Lecture4_my-script-with-R_dplyr
Jimmy(jmzeng1314@outlook.com)
Keywords: dplyr
dplyr: A Grammar of Data Manipulation
A fast, consistent tool for working with data frame like
objects, both in memory and out of memory.
|
Version: |
0.4.3 |
|
Depends: |
R
(≥ 3.1.2) |
Warning in
install.packages :
package ‘dplyr’ is not available (for R
version 3.1.0)
useful links : https://cran.r-project.org/web/packages/dplyr/
https://cran.r-project.org/web/packages/dplyr/dplyr.pdf
www.bio-info-trainee.com/?p=1071
http://www.dataguru.cn/thread-311303-1-1.html
Dplyr包学习笔记
一,需要用到的数据集
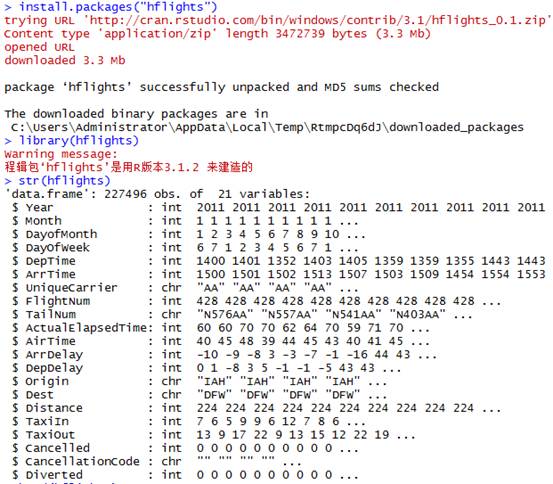
这个航空数据资料集包含的变量和观测值太多
hflights_df
<- tbl_df(hflights)
第一个函数tbl_df 使得大数据集规范显示出来,行列都只显示10个,跟head差不多,但是head只能控制行,无法控制列,感觉意义不是很大,就是为了防止数据刷屏。
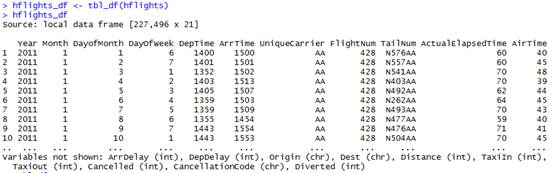
1 基本操作
把常用的数据操作行为归纳为以下五种:
1.1 筛选: filter()
filter(hflights_df,
Month == 1, DayofMonth == 1)
用R自带函数实现:但是不够简洁
hflights[hflights$Month
== 1 & hflights$DayofMonth == 1, ]
除了代码简洁外, 还支持对同一对象的任意个条件组合, 如:
filter(hflights_df,
Month == 1 | Month == 2)
注意: 表示 AND 时要使用 & 而避免 &&
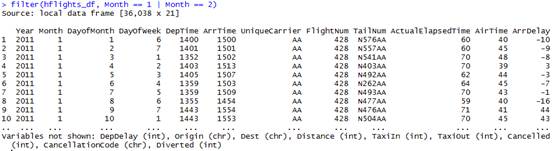
可以看出根据month这个变量我们从20多万的观测值里面挑选到了36038个,继续用hflights_df,可以保证挑选之后不会被这3万多个数据刷屏。
1.2 排列: arrange()
按给定的列名依次对行进行排序.
例如:
arrange(hflights_df, DayofMonth, Month, Year)
对列名加 desc() 进行倒序:
arrange(hflights_df, desc(ArrDelay))
这个函数和 plyr::arrange() 是一样的, 类似于 order()
用R自带函数实现:
hflights[order(hflights$DayofMonth,
hflights$Month, hflights$Year), ]
hflights[order(desc(hflights$ArrDelay)), ]
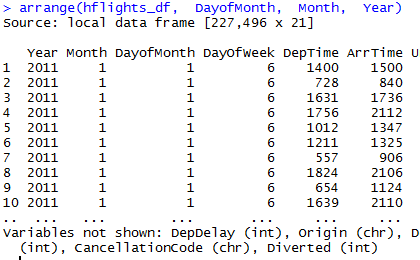
这样就把20多万的观测值按照时间顺序排列好了
1.3 选择: select()
用列名作参数来选择子数据集:
select(hflights_df,
Year, Month, DayOfWeek)
还可以用 : 来连接列名, 没错, 就是把列名当作数字一样使用:
select(hflights_df,
Year:DayOfWeek),表示从Year这一列到DayOfWeek这一列之间都选择
用 - 来排除列名:
select(hflights_df,
-(Year:DayOfWeek))
同样类似于R自带的 subset() 函数 (但不用再写一长串的 c("colname1", "colname2") 或者 which(colname(data) == "colname3"), 甚至还要去查找列号)

还有slice函数是对行进行选择,不过意义不是很大,以下命令选择前三行数据
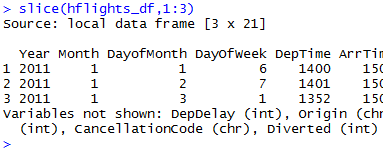
当然select还可以对选择的列进行改名
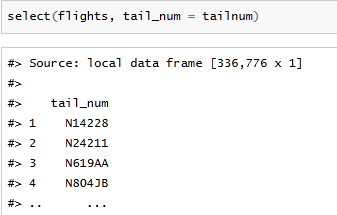
但如果仅仅是需要改名的话,用rename()即可
rename(flights,
tail_num = tailnum)这样会返回所有数据,只是被选择的这一列改名了,不过意义不大, 可以直接对names()进行赋值达到同样的目的
还可以对选择的列进行去冗余
Extract
distinct (unique) rows
distinct(select(flights, tailnum))distinct(select(flights, origin, dest))
(This is
very similar to base::unique() but should be much faster.)
1.4 变形: mutate()
对已有列进行数据运算并添加为新列:
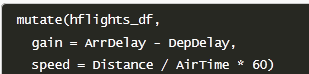
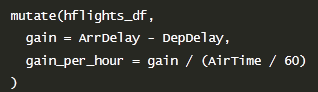
作用与 plyr::mutate() 相同, 与 base::transform() 相似, 优势在于可以在同一语句中对刚增加的列进行操作:,把临时增加的列也可以当做变量来操作,而在transform里面不行。
dplyr::mutate()
works the same way as plyr::mutate() and similarly to base::transform(). The
key difference between mutate() and transform() is that mutate allows you to
refer to columns that you just created:
1.5 汇总: summarise()
对数据框调用其它函数进行汇总操作, 返回一维的结果
![]()

2 分组动作 group_by()
以上5个动词函数已经很方便了, 但是当它们跟分组操作这个概念结合起来时, 那才叫真正的强大! 当对数据集通过 group_by() 添加了分组信息后,mutate(), arrange() 和 summarise() 函数会自动对这些 tbl 类数据执行分组操作 (R语言泛型函数的优势).
例如: 对飞机航班数据按飞机编号 (TailNum) 进行分组, 计算该飞机航班的次数 (count = n()), 平均飞行距离 (dist = mean(Distance, na.rm = TRUE)) 和 延时 (delay = mean(ArrDelay, na.rm = TRUE))
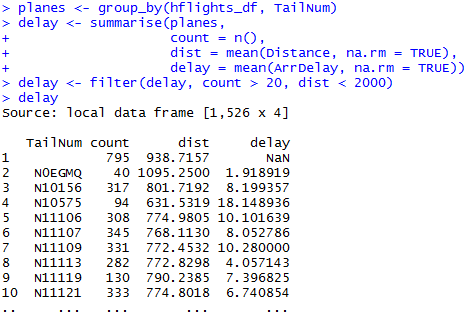
首先根据飞机编号分3320个飞机,然后对每个飞机都进行汇总,得出三个值,然后根据count和dist来过滤选取符合要求的飞机,还剩下1536个飞机
When you
group by multiple variables, each summary peels off one level of the grouping.
That makes it easy to progressively roll-up a dataset:
daily
<- group_by(flights, year, month, day)用年月日时间进行分组之后再逐步进行汇总求和
(per_day <- summarise(daily, flights =
n()))
(per_month
<- summarise(per_day, flights = sum(flights)))
(per_year <- summarise(per_month, flights =
sum(flights)))
However
you need to be careful when progressively rolling up summaries like this: it's
ok for sums and counts, but you need to think about weighting for means and
variances, and it's not possible to do exactly for medians.
3 连接符 %.%,又称管道
包里还新引进了一个操作符, 使用时把数据名作为开头, 然后依次对此数据进行多步操作.
比如:
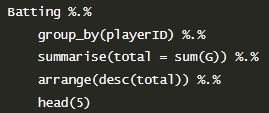

对这个数据集首先安装playerID来分组,然后进行分组计算G的总和,然后排序,然后输出前五个。
如果用R语言本身来实现就很难看,多重括号分不清楚内外区别
head(arrange(summarise(group_by(Batting,
playerID), total = sum(G)) , desc(total)), 5)
或者是多一对临时变量,拖慢运行速度
totals
<- aggregate(. ~ playerID,
data=Batting[,c("playerID","R")], sum)
ranks
<- sort.list(-totals$R)
totals[ranks[1:5],]
关于管道更加具体的例子
1,大量的临时变量

2,混乱的括号

3,真正的管道操作
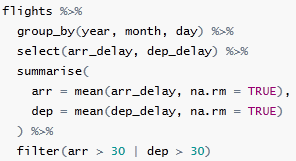
这样很方便看出哪个更实用。
数据分析有两个瓶颈,一是我们的目标是什么,二是我们如何用计算机去实现。我现有的很多作品,如 ggplot2,plyr 和 reshape2,更关注的是如何更简单地表达你的目标,而不是如何让计算机算得更快。
实现过程要以人脑的思维运作方式为标准, 让工具来适应人, 以实现目的为导向, ggplot2 的图形图层语法也是如此. 不管是软件也好, 编程语言也好, 高效的方法都是相通的, 这也正是许多人努力的方向, 另外平素语出惊人的王垠最近也表达了类似观点.
Dplyr还有很多其它的function
