上次GEO课程回答了学员问题:使用R语言在向量的任何位置插入任何元素 实力演示了如何自定义函数,这样大家就可以无限制创造方法来解决自己特殊的需求,课后一个月的答疑期,发现大家还是有各式各样的问题,比如下面的表型信息:

很明显,有些信息是冗余的,有些是有效信息可以用来分组,但是表型记录太多,看起来会混淆,所以需要去除那些冗余信息,就是在所有样本里面表型记录都一致的列。
然后我发现, 非常多的学员都无从下手,其实就是数据框取子集,我一直强调了3种方法,坐标、列名和逻辑判断,这个时候很明显应该是逻辑判断,就是看看每一列是否是冗余信息。我们来举一个例子,下面的代码创建一个模拟的表型信息;
pd=data.frame(1:10,4,7,3,'a','d',
LETTERS[1:10],letters[1:10],
c(rep('a',5),rep('b',5)))
如下所示,只有第1列和最后3列是有信息的,中间的列在所有行都是同一个元素,就是我们所认为的冗余信息,需要去除。
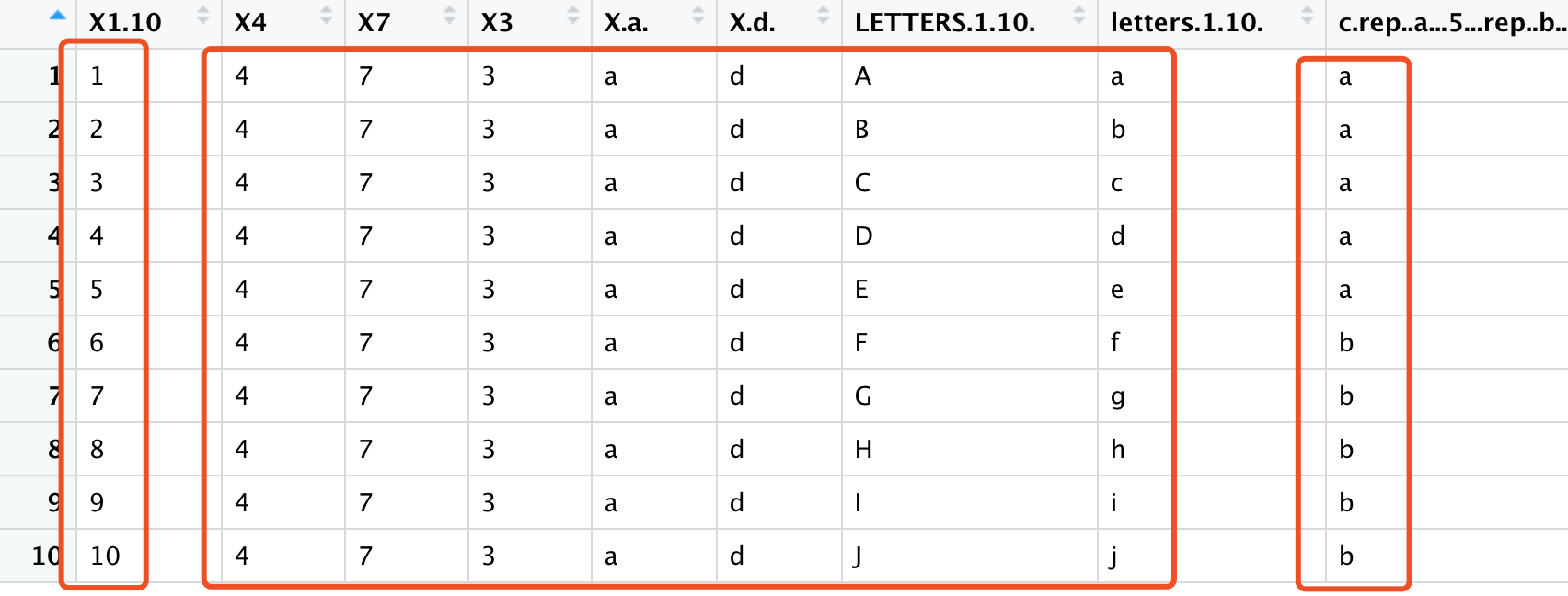
我们首先判断第一列非冗余元素的个数,下面的代码
length(unique(pd[,1]))
然后对每一列都使用同样的代码,那就是apply技巧:
apply(pd, 2, function(x){
length(unique(x))
})
这个时候里面的x就是每一列。
这样虽然是判断了每一列的非冗余元素个数,但并不是逻辑值,没办法去用来对数据框取子集。
需要加上一个判断,就是元素个数大于一才保留;
apply(pd, 2, function(x){
length(unique(x)) > 1
})
现在就是依据每一列返回一个逻辑值,这个逻辑值就可以去原始数据框里面进行取子集操作;
pd[,apply(pd, 2, function(x){
length(unique(x))>1
})
]
是不是很简单!
再次强调3种方法数据框里面进行取子集操作,坐标、列名和逻辑判断,其中逻辑判断是最常见的。