还记得当初在微信公众号已经成为了一片红海的时候,我们生信技能树由论坛和博客这样过时的互联网形态转型杀进来微信公众号自媒体战场,当时奋斗的非常辛苦,虽然现在已经成为生物信息学领域当之无愧的流量当担。
其中有一件事值得回忆一下,也想借此机会组建新的学习小组开启新的TCGA数据库挖掘之旅,学习小组在文末!
忆苦思甜
不过,忆苦思甜嘛,当初涨粉最多的就是:标准TCGA大文章需要哪些数据?[赠重磅资料] 在公众号粉丝数量不足一千的时候,居然取得了阅读量近万的佳绩!
当时写的是https://tcga-data.nci.nih.gov/docs/publications/ (本人已经写爬虫把所有TCGA在CNS的大文章的PDF及附件全部下载,请后台回复TCGA大文章获取!) 实际上呢,这个关键词现在仍然是有效的哦!
还有TCGA历年研讨会的全部资料!
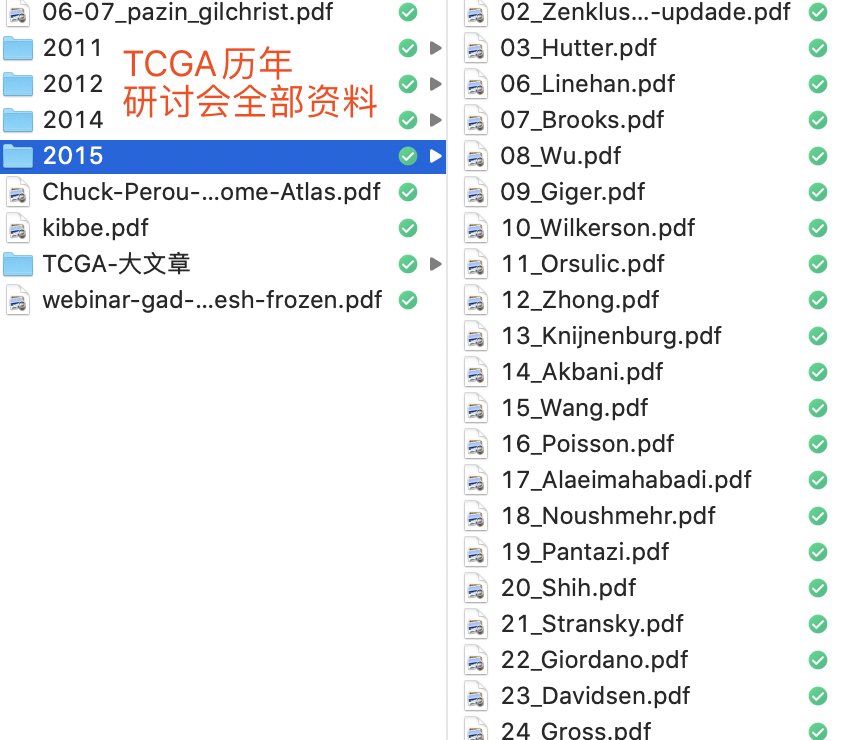
https://www.cancer.gov/about-nci/organization/ccg/research/structural-genomics/tcga/publications
全部文章都给到大家了,就是不知道大家学习的效果如何?有没有通过解读TCGA系列文章来获得生物信息学数据处理的认知呢?
关于TCGA数据库
众所周知,TCGA数据库是目前最综合最全面的癌症病人相关组学数据库,包括:
- DNA Sequencing
- miRNA Sequencing
- Protein Expression array
- mRNA Sequencing
- Total RNA Sequencing
- Array-based Expression
- DNA Methylation
- Copy Number array
知名的肿瘤研究机构都有着自己的TCGA数据库探索工具,比如:
- Broad Institute FireBrowse portal, The Broad Institute
- cBioPortal for Cancer Genomics, Memorial Sloan-Kettering Cancer Center
所以我挑选了部分,写了6个数据下载系列教程:
- TCGA的28篇教程- 使用R语言的cgdsr包获取TCGA数据(cBioPortal)
- TCGA的28篇教程- 使用R语言的RTCGA包获取TCGA数据 (离线打包版本)
- TCGA的28篇教程-使用R语言的RTCGAToolbox包获取TCGA数据(FireBrowse portal)
- TCGA的28篇教程- 批量下载TCGA所有数据 ( UCSC的 XENA)
- TCGA的28篇教程-数据下载就到此为止吧
- TCGA的28篇教程-整理GDC下载的xml格式的临床资料
虽然说,教程是关于TCGA数据库的不同数据的下载,实际上是希望可以帮助大家认识TCGA数据库的全貌,然后根据大家的提问,我也扩充了部分常见的TCGA数据库用法:
- TCGA的28篇教程-免疫全景图
- TCGA的28篇教程-指定癌症查看感兴趣基因的表达量
- TCGA的28篇教程-对TCGA数据库的任意癌症中任意基因做生存分析
- TCGA的28篇教程-风险因子关联图-一个价值1000但是迟到的答案
- TCGA的28篇教程-数据挖掘三板斧之ceRNA
- TCGA的28篇教程-所有癌症的突变全景图
- TCGA的28篇教程-早期泛癌研究
- TCGA的28篇教程-CNV全攻略
- TCGA的28篇教程-GTEx数据库-TCGA数据挖掘的好帮手
还有泛癌系列解读
- 100篇泛癌研究文献解读之APOBECs家族基因突变及表达量异常
- 100篇泛癌研究文献解读之癌症相关基因的饱和度分析
- 100篇泛癌研究文献解读之肿瘤病人新的分类方法
- 100篇泛癌研究文献解读之突变全景图
- 100篇泛癌研究文献解读之根据点突变和拷贝数变异共同分组
- 100篇泛癌研究文献解读之泛癌拷贝数变异情况探索
- 100篇泛癌研究文献解读之可变剪切事件大起底
- 100篇泛癌研究文献解读之snoRNAs
- 100篇泛癌研究文献解读之病毒感染及整合到肿瘤病人基因里
- 100篇泛癌研究文献解读之PhyloWGS算法的肿瘤内部异质性和基因组不稳定性
- 100篇泛癌研究文献解读之生存分析相关基因
- 100篇泛癌研究文献解读之lincRNA的生存分析情况
- 100篇泛癌研究文献解读之驱动lncRNA
- 100篇泛癌研究文献解读之合成致死事件
- 100篇泛癌研究文献解读之原位癌症和转移癌症的区别
- 100篇泛癌研究文献解读之微卫星不稳定性
- 100篇泛癌研究文献解读之APOBECs家族基因突变及表达量异常
- 100篇泛癌研究文献解读之同源重组修复通路
- 100篇泛癌研究文献解读之磷酸化相关点突变
- 100篇泛癌研究文献解读之激酶相关基因融合事件
- 100篇泛癌研究文献解读之使用EXPANDS和PyClone量化肿瘤内部异质性
- 100篇泛癌研究文献解读之核受体基因家族探索
- 100篇泛癌研究文献解读之上皮细胞-间充质细胞转化
- 100篇泛癌研究文献解读之肿瘤免疫浸润情况
- 100篇泛癌研究文献解读之ESTIMATE算法计算肿瘤纯度
如果这些资料你都没有看也没有学,那么你可能
新的学习小组
其实是年初我举行的肿瘤认知升级训练营,但是当初筛选标准太严格,而且确实没有让我眼前一亮的值得大力培养的后辈出现,所以就搁置了。
当时还设置了5个考核任务,希望调动大家主动学习的积极性,可是并没有设置好的跟踪反馈检查机制,让我这样的大忙人来搞这么具体的事情实在是太难了!
但是肿瘤学研究,确实离不开TCGA数据库的认知,我还是希望更多的人参与学习!