_5-Azacytidine_0nM_24h GSM3231821 MCF7_5-Azacytidine_0nM_2h GSM3231822 MCF7_5-Azacytidine_0nM_6h GSM3231823 MCF7_5-Azacytidine_1000nM_24h GSM3231824 MCF7_5-Azacytidine_1000nM_2h GSM3231825 MCF7_5-Azacytidine_1000nM_6h GSM3231826 MCF7_5-Azacytidine_5000nM_24h GSM3231827 MCF7_5-Azacytidine_5000nM_2h GSM3231828 MCF7_5-Azacytidine_5000nM_6h如果你感兴趣里面的分析策略,可以自行阅读发表这个数据集的文章咯。文章是:A Tool to Examine Dynamic Expression Profiling of Therapeutic Response in the NCI-60 Cell Line Panel. Cancer Res 2018 Dec 15;78(24):6807-6817. PMID: 30355619
当然了,单变量才是主流
虽然前面我们介绍了如此的复杂的实验设计,但真实的科研大军都是控制变量法来设计课题,也就是我们的2个分组的标准流程啦,处理组与对照组。
比如发表于 FEBS J. 2016 Dec ,文章是:Gene expression from MDA-MB-231 cells shControl and shLOXL2.
数据集是: https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE35600,很简单的,2个分组,每个分组都是标准的3个生物学重复!GSM871399 LOXL2 1 GSM871400 LOXL2 2 GSM871401 LOXL2 3 GSM871402 SCHT control 1 GSM871403 SCHT control 2 GSM871404 SCHT control 3但是文章作者的数据分析结果图表展现,我是真的无法恭维。
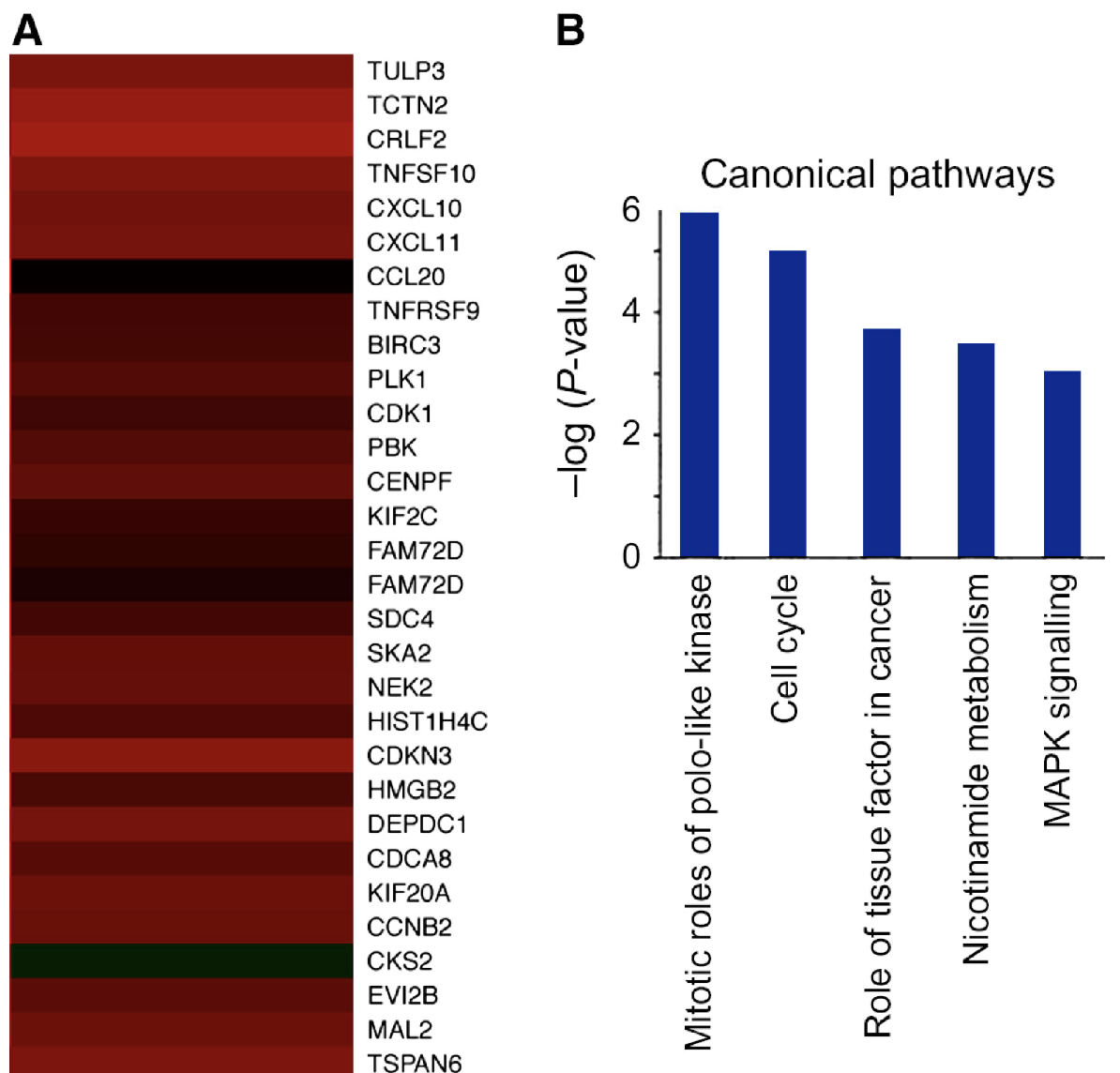
Transcription expression profile in MDA‐MB‐231 cells.- (A) Representative heat map of gene expression changes in shLOXL2 relative to shControl. The up‐regulated genes are in red (32 of 411); down‐regulated genes in green (21 of 312); and closed to the average genes in black.
- (B) Ingenuity Pathway Analysis (IPA) of canonical pathways and functions for differentially expressed genes in LOXL2 knockdown. Significance refers to the −log (P‐value), which was obtained by the ingenuity program using a right‐tailed Fisher’s exact test.
我相信你也应该是猜到了我的学徒作业啦,就是对数据集GSE35600走我的标准分析代码,看看时隔8年后你的分析结果,是否跟这个数据集发表时候的文章的结论一致呢?
这次有3个学徒作业,所以送一个福利
如果你有感兴趣的数据需要分析,表达矩阵相关的,我可以免费给你分析哈!
发送数据集链接或者表达矩阵,以及简短的项目描述到我的邮箱:jmzeng1314@163.com
加上你是啥时候认识生信技能树的哦,或者其它一些寒暄的话,自我介绍也行。主要是考虑到可能想免费分析数据的朋友很多,所以会根据你的来信,我主观判定一个优先级哦。
如果你需要单细胞转录组数据免费分析,请看:根据感兴趣基因看肝癌免疫微环境的T细胞亚群差异
目前我有20多个学徒,等我的团队扩大到200人,我们应该是可以做到数据分析全部免费,敬请期待哈!